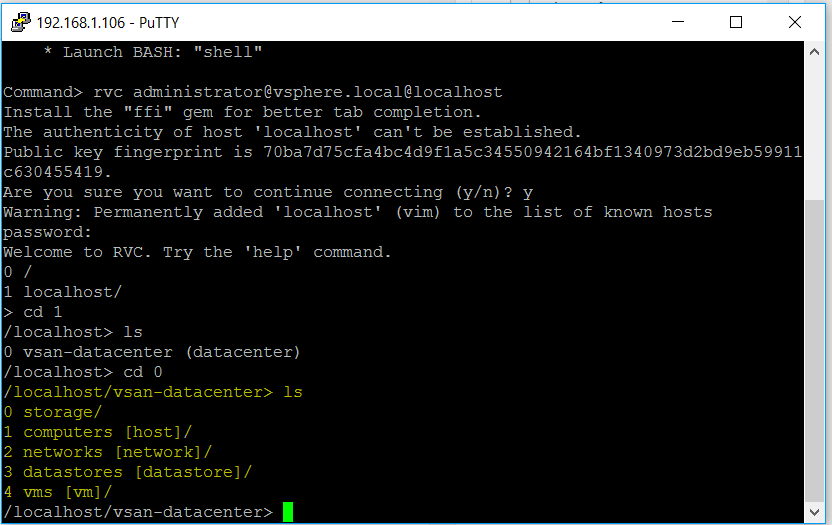
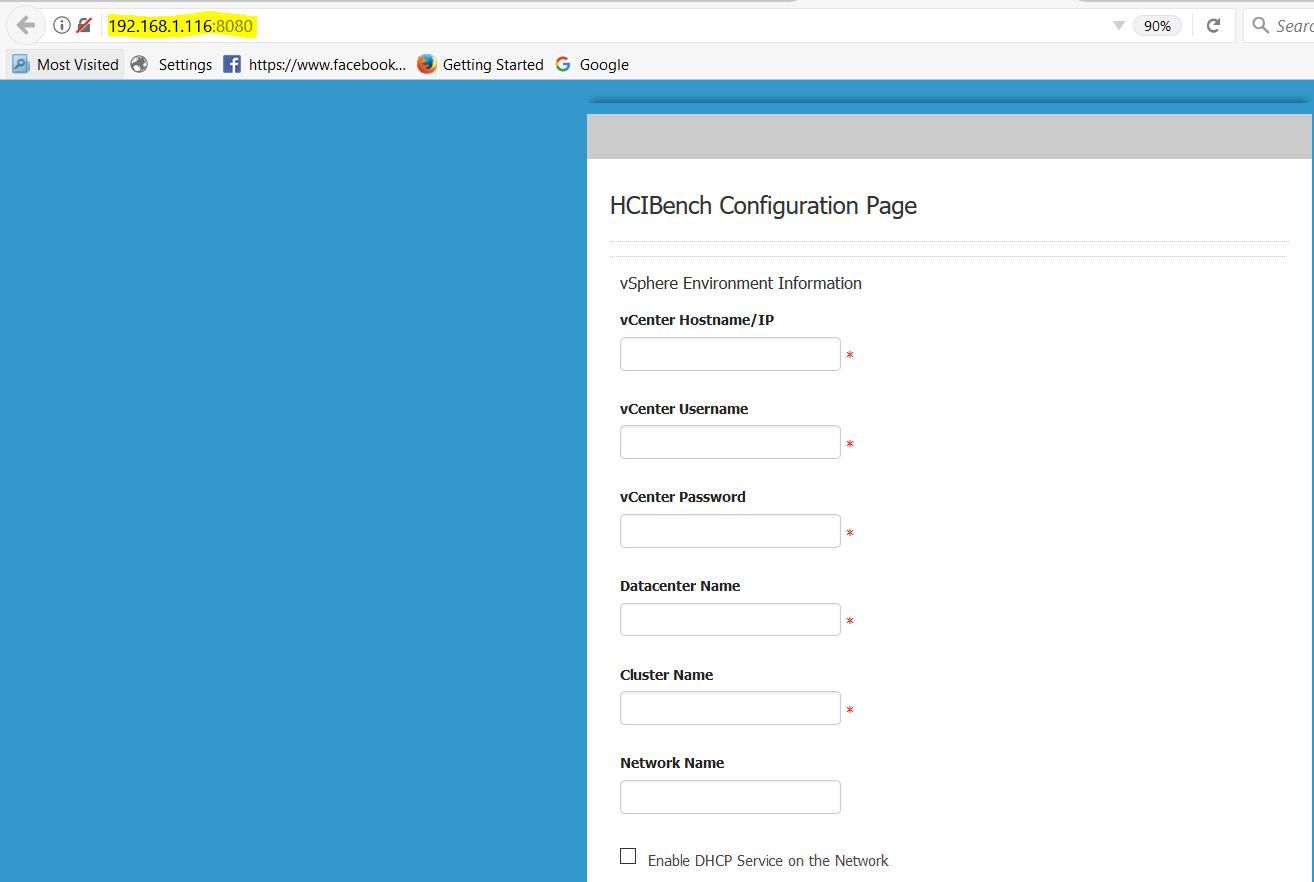
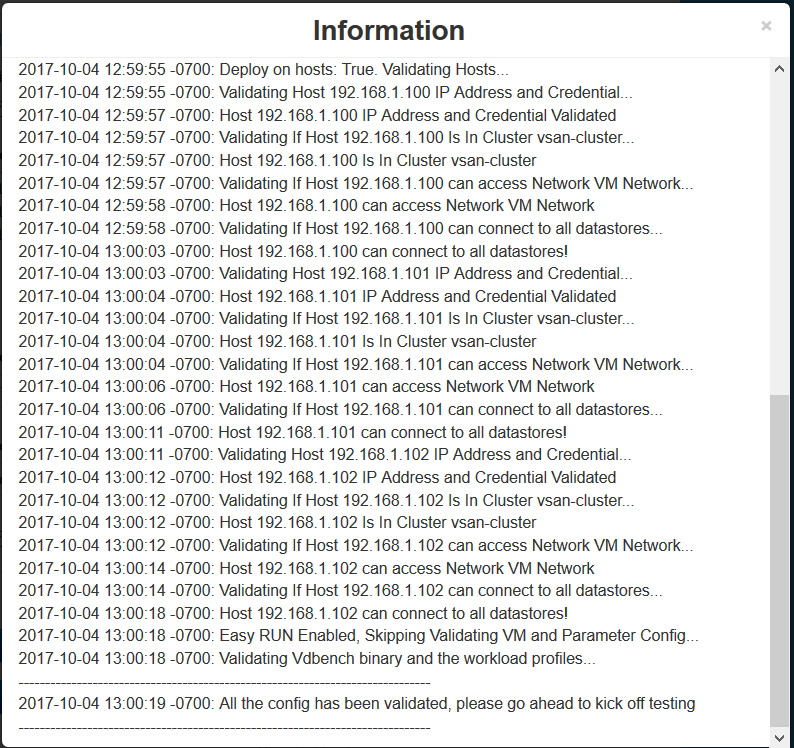
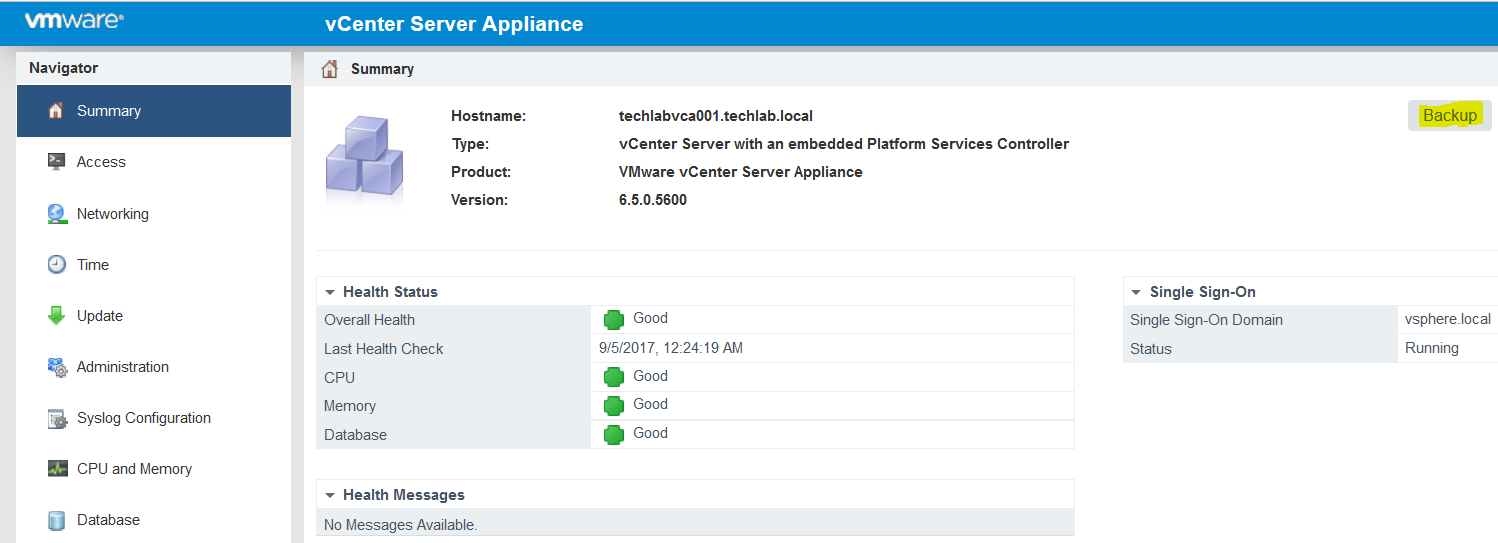
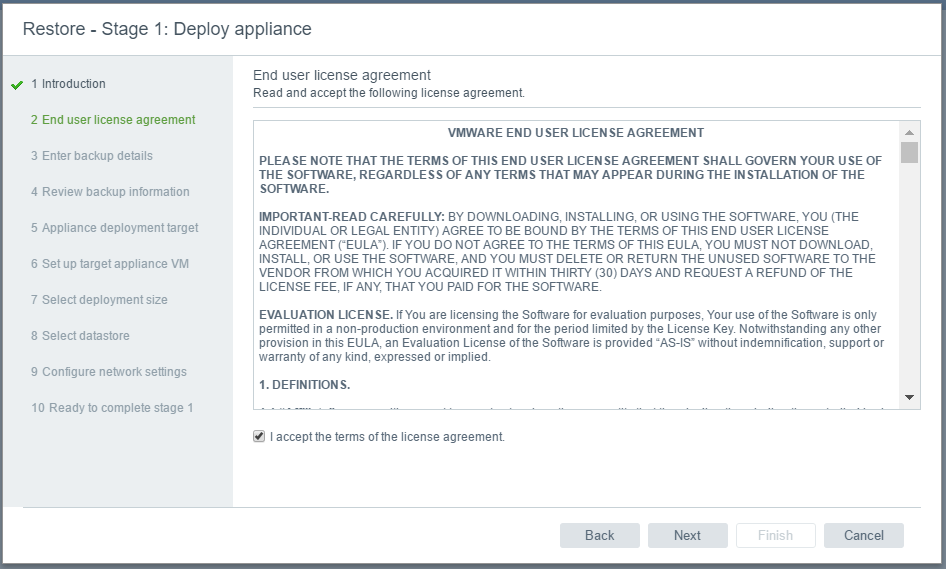
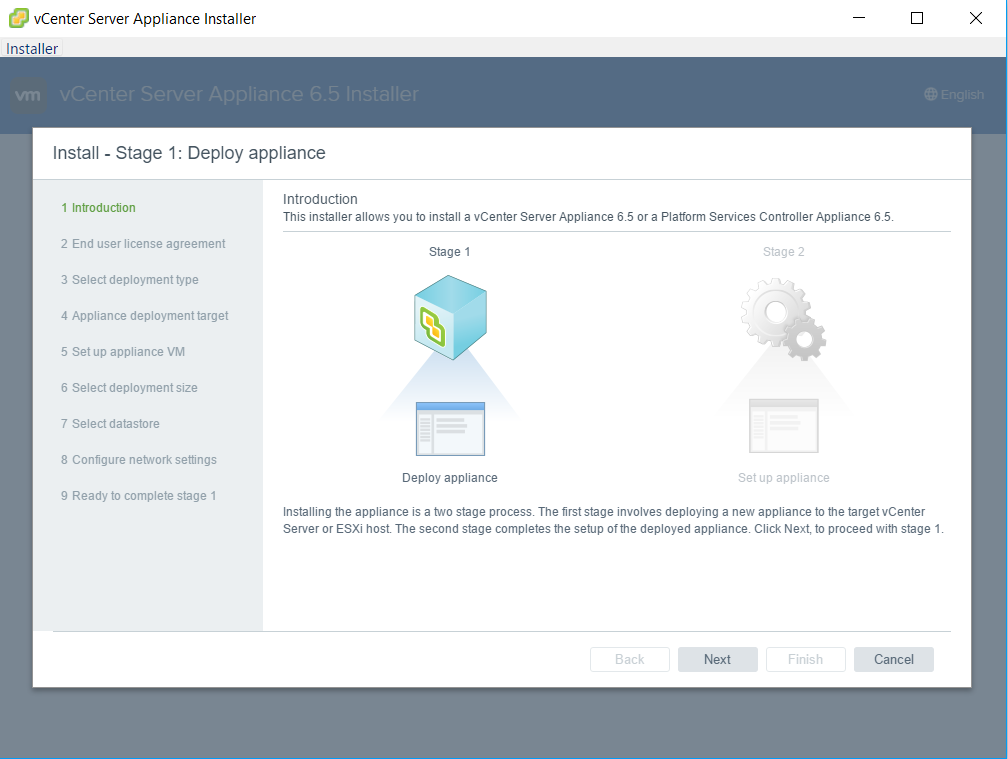
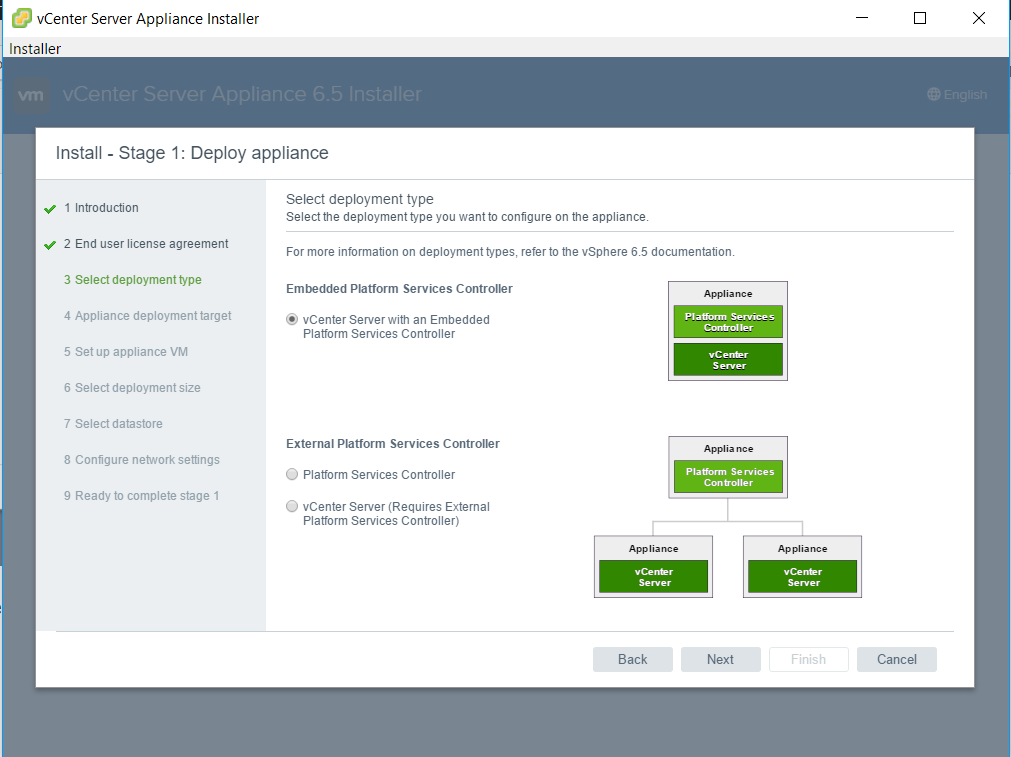
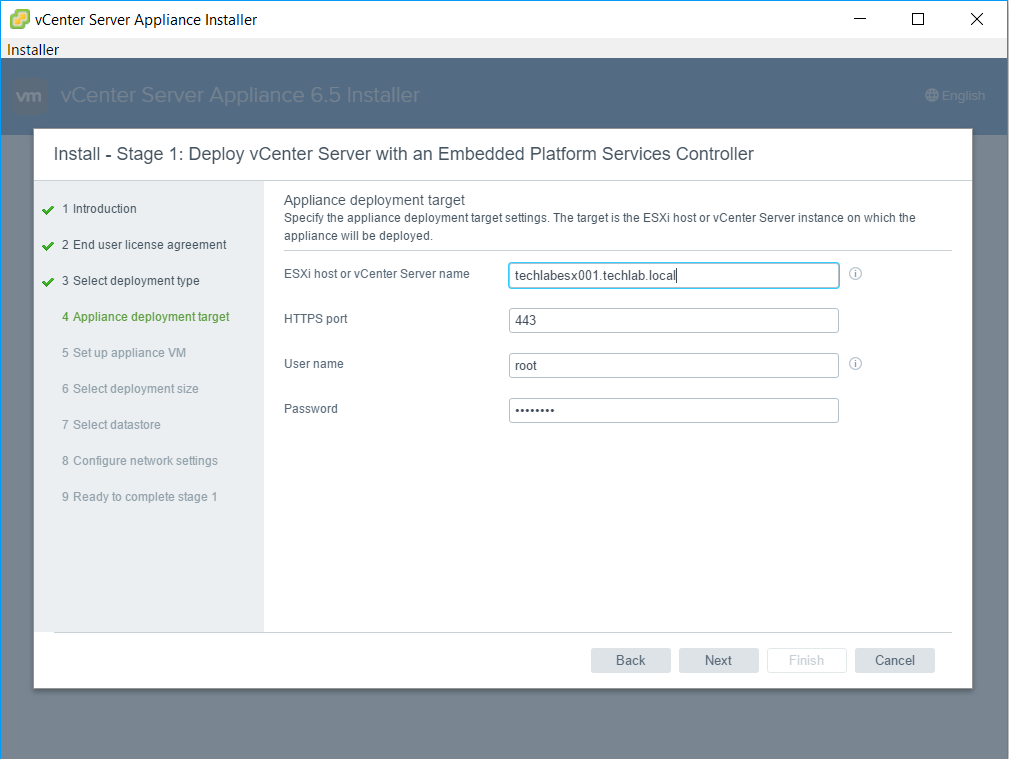
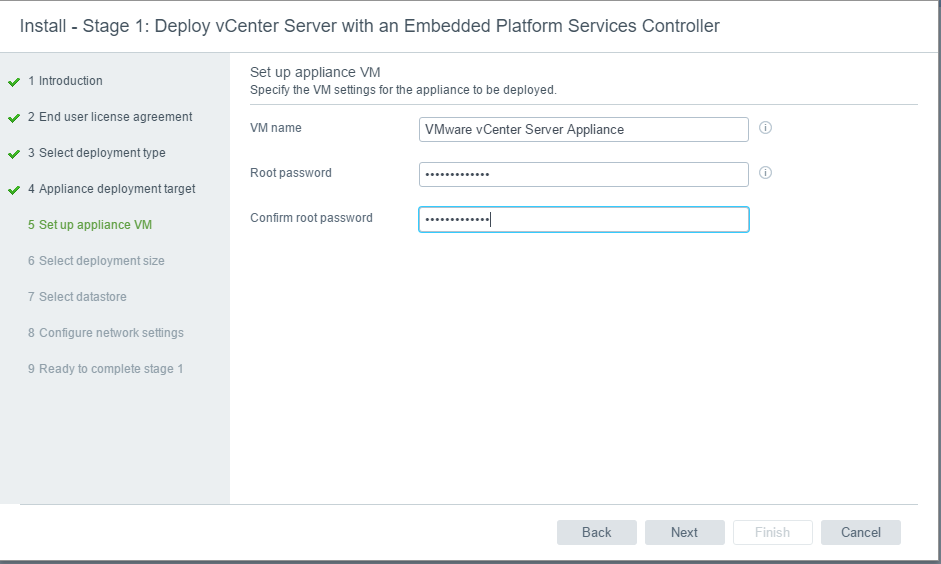
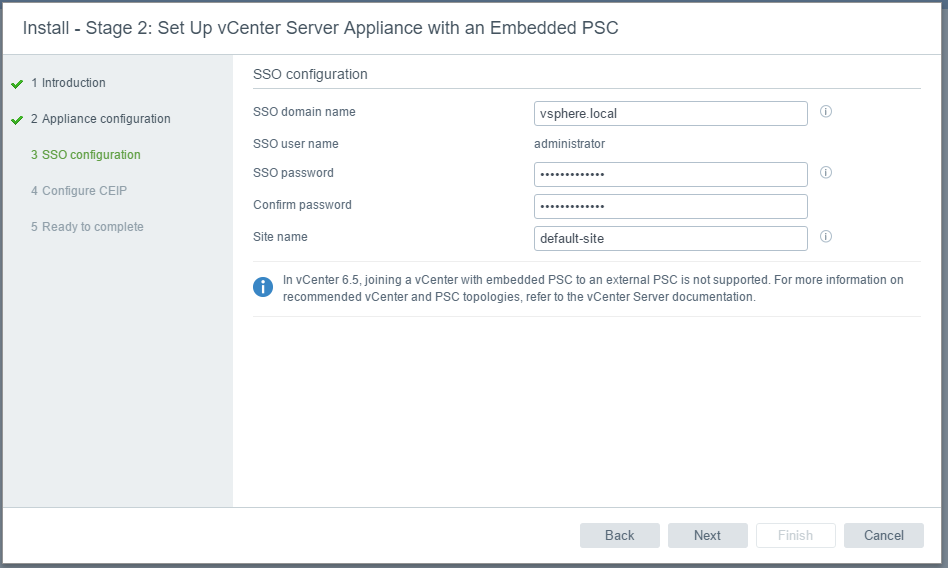
