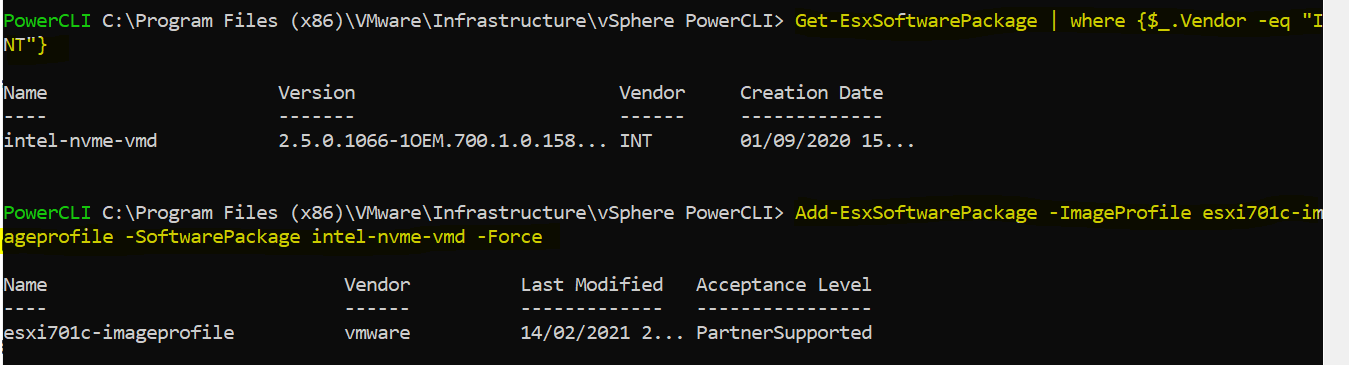
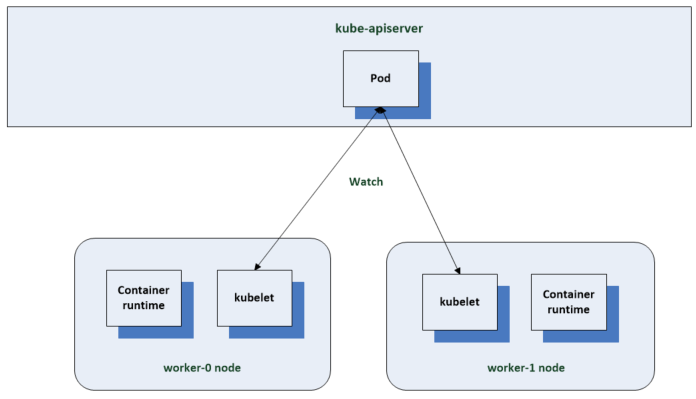
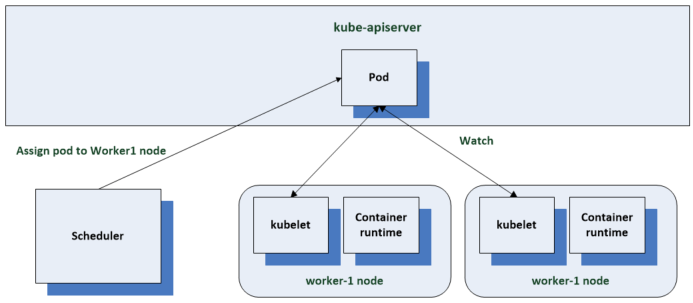
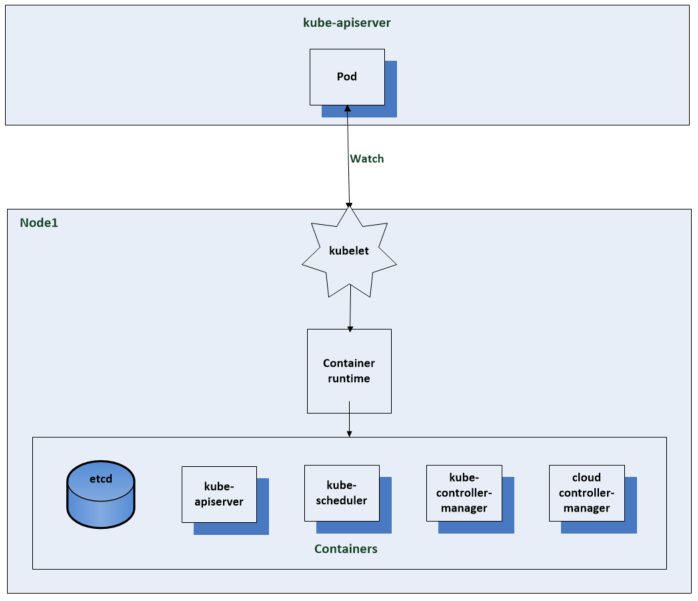
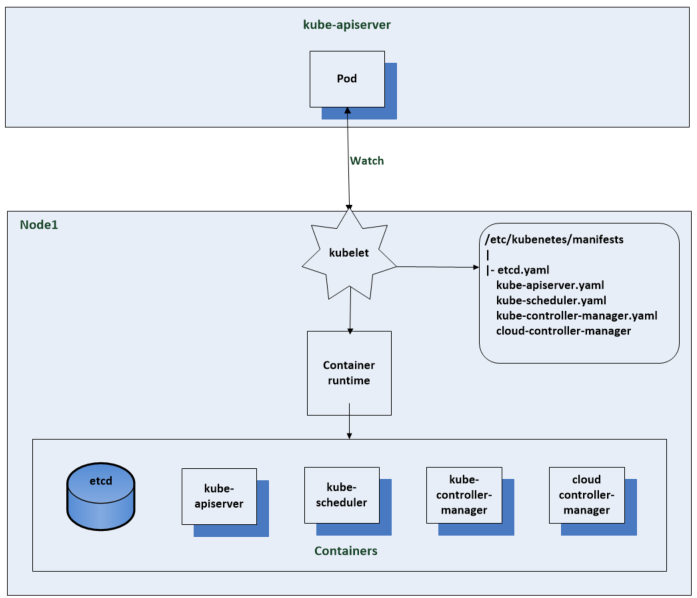
