Great pic showing Memory calculations from VMware

Great pic showing Memory calculations from VMware

I couldn’t have written it better myself so here’s a link to a blog on Kerberos and IIS and cross domain trusts.
How Kerberos Works
The current version of Kerberos is v5, which was developed in 1993. This is the version on which Microsoft’s implementation in Windows 2000/XP/Server 2003 is based. Windows 2000 and Server 2003 native mode domains use Kerberos by default. Domains that must authenticate NT systems along with the newer operating systems must use NT LAN Manager (NTLM) authentication.
Kerberos was named after Cerberus, the three-headed dog of Greek mythology, because of its three components

Logon process works with Kerberos as the authentication method
VM’s host memory usage = VM’s guest memory size + VM’s overhead memory
Each VM running on an vSphere consumes some memory overhead additional to the current usage of its configured memory. This extra memory is needed by ESX for the internal datastructures like virtual machine frame buffer and mapping table for memory translation (mapping guest physical memory to the actual machine memory)
A framebuffer is a video output device that drives a video display from a memory buffer containing a complete frame of data.
The VMM is responsible for mapping guest physical memory to the actual machine memory, and it uses shadow page tables to accelerate the mappings. As depicted
by the red line in the diagram, the VMM uses TLB (translation lookaside buffer) hardware to map the virtual memory directly to the machine memory to avoid the two levels of translation on every access. When the guest OS changes the virtual memory to physical memory mapping, the VMM updates the shadow page tables to enable a direct lookup.

Static overhead
This is the minimum amount of memory needed to start/boot the VM. DRS and the VMkernel uses this metric for admission control and VMotion calculations. The destination host must be able to back the virtual machine reservation and the static overhead otherwise the VMotion will fail.
Dynamic overhead
When the VM is powered on, the virtual machine monitor (VMM) can request additional memory space. The VMM will request the space, but the VMkernel is not required to supply it. If the VMM does not obtain the extra memory space, the virtual machine will continue to function but this can lead to performance degradation. The VMkernel treats virtual machine overhead reservation the same as VM-level memory reservation and it will not reclaim this
Memory Overhead Table

UEFI = Unified Extensible Firmware Interface

After more than 30 years of unerring and yet surprising supremacy, BIOS — the IBM PC’s Basic Input Output System will be taking a backseat to UEFI. a specification that begun its life as the Intel Boot Initiative way back in 1998 when BIOS’s antiquated limitations were hampering systems built with Intel’s Itanium processors. Later, the Initiative became EFI, and in 2005 Intel donated EFI to the newly-formed UEFI Forum, a consortium made up of the usual suspects: AMD, Apple, IBM, Intel, Microsoft, and so on.
UEFI, or Unified Extensible Firmware Interface, is a complete re-imagining of a computer boot environment, and as such it has almost no similarities to the PC BIOS that it replaces. While BIOS is fundamentally a solid piece of firmware, UEFI is a programmable software interface that sits on top a computer’s hardware and firmware (and indeed UEFI can and does sit on top of BIOS). Rather than all of the boot code being stored in the motherboard’s BIOS, UEFI sits in the/EFI/ directory in some non-volatile memory; either in NAND on the motherboard, on your hard drive, or on a network share
As a result, UEFI almost resembles a light-weight operating system. A computer boots into UEFI, an arbitrary set of actions are carried out, and then it triggers the loading of an operating system. Further reinforcing its OSness, the UEFI spec defines boot and runtime services, protocols for communication between services, device drivers (UEFI is designed to work across all platforms), extensions, and even an EFI shell, where you can run EFI applications. On top of all this is the boot loader, which executes an operating system’s boot loader.
UEFI, being a pseudo-operating system, can access all of the hardware on the computer, you can surf the internet from the UEFI interface, or backup your hard drives, and it even has a full, mouse-driven GUI (below right). The fact that all of this boot data is stored on NAND flash or on a hard drive means that there’s a lot more space for things like language localization, boot-time diagnostics and utilities (backup, restore, malware scanners)
UEFI is still very young, and very few operating systems actually take advantage of any of the features listed above. Linux certainly supports UEFI, but doesn’t really utilizes it. Mac OS X makes slightly better use of UEFI with the Bootcamp boot manager. Windows 8, when it launches in 2012, will probably be the first major OS to take extensive advantage of UEFI, with Restore, Refresh, secure boot, and possibly more.
VMware vSphere 5 supports booting ESXi hosts from the UEFI. UEFI allows you to boot systems from USB Media (as well as hard drives and CD-ROM Drives)
What is RAW Device Mapping?
A Raw Device Mapping allows a special file in a VMFS volume to act as a proxy for a raw device. The mapping file contains metadata used to manage and redirect disk accesses to the physical device. The mapping file gives you some of the advantages of a virtual disk in the VMFS file system, while keeping some advantages of direct access to physical device characteristics. In effect it merges VMFS manageability with raw device access
A raw device mapping is effectively a symbolic link from a VMFS to a raw LUN. This makes LUNs appear as files in a VMFS volume. The mapping file, not the raw LUN is referenced in the virtual machine configuration. The mapping file contains a reference to the raw LUN.
Note that raw device mapping requires the mapped device to be a whole LUN; mapping to a partition only is not supported.