vSAN Stretched Cluster networking
A vSAN Stretched Cluster is a specific configuration implemented in environments where disaster/downtime avoidance is a key requirement. Setting up a stretched cluster can be daunting. More in terms of the networking side than anything else. This blog isn’t meant to be chapter and verse on vSAN stretched clusters. It is meant to help anyone who is setting up the networking, static routes and ports required for a L2 and L3 implementation.
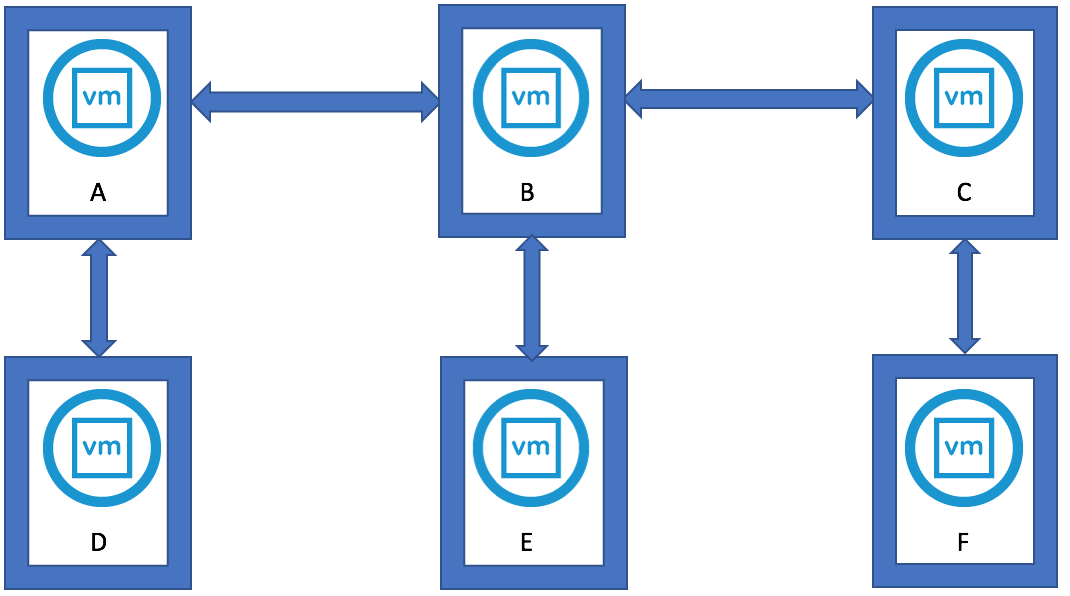
VMware vSAN Stretched Clusters with a Witness Host refers to a deployment where a user sets up a vSAN cluster with 2 active/active sites with an identical number of ESXi hosts distributed evenly between the two sites. The sites are connected via a high bandwidth/low latency link.