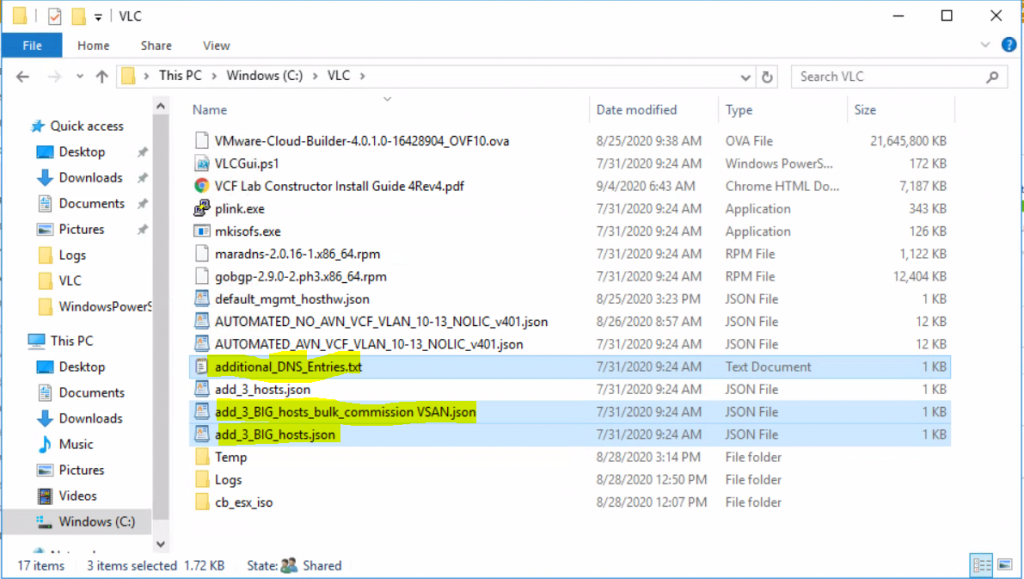
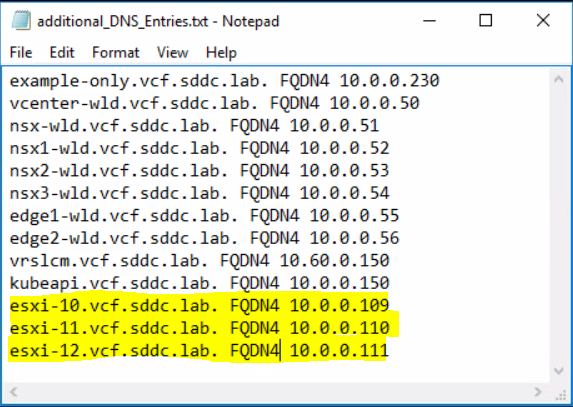
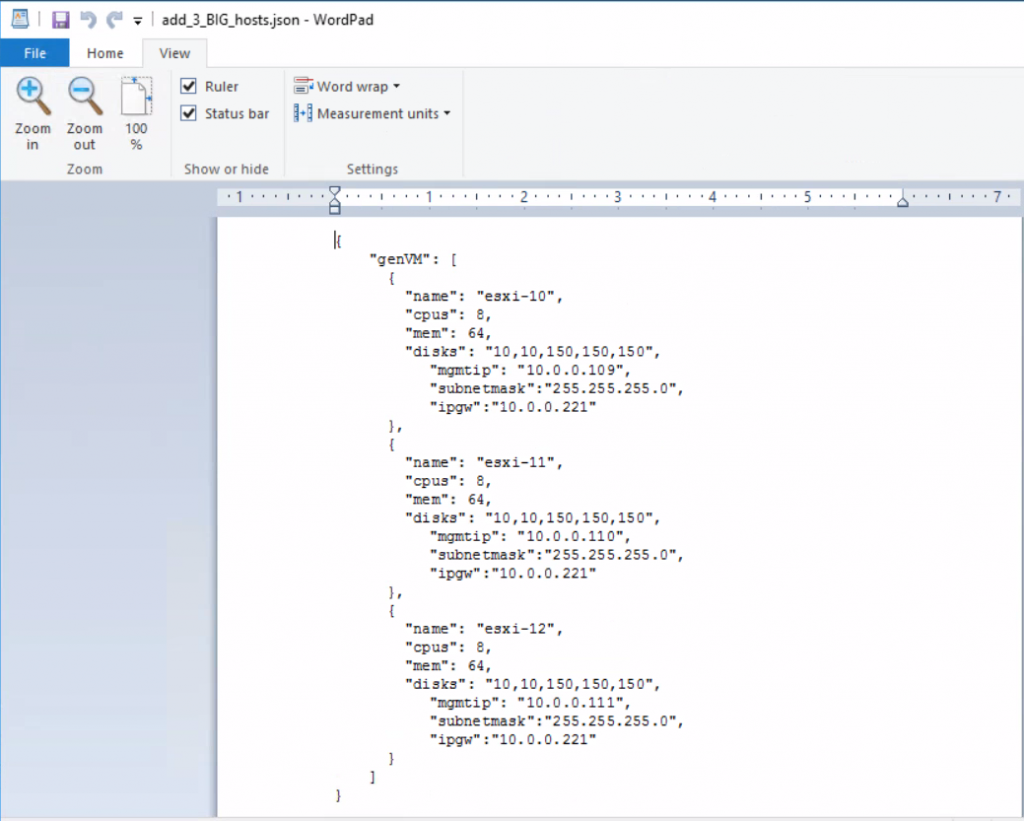
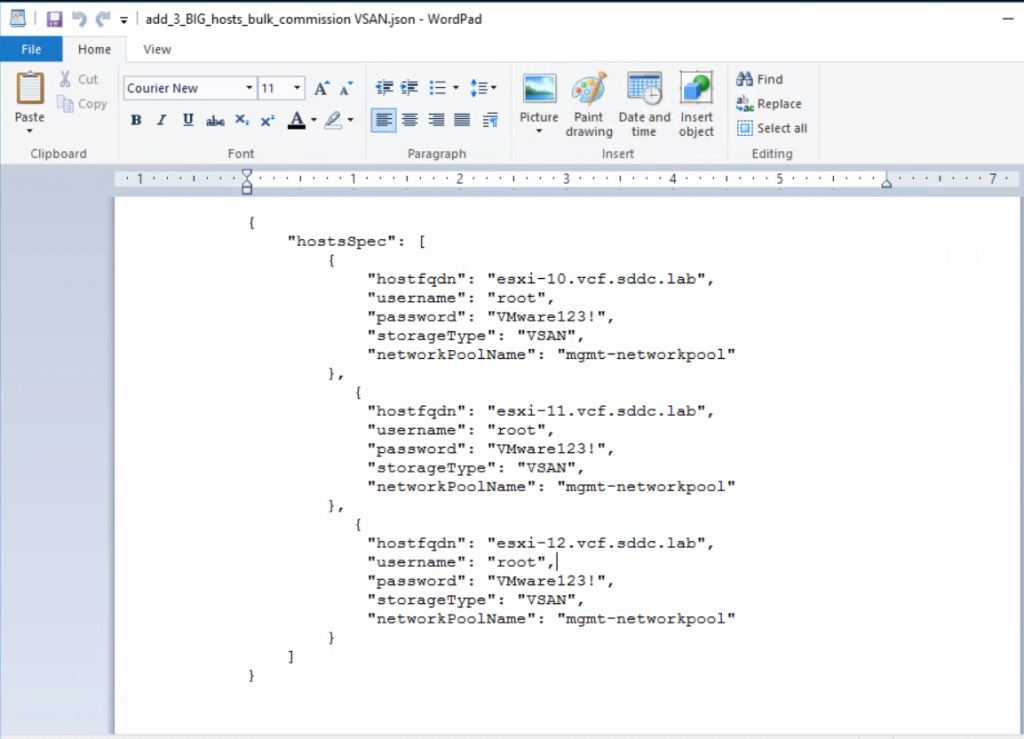
This blog is similar to another I wrote which compared VM Encryption and vSAN encryption on ESXi 6.7U3. This time, I’m comparing VM Encryption performance on ESXi 6.7U3 and ESXi 7.0U2 running on vSAN.