Uses for RDM’s
For example, When a VM needs a partition that is greater than the VMFS 2 TB limit is a reason to use an RDM. Large file servers, if you choose to encapsulate them as a VM, are a prime example. Perhaps a data warehouse application would be another. Alongside this, the time it would take to move a vmdk larger than this would be significant.
SAN snapshots, direct backups, performance monitoring, and SAN management are all possible reasons to consider RDMs. Native SAN tools can snapshot the LUN and move the data about at a much quicker rate.
Actually, this is not a choice. Microsoft Clustering Services (MSCS) running on VMware VI require RDMs. Clustering VMs across ESX hosts is still commonly used when consolidating hardware to VI. VMware now recommends that cluster data and quorum disks be configured as raw device mappings rather than as files on shared VMFS
Terminology
The following terms are used in this document or related documentation:
Compatibility Modes

Physical Mode RDMs
Virtual Mode RDMs
Setting up RDMs
If the option is greyed out, please check the following.
http://kb.vmware.com/RDM Greyed Out
Note: To use vMotion for virtual machines with enabled NPIV, make sure that the RDM files of the virtual machines are located on the same datastore. You cannot perform Storage vMotion or vMotion between datastores when NPIV is enabled.
Intro
For the past decade, processor clock speed has skyrocketed at rates exceeding even the predictions of Moores Law. A multi Gigahertz CPU, however needs to be supplied with an enormous amount of memory bandwidth in order to do its processing effectively.
Even a single CPU running a memory intensive workload such as a scientific computing application, can find itself constrained by memory bandwidth
These problems are amplified many times over on symmetric multiprocessing (SMP) systems where many processors must compete for bandwidth on the same system bus.
What is NUMA?
NUMA is Non Uniform Memory Access
NUMA is an alternative approach that links several small, cost-effective nodes via a high performance interconnect. Each node contains both processors and memory, much like a small SMP system. However, an advanced memory controller allows a node to use memory on all other nodes, creating a single system image. When a processor accesses memory that does not lie within its own node (remote memory), the data must be transferred over the NUMA interconnect, which is slower than accessing local memory. Thus, memory access times are “non-uniform,” depending on the location of the memory, as the technology’s name implies
So what does Non-Uniform Memory Access really mean?
Non-Uniform Memory Access means that it will take longer to access some regions of memory than others. This is due to the fact that some regions of memory are on physically different busses from other regions
Imagine that you are baking a cake. You have a group of ingredients (=memory pages) that you need to complete the recipe(=process). Some of the ingredients you may have in your cabinet(=local memory), but some of the ingredients you might not have, and have to ask a neighbor for(=remote memory). The general idea is to try and have as many of the ingredients in your own cabinet as possible, since this reduces your time and effort in making the cake.
You also have to remember that your cabinets can only hold a fixed amount of ingredients(=physical nodal memory). If you try and buy more, but you have no room to store it, you may have to ask your neighbor to keep it in his/her cabinet until you need it(=local memory full, so allocate pages remotely).
What is meant by Local and Remote Memory?
The terms local memory and remote memory are typically used in reference to a currently running process. That said, local memory is typically defined to be the memory that is on the same node as the CPU currently running the process. Any memory that does not belong to the node on which the process is currently running is then, by that definition, remote.
Local and remote memory can also be used in reference to things other than the currently running process. When in interrupt context, there technically is no currently executing process, but memory on the node containing the CPU handling the interrupt is still called local memory. Also, you could use local and remote memory in terms of a disk. For example if there was a disk (attatched to node 1) doing a DMA, the memory it is reading or writing would be called remote if it were located on another node (ie: node 0)
What is the difference between NUMA and SMP?
The NUMA architecture was designed to surpass the scalability limits of the SMP architecture. With SMP, which stands for Symmetric Multi-Processing, all memory access are posted to the same shared memory bus. This works fine for a relatively small number of CPUs, but the problem with the shared bus appears when you have dozens, even hundreds, of CPUs competing for access to the shared memory bus. NUMA alleviates these bottlenecks by limiting the number of CPUs on any one memory bus, and connecting the various nodes by means of a high speed interconnect.
Why should I use NUMA? What are the benefits of NUMA?
The main benefit of NUMA is, as mentioned above, scalability. It is extremely difficult to scale SMP past 8-12 CPUs. At that number of CPUs, the memory bus is under heavy contention. NUMA is one way of reducing the number of CPUs competing for access to a shared memory bus. This is accomplished by having several memory busses and only having a small number of CPUs on each of those busses. There are other ways of building massively multiprocessor machines
Issues
The high latency of remote memory accesses can leave the processors under-utilized, constantly waiting for data to be transferred to the local node and the NUMA interconnect can also become a bottleneck for applications with high memory bandwidth demands.