The third site hosting the vSAN Witness Host is connected to both of the active/active data-sites. This connectivity can be via low bandwidth/high latency links.
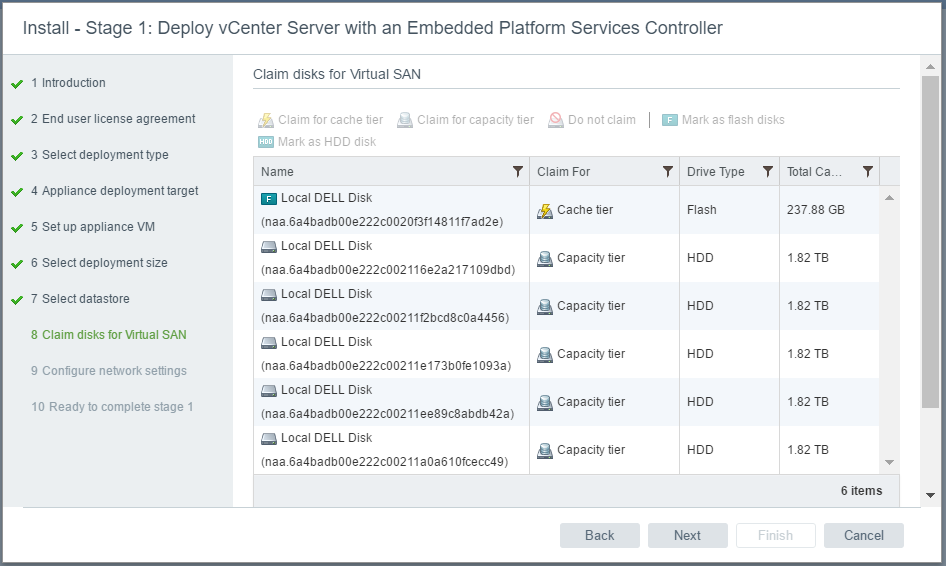
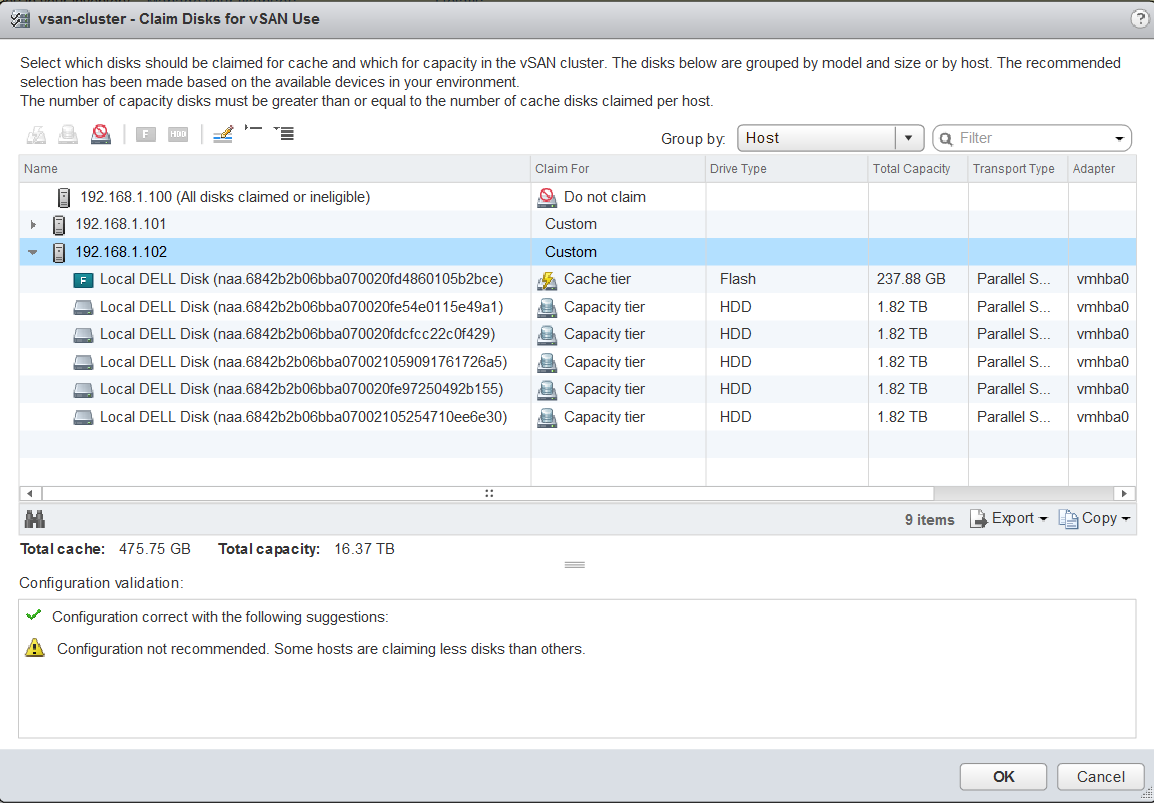
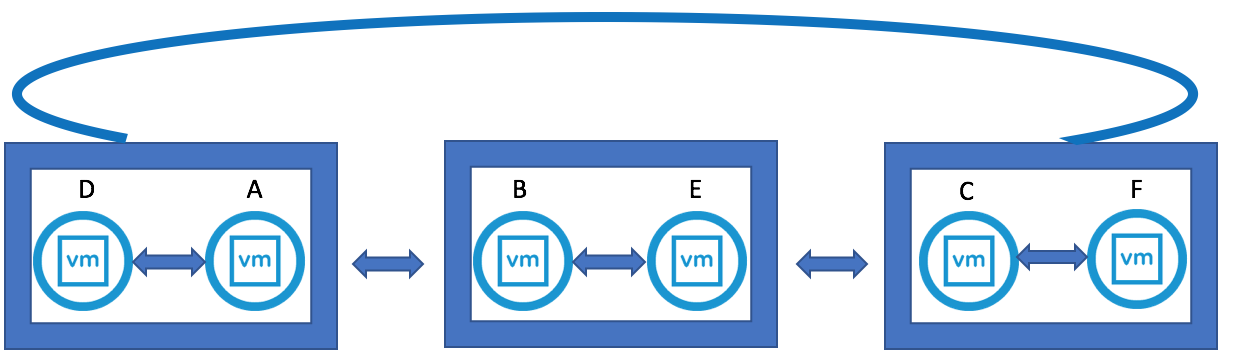
Each site is configured as a vSAN Fault Domain. The way to describe a vSAN Stretched Cluster configuration is X+Y+Z, where X is the number of ESXi hosts at data site A, Y is the number of ESXi hosts at data site B, and Z is the number of witness hosts at site C. Data sites are where virtual machines are deployed. The minimum supported configuration is 1+1+1(3 nodes). The maximum configuration is 15+15+1 (31 nodes). In vSAN Stretched Clusters, there is only one witness host in any configuration.
A virtual machine deployed on a vSAN Stretched Cluster will have one copy of its data on site A, a second copy of its data on site B and any witness components placed on the witness host in site C.