What is the problem which needs to be solved?
I have posted this section before on the previous blog however it is important to understand the effect of an extra layer of encryption has on the performance of your systems. It has become a requirement (sometimes mandatory) for companies to enable protection of both personal identifiable information and data; including protecting other communications within and across environments New EU General Data Protection Regulations (GDPR) are now a legal requirement for global companies to protect the personal identifiable information of all European Union residents. In the last year, the United Kingdom has left the EU, however the General Data Protection Regulations will still be important to implement. “The Payment Card Industry Data Security Standards (PCI DSS) requires encrypted card numbers. The Health Insurance Portability and Accountability Act and Health Information Technology for Economic and Clinical Health Acts (HIPAA/HITECH) require encryption of Electronic Protected Health Information (ePHI).” (Townsendsecurity, 2019) Little is known about the effect encryption has on the performance of different data held on virtual infrastructure. VM encryption and vSAN encryption are the two data protection options I will evaluate for a better understanding of the functionality and performance effect on software defined storage.
It may be important to understand encryption functionality in order to match business and legal requirements. Certain regulations may need to be met which only specific encryption solutions can provide. Additionally, encryption adds a layer of functionality which is known to have an effect on system performance. With systems which scale into thousands, it is critical to understand what effect encryption will have on functionality and performance in large environments. It will also help when purchasing hardware which has been designed for specific environments to allow some headroom in the specification for the overhead of encryption
Testing Components
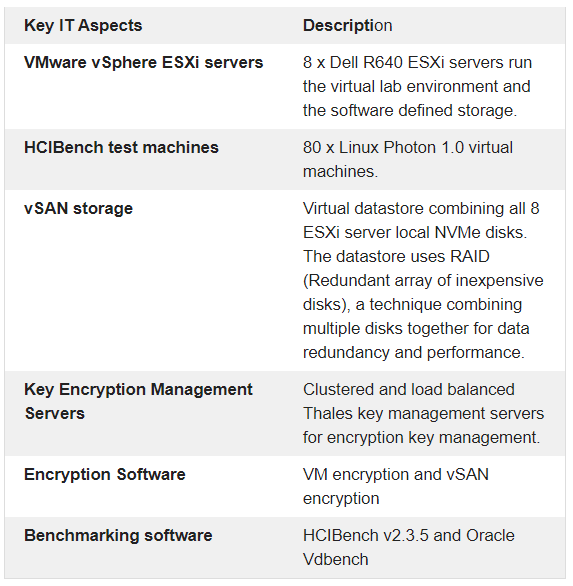
Test lab hardware (8 Servers)
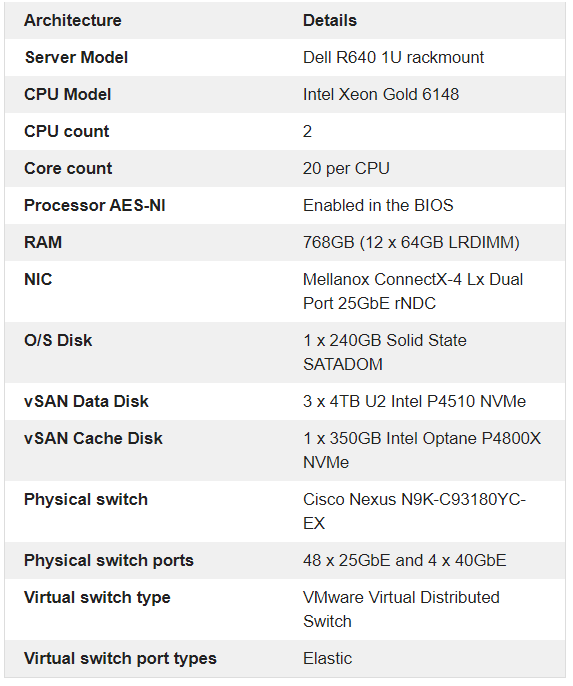
HCIBench Test VMs
80 HCIBench Test VMs will be used for this test. I have placed 10 VMs on each of the 8 Dell R640 servers to provide a balanced configuration. No virtual machines other than the HCIBench test VMs will be run on this system to avoid interference with the testing.