Furthermore, performance on such a system may be highly variable, for example, if an application has memory located locally on one benchmarking run, but a subsequent run happens to place all that memory on a remote node. This phenomenon can make capacity planning much more difficult. Finally processor clocks may not be synchronised between multiple nodes so applications that read this clock directly may be behave incorrectly.
Typical Four-Processor NUMA Node Architecture
High-end servers are designed to support more than one system bus. One design approach is to create a number of nodes where each node contains some processors, some memory, and, in some cases, an I/O subsystem as per below pic
")
Two Four-Processor NUMA Nodes Connected as an Eight-Processor NUMA System
To increase system capacity, additional nodes are connected using the high-speed cache-coherent system interconnect, as shown
")
In the diagram, all eight processors can access memory in both nodes coherently. For example:
It takes more time to access memory in another node than it takes to access local memory. This difference in memory access times is the origin of the name for these systems: non-uniform memory architecture (NUMA).
The ratio of the time taken to access near memory to the time taken to access far memory is referred to as the NUMA ratio. The higher the NUMA ratio value — that is, the greater the disparity between the time it takes to access far memory as compared to near memory — the greater the effect that NUMA characteristics may have on software performance.
3:1 being an optimal ratio
VMware Labs is VMware’s home for collaboration. They see collaboration as the information exchange that takes place internally and externally. On this site you can play around with the latest innovations coming out of VMware and share feedback and ideas directly with their engineers. VMware Labs is also the place where VMware engineers can share their cool and useful tools with you. With this in mind, Labs is made up of the following components:
Flings
VMware’s engineers work on tons of pet projects in their spare time, and are always looking to get feedback on their projects (or “flings”). Why flings? A fling is a short-term thing, not a serious relationship but a fun one. Likewise, the tools that are offered here are intended to be played with and explored. None of them are guaranteed to become part of any future product offering and there is no support for them. They are, however, totally free for you to download and play around with them!
Website
This looks like a really useful tool for the VMware Admins out there
RVTools is a windows .NET 2.0 application which uses the VI SDK to display information about your virtual machines and ESX hosts. Interacting with VirtualCenter 2.5, ESX 3.5, ESX3i, ESX4i and vSphere 4 RVTools is able to list information about cpu, memory, disks, nics, cd-rom, floppy drives, snapshots, VMware tools, ESX hosts, nics, datastores, service console, VM Kernel, switches, ports and health checks. With RVTools you can disconnect the cd-rom or floppy drives from the virtual machines and RVTools is able to list the current version of the VMware Tools installed inside each virtual machine. and update them to the latest version.

Early virtualization efforts relied on software emulation to replace hardware functionality. But software emulation can be a slow and inefficient process. Because many virtualization tasks were handled through software, VM behavior and resource control were often poor, resulting in unacceptable VM performance on the server.
Processors lacked the internal microcode to handle intensive virtualization tasks in hardware. Both Intel Corp. and AMD addressed this problem by creating processor extensions that could offload the repetitive and inefficient work from the software. By handling these tasks through processor extensions, traps and emulation of virtualization, tasks through the operating system were essentially eliminated, vastly improving VM performance on the physical server.
AMD
AMD-V (AMD virtualization) is a set of hardware extensions for the X86 processor architecture. Advanced Micro Dynamics (AMD) designed the extensions to perform repetitive tasks normally performed by software and improve resource use and virtual machine (VM) performance.
AMD Virtualization (AMD-V) technology was first announced in 2004 and added to AMD’s Pacifica 64-bit x86 processor designs. By 2006, AMD’s Athlon 64 X2 and Athlon 64 FX processors appeared with AMD-V technology, and today, the technology is available on Turion 64 X2, second- and third-generation Opteron, Phenom and Phenom II processors
Intel-VT
Intel VT (Virtualization Technology) is the company’s hardware assistance for processors running virtualization platforms.
Intel VT includes a series of extensions for hardware virtualization. The Intel VT-x extensions are probably the best recognized extensions, adding migration, priority and memory handling capabilities to a wide range of Intel processors. By comparison, the VT-d extensions add virtualization support to Intel chipsets that can assign specific I/O devices to specific virtual machines (VM)s, while the VT-c extensions bring better virtualization support to I/O devices such as network switches.
Three alternative techniques now exist for handling sensitive and privileged instructions to virtualize the CPU on the x86 architecture:
Full virtualization using binary translation
X86 operating systems are designed to run directly on the bare-metal hardware, so they naturally assume they fully ‘own’ the computer hardware. As shown in the figure below, the x86 architecture offers four levels of privilege known as Ring 0, 1, 2 and 3 to operating systems and applications to manage access to the computer hardware