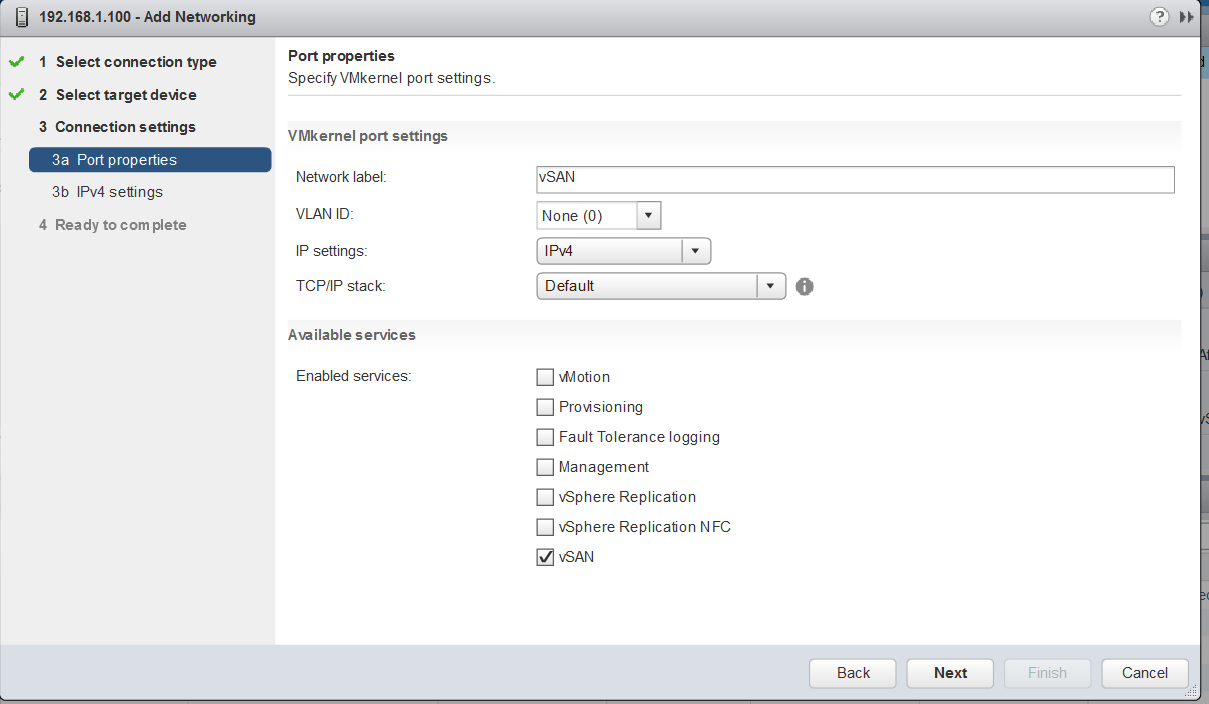
Types of networks
VMware recommends the following network types for Virtual SAN Stretched Cluster:
- Management network: L2 stretched or L3 (routed) between all sites. Either option should both work fine. The choice is left up to the customer.
- VM network: VMware recommends L2 stretched between data sites. In the event of a failure, the VMs will not require a new IP to work on the remote site
- vMotion network: L2 stretched or L3 (routed) between data sites should both work fine. The choice is left up to the customer.
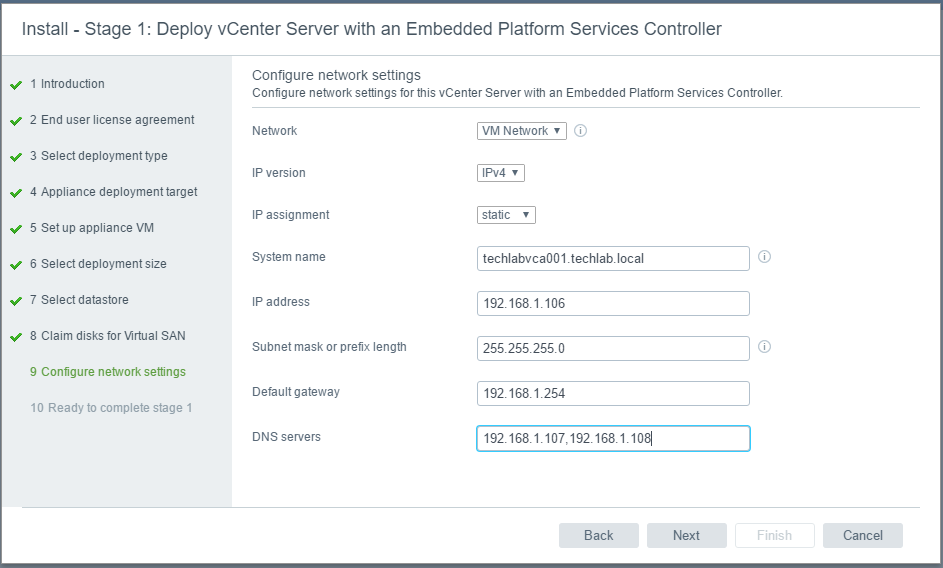
- Virtual SAN network: VMware recommends L2 stretched between the two data sites and L3 (routed) network between the data sites and the witness site.