The HCIBench appliance is running vdBench, not Fio
The specification of the 80 HCIBench Test VMs are as follows.
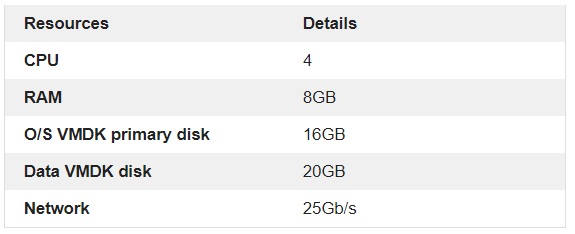
RAID Configuration
VM encryption will be tested on RAID1 and RAID6 vSAN storage
VM encryption RAID1 storage policy
| Test Parameters | Configuration |
| vCenter Storage Policy | Name = raid1_vsan_policy Storage Type = vSAN Failures to tolerate = 2 (RAID 1) Thin provisioned = Yes Number of disk stripes per object = 2 Encryption enabled = Yes Deduplication and Compression enabled = No |
VM encryption RAID6 storage policy
| Test Parameters | Configuration |
| vCenter Storage Policy | Name = raid6_vsan_policy Storage Type = vSAN Failures to tolerate = 2 (RAID6) Thin provisioned = Yes Number of disk stripes per object = 1 Encryption enabled = Yes Deduplication and Compression enabled = No |
HCIBench Test Parameters
The test will run through various types of read/write workload at the different block sizes to replicate different types of applications using 1 and 2 threads.
- 0% Read 100% Write
- 20% Read 80% Write
- 70% Read 30% Write
The block sizes used are
- 4k
- 16k
- 64k
- 128k
The test plan below containing 24 tests will be run for VM Encryption on 6.7U3 and again for VM Encryption on 7.0U2. These are all parameter files which are uploaded in HCIBench then can run sequentially without intervention through the test. I think I left these running for 3 days! It refreshes the cache in between tests.
Scroll across at the bottom to see the whole table
| Test | Number of disks | Working Set % | Number of threads | Block size (k) | Read % | Write % | Random % | Test time (s) |
| 1 | 2 (O/S and Data) | 100% | 1 | 4k | 0 | 100 | 100 | 7200 |
| 2 | 2 (O/S and Data) | 100% | 2 | 4k | 0 | 100 | 100 | 7200 |
| 3 | 2 (O/S and Data) | 100% | 1 | 4k | 20 | 80 | 100 | 7200 |
| 4 | 2 (O/S and Data) | 100% | 2 | 4k | 20 | 80 | 100 | 7200 |
| 5 | 2 (O/S and Data) | 100% | 1 | 4k | 70 | 30 | 100 | 7200 |
| 6 | 2 (O/S and Data) | 100% | 2 | 4k | 70 | 30 | 100 | 7200 |
| 7 | 2 (O/S and Data) | 100% | 1 | 16k | 0 | 100 | 100 | 7200 |
| 8 | 2 (O/S and Data) | 100% | 2 | 16k | 0 | 100 | 100 | 7200 |
| 9 | 2 (O/S and Data) | 100% | 1 | 16k | 20 | 80 | 100 | 7200 |
| 10 | 2 (O/S and Data) | 100% | 2 | 16k | 20 | 80 | 100 | 7200 |
| 11 | 2 (O/S and Data) | 100% | 1 | 16k | 70 | 30 | 100 | 7200 |
