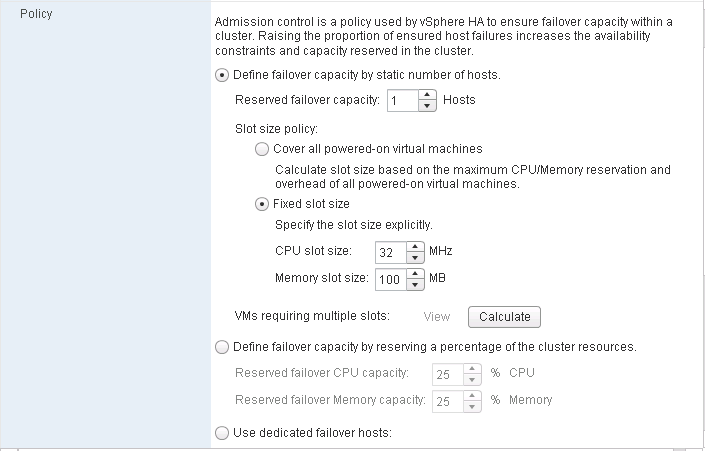
Admission Control Settings
Within a cluster we use Admission control to ensure that sufficient resources exist to provide failover protection. Admission control is also used to ensure that virtual machine resource reservations are protected
Admission Control Policies
- Host Failures the Cluster tolerates
- Percentage of Cluster Resources reserved as failover spare capacity
- Specify Failover Hosts

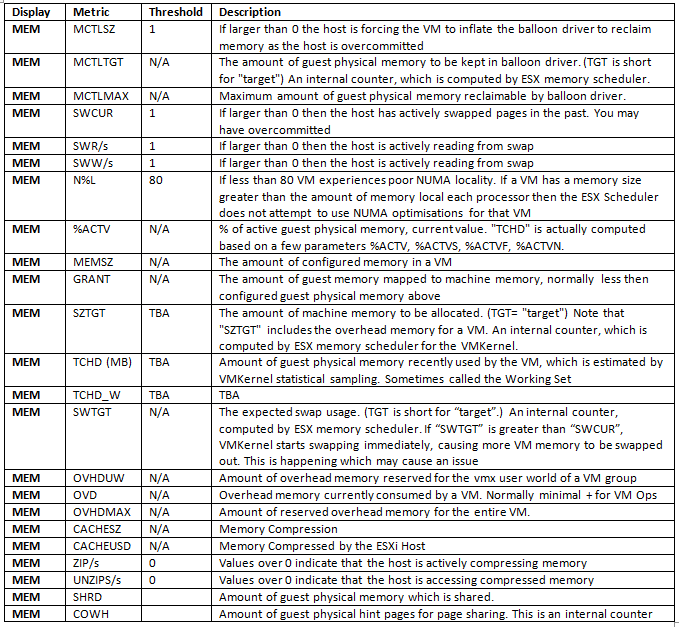
Host Failures the Cluster tolerates
What is a Slot?
A slot is a logical representation of the memory and CPU resources that satisfy the requirements for any powered-on virtual machine in the cluster
In vCenter Server 4.0, the slot size is now shown in vSphere Client on the Summary tab of the cluster