While user level applications typically run in Ring 3, the operating system needs to have direct access to the memory and hardware and must execute its privileged instructions in Ring 0. Virtualizing the x86 architecture requires placing a virtualization layer under the operating system (which expects to be in the most privileged Ring 0) to create and manage the virtual machines that deliver shared resources.
Further complicating the situation, some sensitive instructions can’t effectively be virtualized as they have different semantics when they are not executed in Ring 0. The difficulty in trapping and translating these sensitive and privileged instruction requests at runtime was the challenge that originally made x86 architecture virtualization look impossible.
VMware resolved the challenge in 1998, developing binary translation techniques that allow the VMM to run in Ring 0 for isolation and performance, while moving the operating system to a user level ring with greater privilege than applications in Ring 3 but less privilege than the virtual machine monitor in Ring 0.
OS Assisted Virtualization or Paravirtualization
“Para-“ is an English affix of Greek origin that means “beside,” “with,” or “alongside.” Given the meaning “alongside virtualization,” paravirtualization refers to communication between the guest OS and the hypervisor to improve performance and efficiency.
Paravirtualization, as shown the picture below, involves modifying the OS kernel to replace nonvirtualizable instructions with hypercalls that communicate directly with the virtualization layer hypervisor. The hypervisor also provides hypercall interfaces for other critical kernel operations such as memory management, interrupt handling and time keeping. Paravirtualization is different from full virtualization, where the unmodified OS does not know it is virtualized and sensitive OS calls are trapped using binary translation. The value proposition of paravirtualization is in lower virtualization overhead, but the performance advantage of paravirtualization over full virtualization can vary greatly depending on the workload

Hardware assisted virtualization (first generation)
Going back to the first descriptions of the processors Hardware Assist capabilities – Hardware vendors are rapidly embracing virtualization and developing new features to simplify virtualization techniques. First generation enhancements include Intel Virtualization Technology (VT-x) and AMD’s AMD-V which both target privileged
instructions with a new CPU execution mode feature that allows the VMM to run
in a new root mode below ring 0. As depicted in the figure below, privileged and sensitive calls are set to automatically trap to the hypervisor, removing the need for either binary translation or paravirtualization. The guest state is stored in Virtual Machine Control Structures (VT-x) or Virtual Machine Control Blocks (AMD-V).
Processors with Intel VT and AMD-V became available in 2006, so only newer systems contain these hardware assist features.

Vmware Document describing Full Virtualization, Paravirtualisation and Hardware Assist
http://www.vmware.com/files/pdf/VMware_paravirtualization.pdf
VLANs provide for logical groupings of stations or switch ports, allowing communications as if all stations or ports were on the same physical LAN segment. Confining broadcast traffic to a subset of the switch ports or end users saves significant amounts of network bandwidth and processor time.
In order to support VLANs for VMware Infrastructure users, one of the elements on the virtual or physical network has to tag the Ethernet frames with 802.1Q tag as per below
The most common tagging is 802.1Q, which is an IEEE standard that nearly all switches support. The tag is there to identify which VLAN the layer 2 frame belongs to. vSphere can both understand these tags (receive them) as well as add them to outbound traffic (send them)