| 12 | 2 (O/S and Data) | 100% | 2 | 16k | 70 | 30 | 100 | 7200 |
| 13 | 2 (O/S and Data) | 100% | 1 | 64k | 0 | 100 | 100 | 7200 |
| 14 | 2 (O/S and Data) | 100% | 2 | 64k | 0 | 100 | 100 | 7200 |
| 15 | 2 (O/S and Data) | 100% | 1 | 64k | 20 | 80 | 100 | 7200 |
| 16 | 2 (O/S and Data) | 100% | 2 | 64k | 20 | 80 | 100 | 7200 |
| 17 | 2 (O/S and Data) | 100% | 1 | 64k | 70 | 30 | 100 | 7200 |
| 18 | 2 (O/S and Data) | 100% | 2 | 64k | 70 | 30 | 100 | 7200 |
| 19 | 2 (O/S and Data) | 100% | 1 | 128k | 0 | 100 | 100 | 7200 |
| 20 | 2 (O/S and Data) | 100% | 2 | 128k | 0 | 100 | 100 | 7200 |
| 21 | 2 (O/S and Data) | 100% | 1 | 128k | 20 | 80 | 100 | 7200 |
| 22 | 2 (O/S and Data) | 100% | 2 | 128k | 20 | 80 | 100 | 7200 |
| 23 | 2 (O/S and Data) | 100% | 1 | 128k | 70 | 30 | 100 | 7200 |
| 24 | 2 (O/S and Data) | 100% | 2 | 128k | 70 | 30 | 100 | 7200 |
HCIBench Performance Metrics
These metrics will be measured across all tests
| Workload Parameter | Explanation | Value |
| IOPs | IOPS measures the number of read and write operations per second | Input/Outputs per second |
| Throughput | Throughput measures the number of bits read or written per second Average IO size x IOPS = Throughput in MB/s | MB/s |
| Read Latency | Latency is the response time when you send a small I/O to a storage device. If the I/O is a data read, latency is the time it takes for the data to come back | ms |
| Write Latency | Latency is the response time when you send a small I/O to a storage device. If the I/O is a write, latency is the time for the write acknowledgement to return. | ms |
| Latency Standard Deviation | Standard deviation is a measure of the amount of variation within a set of values. A low standard deviation indicates that the values tend to be close to the mean of the set, while a high standard deviation indicates that the values are spread out over a wider range | Values must be compared to the standard deviation |
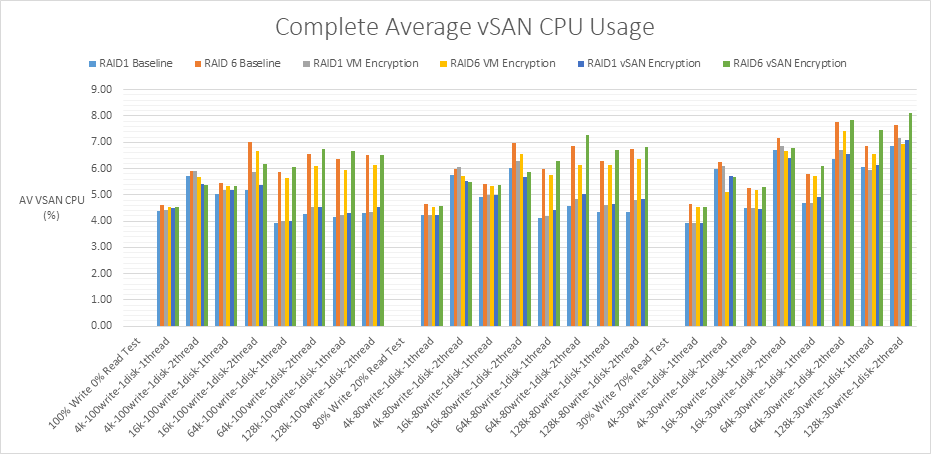
| Average ESXi CPU usage | Average ESXi Host CPU usage | % |
| Average vSAN CPU usage | Average CPU use for vSAN traffic only | % |
Results
IOPs
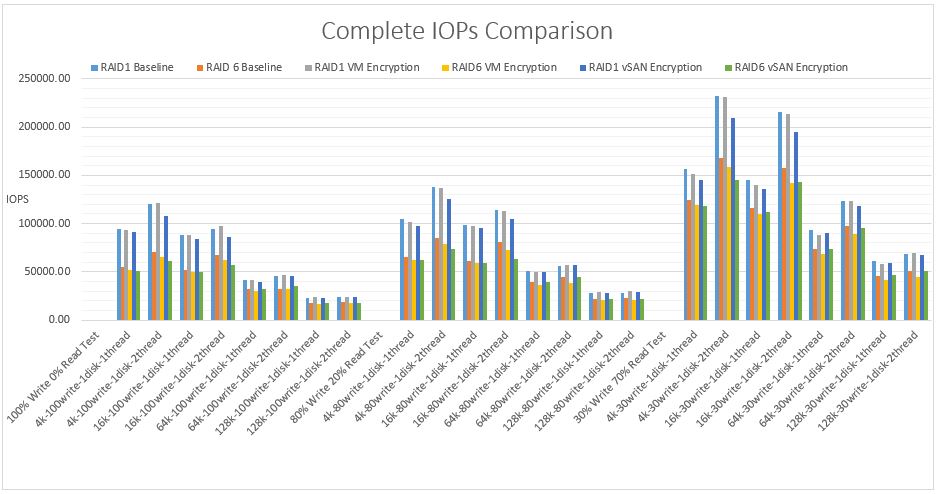
IOPS measures the number of read and write operations per second. The pattern for the 3 different tests is consistent where the heavier write tests show the least IOPs gradually increasing in IOPs as the writes decrease.