How is the Slot calculated?
- VMware HA determines how many slots are available in each ESX/ESXi host based on the host’s CPU and memory capacity.
- It then determines how many ESX/ESXi hosts can fail in the cluster with at least as many slots as powered on virtual machines.
Default Reservation Values
Slot size is comprised of two components, CPU and memory
VMware calculates the memory component by obtaining the memory reservation (If set) plus memory overhead, of each powered-on virtual machine and selecting the largest value. There is no default value for the memory reservation.
If a virtual machine does not have reservations, meaning that the reservation is 0, default values are used as listed below
- 0 MB of RAM and 256 MHz CPU speed are used for vSphere 4 and Prior
- 0 MB of RAM and 32MHz for CPU for vSphere 5.0 and above
- When no memory reservation is specified for a virtual machine, the largest memory overhead for any virtual machine in the cluster will be used as the default slot size value for memory
Advanced Settings for CPU and Memory Slot Size
- das.vmMemoryMinMB <value>
This options/value pair overrides the default memory slot size value used for admission control for VMware HA where <value> is the amount of RAM in MB to be used for the calculation if there are no larger memory reservations. By default this value is set to 256MB. This is the minimum amount of memory in MB sufficient for any VM in the cluster to be usable
This options/value pair overrides the default CPU slot size value used for admission control for VMware HA where <value> is the amount of CPU in MHz to be used for the calculation if there are no larger memory reservations. By default this value is set to 256MHz
Maximum Upper Bound Advanced Settings for Slot Sizing
If your cluster contains any virtual machines that have much larger reservations than the others, they will distort slot size calculation. To avoid this, you can specify an upper bound for the CPU or memory component of the slot size by using the das.slotcpuinmhz or das.slotmeminmb advanced attributes, respectively.
Keep in mind that when you are low on resources this could mean that you are not able to power-on this high reservation VM as resources are fragmented throughout the cluster instead of located on a single host.
This option defines the maximum bound on the memory slot size. If this option is used, the slot size is the smaller of this value or the maximum memory reservation plus memory overhead of any powered-on virtual machine in the cluster.
This option defines the maximum bound on the CPU slot size. If this option is used, the slot size is the smaller of this value or the maximum CPU reservation of any powered on virtual machine in the cluster
HA Failover Capacity
There are lots of questions surrounding VMware’s HA (High Availability), especially when users see a message stating there are “Insufficient resources to satisfy HA failover.” It is worth making the effort to understand capacity calculations. In current versions of ESX(i)and earlier, the following calculation applies for failover capacity.
Failover Capacity is determined using a slot size value that is calculated on the cluster. Slots are calculated by a combination of the total CPU and Memory that are in the physical hosts. The calculation for failover capacity works as follows:
Let’s say you have 4 ESX servers in your VMware HA cluster and Configured Failover capacity on the cluster is set to 1.
Physical memory in the hosts is as follows:
ESX1 = 16 GB
ESX2 = 24 GB
ESX3 = 32 GB
ESX4 = 32 GB
In the cluster you have 24 VM’s each configured and running. Of the 24 VM’s running, determine the VM which has the highest “configured memory”. For this example let’s say this is 2GB. All other VMs are configured with less or equal to 2GB.
With this information we can now do the calculation:
1. Pick the ESX host which has the least amount of RAM. In this case it is ESX1 and the minimum amount of RAM is = 16 GB
2. Divide the value found in step 1 with value for the maximum RAM in a VM. In my example this gives us 8 (16 divided by 2). This means we have 8 slots available per ESX host in the cluster.
3. Since we have 4 hosts and the configured failover capacity for the cluster is 1, we are left with 3 hosts in a failure situation. Hence the total number of VMs that can be powered on these 3 servers is 24 VMs. (i.e. 8 multiplied by 3 = 24)
4. If the total number of VMs in the cluster exceeds 24 then it will give us “Insufficient resources to satisfy HA failover” and the “current failover capacity will be shown as 0″. If the number is less than 24, we should not get this message.
Note: If you are still seeing the message and you have less VM’s running than in the calculation allows for, check both the CPU and Memory reservations on both VM’s and resource pools, as this can skew the calculation. You should avoid unnecessary memory or cpu reservations on VM’s as this can cause these types of errors to occur, because we have to ensure that the resource is available.
Host Failures?
What happens if you set the number of allowed host failures to 1?
The host with the most slots will be taken out of the equation. If you have 8 hosts with 90 slots in total but 7 hosts each have 10 slots and one host 20 this single host will not be taken into account. Worst case scenario! In other words the 7 hosts should be able to provide enough resources for the cluster when a failure of the “20 slot” host occurs.
And of course if you set it to 2 the next host that will be taken out of the equation is the host with the second most slots and so on
How can we get round distorted Slot Sizes causing HA errors?
There are multiple ways to fix, or get around this calculation. The most common are as follows:
- Set the Disable – “ Power on Vms that violate availability constraints” in the configuration of the cluster. In this case it ignores the above calculation and will try to power on as many VM’s as possible in case of HA failover. If this is the option chosen you can also set restart priority in the ‘Virtual Machine Options’ section of the cluster configuration. This way any high priority VM’s are powered on first, and then the lower priority up to the point where we cannot power any further VM’s on
- If you have one VM which is configured with a very high amount of memory, you can either lower its configured memory, or take it out of the cluster and run it on any other standalone ESX host. This will increase the number of slots available with the current hardware
- Increase the amount of RAM on servers so that there are more slots available with the current RAM reservations.
- Remove any CPU reservations on any VM(s) that are greater than the max speed of the processors in the hosts.
- With vSphere this is something that’s configurable. If you have just one VM with a really high reservation you can set the following advanced settings to lower the slot size being used during these calculations: das.slotCpuInMHz or das.slotMemInMB. To avoid not being able to power on the VM with high reservations these VM will take up multiple slots. Keep in mind that when you are low on resources this could mean that you are not able to power-on this high reservation VM as resources are fragmented throughout the cluster instead of located on a single host.
What if you don’t want to…
- Disable strict admission control
- Mess around with setting advanced settings for Minimum Memory and CPU Slot size
- Lower the VM Memory reservation
There is also the option of
- Creating a memory reservation on a Resource Pool and putting the VM in here
Why?
High Availability ignores resource pools reservation settings when calculating the slot size, so if a single VM is placed in a resource pool with memory reservation configured, it will have the same effect on resource allocation as per VM memory reservation, but does not affect the HA slot size.
By creating a resource pool with a substantial memory setting you can avoid decreasing the consolidation ratio of the cluster and still guarantee the virtual machine its resources. You need to be careful though. Creating a Resource Pool for each VM would be a catastrophic way of managing multiple high memory configured VMs and probably should be carried out when you have 1 or 2 VMs that have this type of configuration
Percentage of Cluster Resources Reserved as Failover
With the Percentage of Cluster Resources reserved for Failover Spare Capacity, vSphere HA ensures that a specified percentage of aggregate CPU and memory is reserved for Failover
vSphere HA uses reservations of CPU and Memory if they have been set. If not they use a default value of 0MB Memory and 256MHz CPU
With this policy HA does the following
- Calculates the total resource requirement for all powered on machines in the cluster
- Calculates the total host resources available for the virtual machines
- Calculates the current CPU and Memory failover capacity for the cluster
- Determines if either the current CPU failover or current memory failover is less than the corresponding failover capacity
- If so Admission Control disallows the operation
Example

Specify Failover Hosts
If you choose this option, be aware that you will lose one whole host to be put aside for capcity
HA Slot sizes in the vSphere 5 Web Client
You now have the ability to set slot size for “Host failures tolerated” through the vSphere Web Client
More Information
There are great articles on the below webpages regarding HA Slot sizing and calculation
http://www.vmwarewolf.com/ha-failover-capacity/#more
and this article walking you through an example
http://www.vladan.fr/ha-slot-sizes/
HA Slot sizes in the vSphere 5 Web Client
http://www.yellow-bricks.com/2012/09/12/whats-new-vsphere-5-1-high-availability/