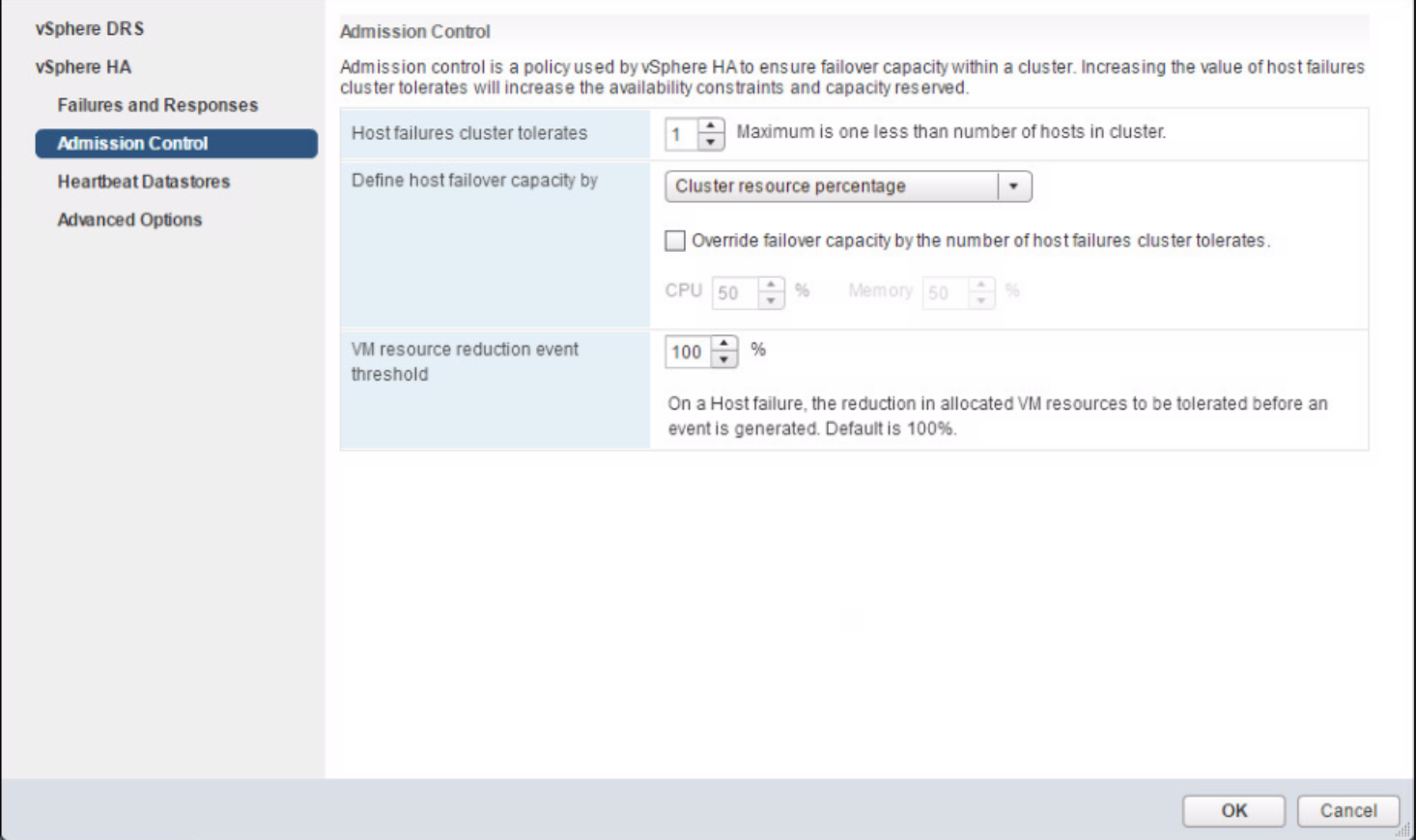
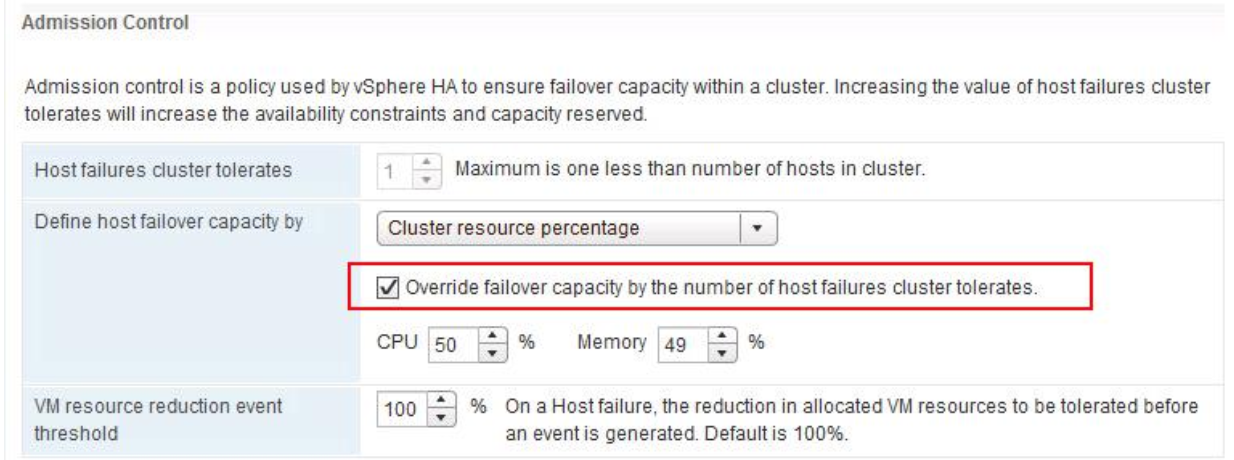
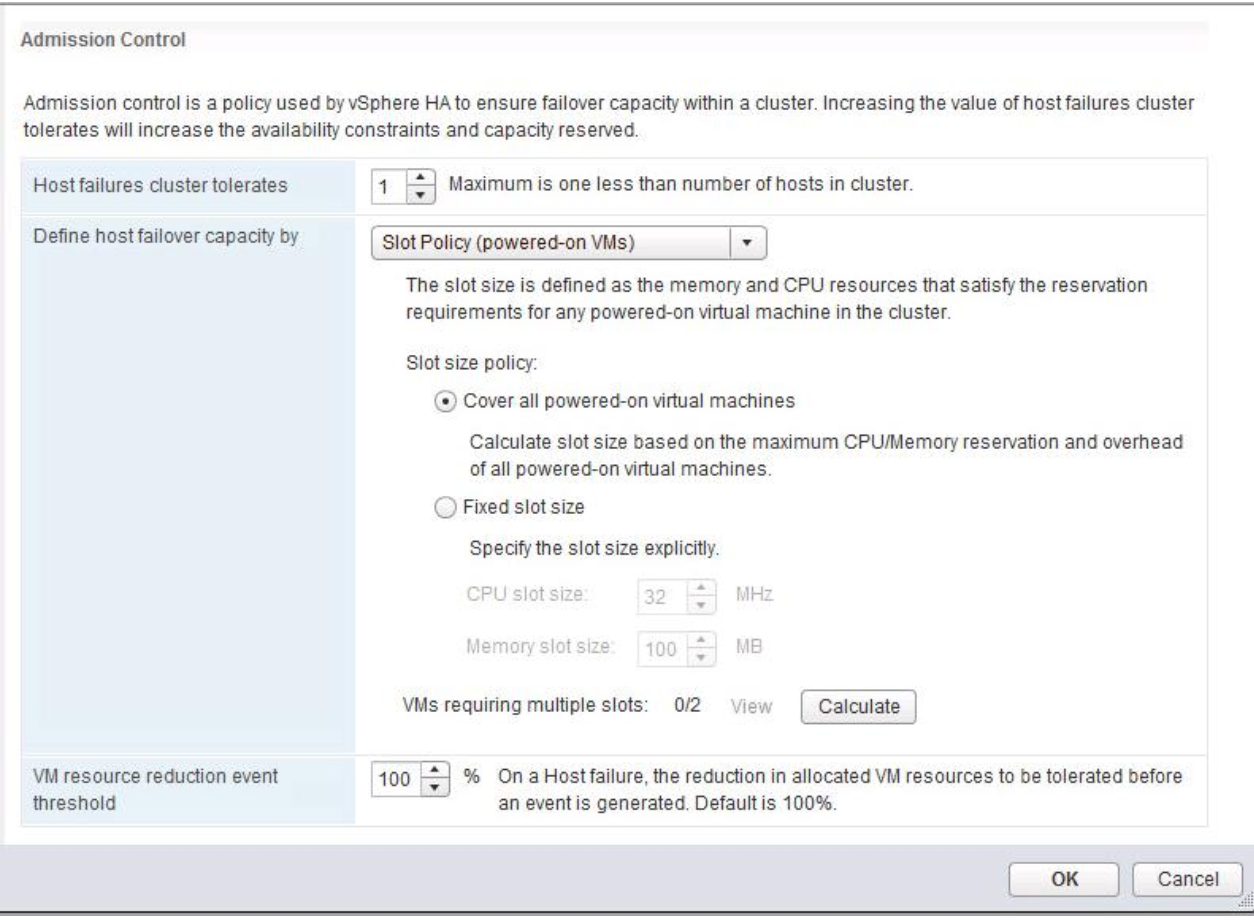
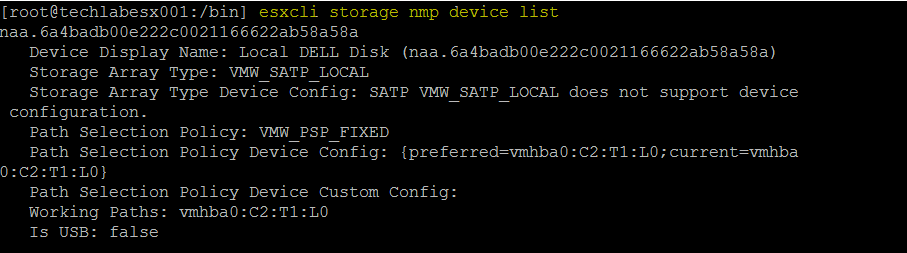
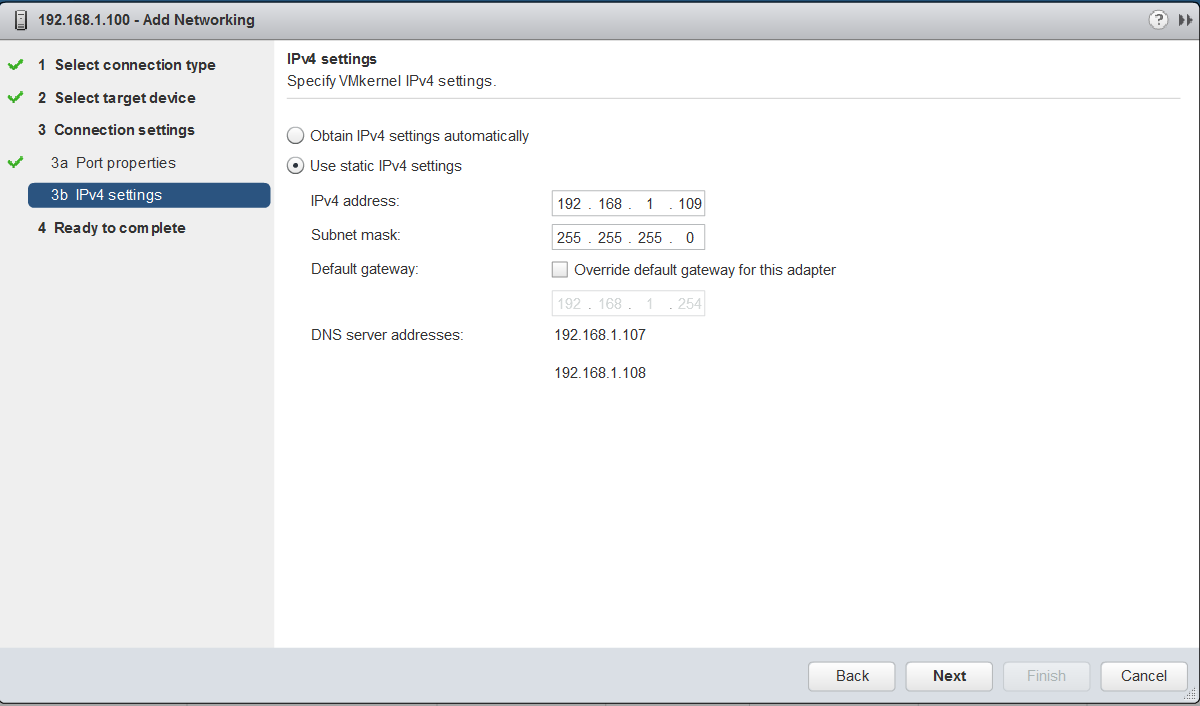
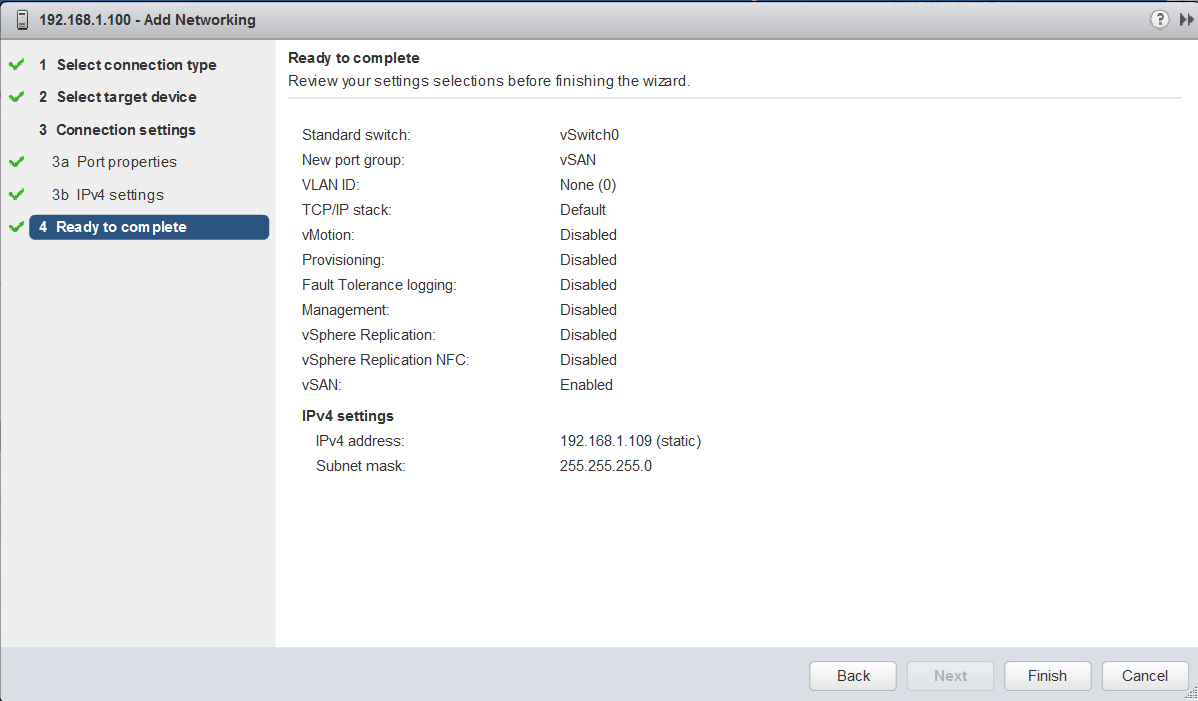
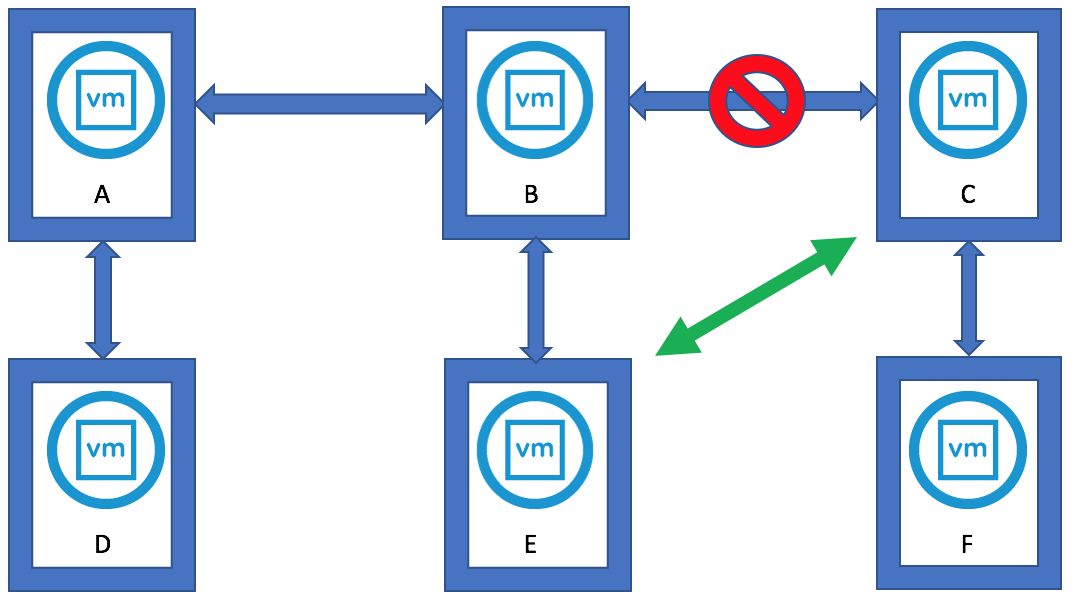
The major consideration when implementing this configuration is that each ESXi host comes with a default TCPIP stack, and as a result, only has a single default gateway. The default route is typically associated with the management network TCPIP stack. The solution to this issue is to use static routes. This allows an administrator to define a new routing entry indicating which path should be followed to reach a particular network. Static routes are needed between the data