IOPS and block size tend to have an inverse relationship. As the block size increases, it takes longer latency to read a single block, and therefore the number of IOPS decreases however, smaller block sizes yield higher IOPS
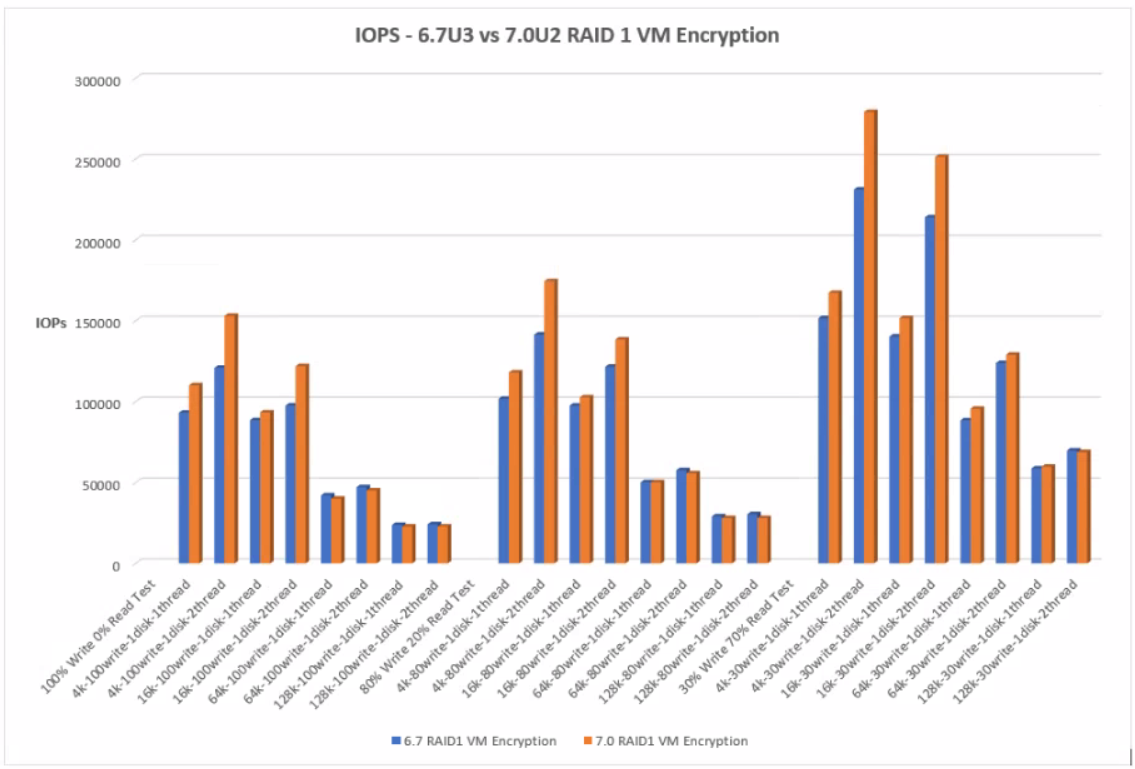
With RAID1 VM Encryption, 7.0U2 performs better than 6.7U3 at the lower block level – 4k and 16k but as we get into the larger 64k and 128k blocks, there is less of a difference with 6.7U3 having the slight edge over IOps performance.