There are three different configuration modes to tag (and untag) the packets for virtual machine frames
1. VST (Virtual Switch Tagging)
This is the most common configuration. In this mode, you provision one port group on a virtual switch for each VLAN, then attach the virtual machine’s virtual adapter to the port group instead of the virtual switch directly.
The virtual switch port group tags all outbound frames and removes tags for all inbound frames. It also ensures that frames on one VLAN do not leak into a different VLAN.
Use of this mode requires that the physical switch provide a trunk. E.g The ESX host network adapters must be connected to trunk ports on the physical switch.
The port groups connected to the virtual switch must have an appropriate VLAN ID specified
switchport trunk encapsulation dot1q
switchport mode trunk
switchport trunk allowed vlan x,y,z
spanning-tree portfast trunk
Note: The Native VLAN is not tagged and thus requires no VLAN ID to be set on the ESX/ESXi portgroup.
2. VGT (Virtual Guest Tagging)
You may install an 802.1Q VLAN trunking driver inside the virtual machine, and tags will be preserved between the virtual machine networking stack and external switch when frames are passed from or to virtual switches. Use of this mode requires that the physical switch provide a trunk
3. EST (External Switch Tagging)
You may use external switches for VLAN tagging. This is similar to a physical network, and VLAN configuration is normally transparent to each individual physical server.
There is no need to provide a trunk in these environments.
All VLAN tagging of packets is performed on the physical switch.
ESX host network adapters are connected to access ports on the physical switch.
The portgroups connected to the virtual switch must have their VLAN ID set to 0.
See this example snippet of a code from a Cisco switch port configuration:
switchport mode access
switchport access vlan x
Virtual Distributed Switches
In vSphere, there’s a new networking feature which can be configured on the distributed virtual switch (or DVS). In VI3 it is only possible to add one VLAN to a specific port group in the vSwitch. in the DVS, you can add a range of VLANs to a single port group. The feature is called VLAN trunking and it can be configured when you add a new port group. There you have the option to define a VLAN type, which can be one of the following:
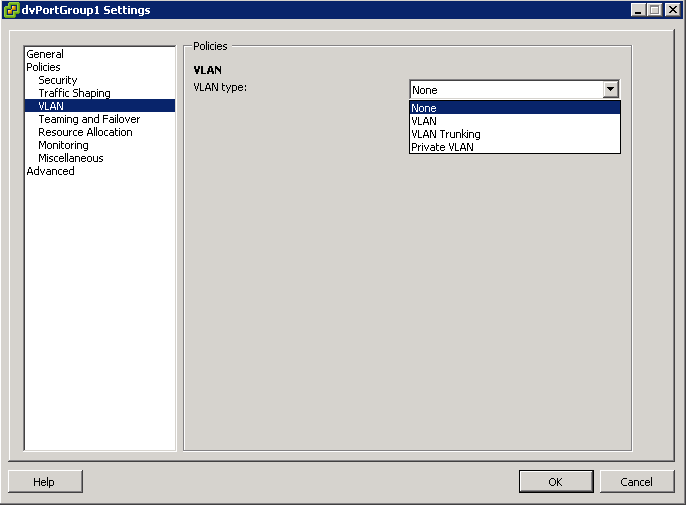
The VLAN policy allows virtual networks to join physical VLANs.

What is a VLAN Trunk?
A VLAN trunk is a port on a physical switch that has the ability to listen and pass traffic for multiple VLANs. Trunks are used primarily to pass traffic between multiple switches.
In Cisco networks, trunking is a special function that can be assigned to a port, making that port capable of carrying traffic for any or all of the VLANs accessible by a particular switch. Such a port is called a trunk port, in contrast to an access port, which carries traffic only to and from the specific VLAN assigned to it. A trunk port marks frames with special identifying tags (either ISL tags or 802.1Q tags) as they pass between switches, so each frame can be routed to its intended VLAN. An access port does not provide such tags, because the VLAN for it is pre-assigned, and identifying markers are therefore unnecessary.
A quick note on the relationship between VLANs and vSwitch port groups. A VLAN can contain multiple port groups, but a port group can only be associated with one VLAN at any given time. A prerequisite for VLAN functionality on a vSwitch (vSS or vDS) is that the vSwitch uplinks must be connected to a trunk port on the physical switch. This trunk port will also need to include the associated VLAN ID range, enabling the physical switch to pass VLAN tags to the ESXi host. So why is any of this important? A trunk port can store and distribute multiple VLAN tags, enabling multiple traffic types to flow independently (at least logically), across the same uplink or group of uplinks in the case of teamed NICs
Use case for using VLAN trunking would be if you have multiple VLANs in place for logical separation or to isolate your VM traffic but you have a limited amount of physical uplink ports dedicated for your ESXi hosts
Networking Policies
Policies set at the standard switch or distributed port group level apply to all of the port groups on the standard switch or to ports in the distributed port group. The exceptions are the configuration options that are overridden at the standard port group or distributed port level.
Useful Post (Thanks to Mohammed Raffic)