hosts and the witness host for the VSAN network, but they are not required for the data hosts on different sites to communicate to each other over the VSAN network. However, in the case of stretched clusters, it might also be necessary to add a static route from the vCenter server to reach the management network of the witness ESXi host if it is not routable, and similarly a static route may need to be added to the ESXi witness management network to reach the vCenter server. This is because the vCenter server will route all traffic via the default gateway.
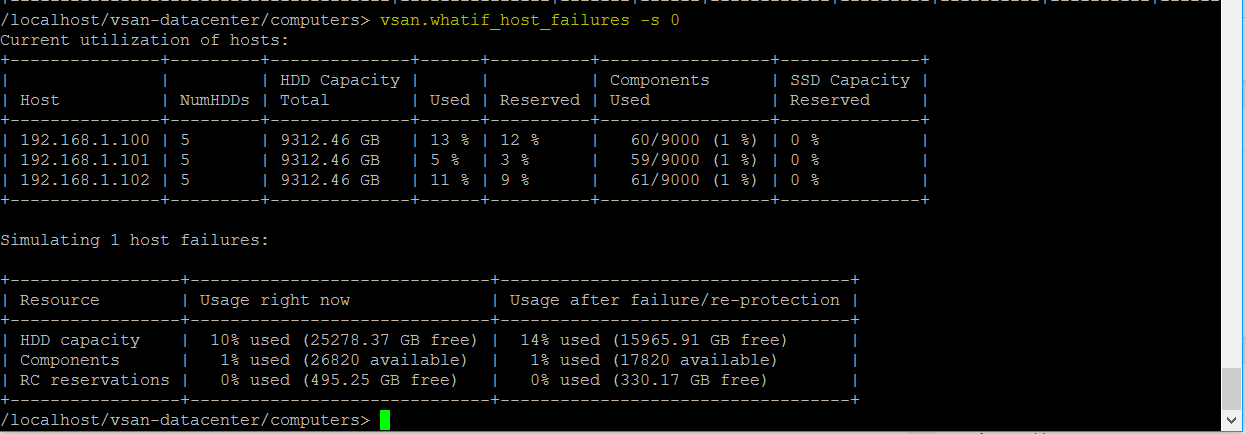
vSAN Stretched Cluster Visio diagram
The below diagram is for referring to and below this, the static routes are listed so it is clear what needs to connect.
