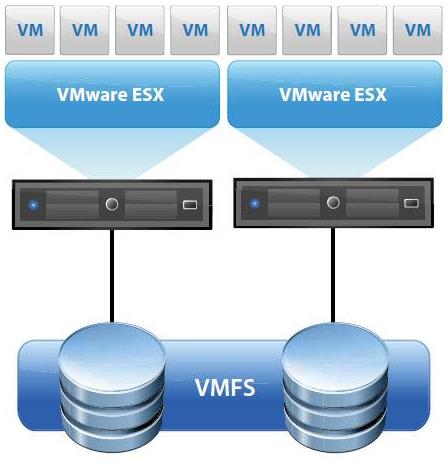
When upgrading from vSphere 4 to vSphere 5, it is not required to upgrade datastores from VMFS-3 to VMFS-5. This might be relevant if a subset of ESX/ESXi 4 hosts will remain in your environment. When the decision is made to upgrade datastores from version 3 to version 5 note that the upgrade process can be performed on active datastores, with no disruption to running VMs
Benefits
- Unified 1MB File Block Size
Previous versions of VMFS used 1,2,4 or 8MB file blocks. These larger blocks were needed to create large files (>256GB). These large blocks are no longer needed for large files on VMFS-5. Very large files can now be created on VMFS-5 using 1MB file blocks.
- Large Single Extent Volumes
In previous versions of VMFS, the largest single extent was 2TB. With VMFS-5, this limit is now 64TB.
- Smaller Sub-Block
VMFS-5 introduces a smaller sub-block. This is now 8KB rather than the 64KB we had in previous versions. Now small files < 8KB (but > 1KB) in size will only consume 8KB rather than 64KB. This will reduce the amount of disk space being stranded by small files.
- Small File Support
VMFS-5 introduces support for very small files. For files less than or equal to 1KB, VMFS-5 uses the file descriptor location in the metadata for storage rather than file blocks. When they grow above 1KB, these files will then start to use the new 8KB sub blocks. This will again reduce the amount of disk space being stranded by very small files.
- Increased File Count
VMFS-5 introduces support for greater than 100,000 files, a three-fold increase on the number of files supported on VMFS-3, which was 30,000.
- ATS Enhancement
This Hardware Acceleration primitive, Atomic Test & Set (ATS), is now used throughout VMFS-5 for file locking. ATS is part of the VAAI (vSphere Storage APIs for Array Integration) This enhancement improves the file locking performance over previous versions of VMFS.
Considerations for Upgrade
- If your datastores were formatted with VMFS2 or VMFS3, you can upgrade the datastores to VMFS5.
- To upgrade a VMFS2 datastore, you use a two-step process that involves upgrading VMFS2 to VMFS3 first. Because ESXi 5.0 hosts cannot access VMFS2 datastores, use a legacy host, ESX/ESXi 4.x or earlier, to access the VMFS2 datastore and perform the VMFS2 to VMFS3 upgrade.
- After you upgrade your VMFS2 datastore to VMFS3, the datastore becomes available on the ESXi 5.0 host, where you complete the process of upgrading to VMFS5.
- When you upgrade your datastore, the ESXi file-locking mechanism ensures that no remote host or local process is accessing the VMFS datastore being upgraded. Your host preserves all files on the datastore
- The datastore upgrade is a one-way process. After upgrading your datastore, you cannot revert it back to its previous VMFS format.
- Verify that the volume to be upgraded has at least 2MB of free blocks available and 1 free file descriptor.
- All hosts accessing the datastore must support VMFS 5
- You cannot upgrade VMFS3 volumes to VMFS5 remotely with the vmkfstools command included in vSphere CLI.
Comparing VMFS3 and VMFS5
Instructions for upgrading
- Log in to the vSphere Client and select a host from the Inventory panel.
- Click the Configuration tab and click Storage.
- Select the VMFS3 datastore.
- Click Upgrade to VMFS5.
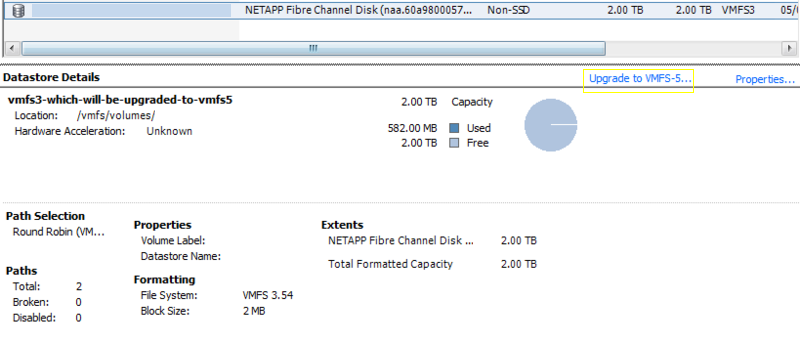
- A warning message about host version support appears.
- Click OK to start the upgrade.
- The task Upgrade VMFS appears in the Recent Tasks list.
- Perform a rescan on all hosts that are associated with the datastore.
Upgrading via ESXCLI
- esxcli storage vmfs upgrade -l volume_name
Other considerations
- The maximum size of a VMDK on VMFS-5 is still 2TB -512 bytes.
- The maximum size of a non-passthru (virtual) RDM on VMFS-5 is still 2TB -512 bytes.
- The maximum number of LUNs that are supported on an ESXi 5.0 host is still 256
- There is now support for passthru RDMs to be ~ 60TB in size.
- Non-passthru RDMs are still limited to 2TB – 512 bytes.
- Both upgraded VMFS-5 & newly created VMFS-5 support the larger passthru RDM.