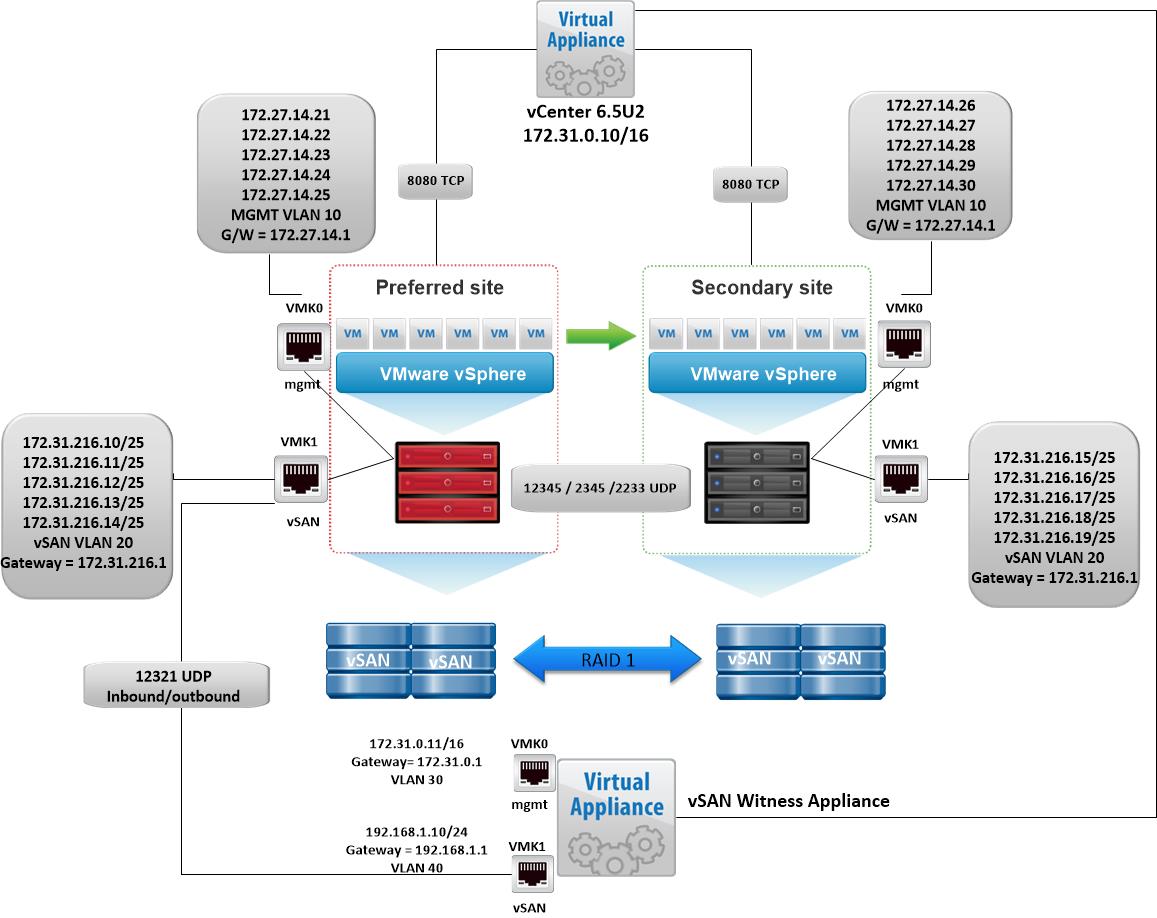
Static Routes
The recommended static routes are
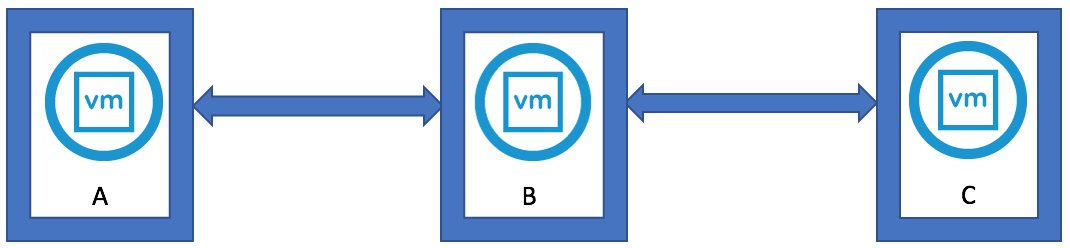
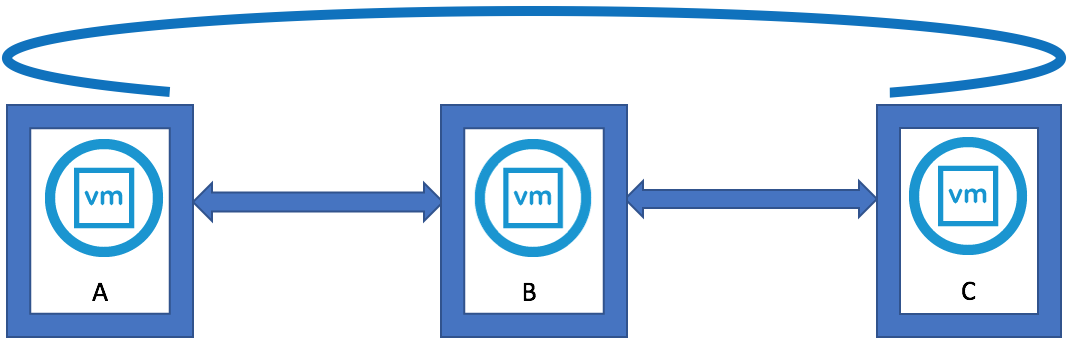
- Hosts on the Preferred Site have a static route added so that requests to reach the witness network on the Witness Site are routed out the vSAN VMkernel interface
- Hosts on the Secondary Site have a static route added so that requests to reach the witness network on the Witness Site are routed out the vSAN VMkernel interface
- The Witness Host on the Witness Site have static route added so that requests to reach the Preferred Site and Secondary Site are routed out the WitnessPg VMkernel interface
On each host on the Preferred and Secondary site
These were the manual routes added
- esxcli network ip route ipv4 add -n 192.168.1.0/24-n vmk1 -g 172.31.216.1 (192.168.1.0 being the witness vsan network and 172.31.216.1 being the host vsan vmkernel address)
- esxcli network ip route ipv4 list will show you the networking
- vmkping -I vmk1 192.168.1.10 will confirm via ping that the network is reachable
On the witness
These were the manual routes added
- esxcli network ip route ipv4 add -n 172.31.216.0/25 -n vmk1 -g 192.168.1.1 (172.31.216.0/25 being the host vsan vmkernel network and the gateway being the witness vsan vmkernel gateway)
- esxcli network ip route ipv4 list will show you the networking
- vmkping -I vmk1 172.31.216.10 will confirm via ping that the network is reachable
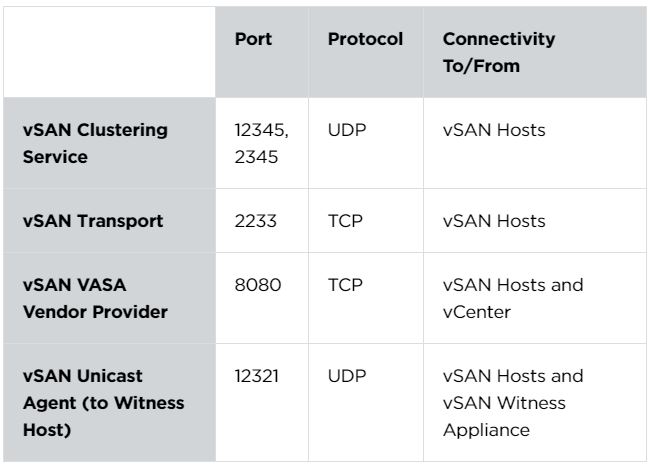
Port Requirements
Virtual SAN Clustering Service
12345, 23451 (UDP)
Virtual SAN Cluster Monitoring and Membership Directory Service. uses UDP-based IP multicast to establish cluster members and distribute Virtual SAN metadata to all cluster members. If disabled Virtual SAN does not work,
Virtual SAN Transport
2233 (TCP)
Virtual SAN reliable datagram transport. uses TCP and is used for Virtual SAN storage I/O. if disabled, Virtual SAN does not work
8080 (TCP)
vSAN VASA Vendor Provider. Used by the Storage Management Service (SMS) that is part of vCenter to access information about Virtual SAN storage profiles, capabilities and compliance. If disabled, Virtual SAN Storage Profile Based Management does not work
Virtual SAN Unicast agent to witness
12321 (UDP)
Self explanatory as needed for unicast from data nodes to witness.
vSAN Storage Hub
The link below is to the VMware Storage Hub which is the central location for all things vSAN including the vSAN stretched cluster guide which is exportable to PDF. Page 66/67 are relevant to networking/static routes.
https://storagehub.vmware.com/t/vmware-vsan/vsan-stretched-cluster-2-node-guide/network-design-considerations/