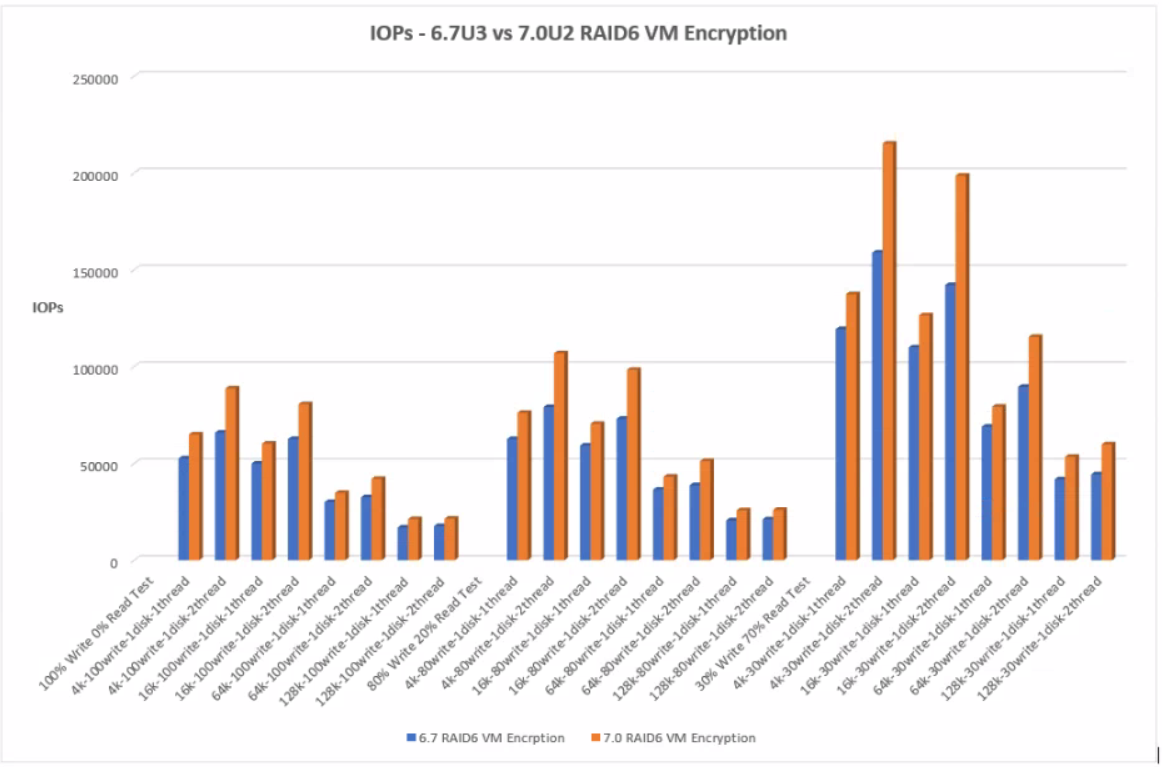
With RAID6 VM Encryption, 7.0U2 has consistently higher IOPS across all tests than 6.7U3.
RAID6 VM Encryption produces less IOPs than RAID1 VM Encryption which is expected due to the increased overhead RAID6 incurs over RAID1 in general. RAID 1 results in 2 writes, one to each mirror. A RAID6 single write operation results in 3 reads and 3 writes (due to double parity) Each write operation requires the disks to read the data, read the first parity, read the second parity, write the data, write the first parity and then finally write the second parity.
RAID 1 VM Encryption
The graph below shows the comparison of IOPs between 6.7U3 and 7.0U2 with RAID 1 VM Encryption
Click the graph for an enlarged view
RAID 6 VM Encryption
The graph below shows the comparison of IOPs between 6.7U3 and 7.0U2 with RAID6 VM Encryption
Click the graph for an enlarged view
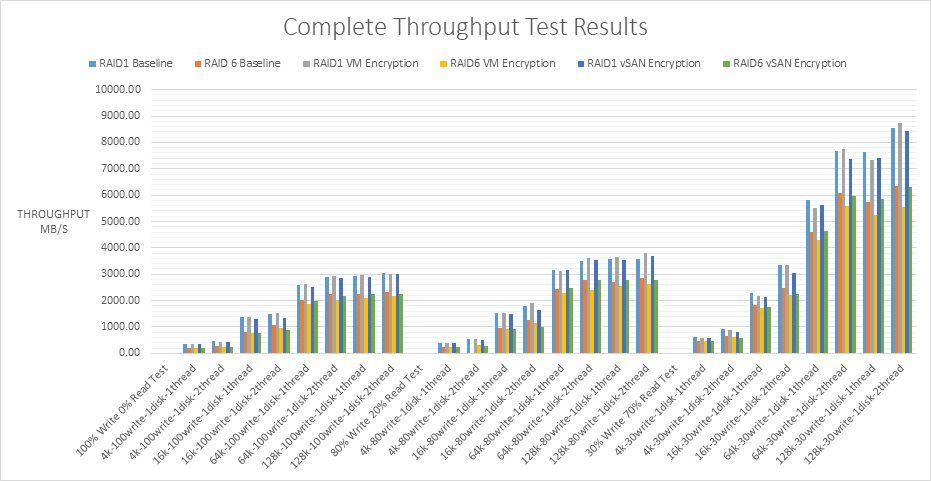
Throughput
IOPs and throughput are closely related by the following equation.
Throughput (MB/s) = IOPS * Block size
IOPS measures the number of read and write operations per second, while throughput measures the number of bits read or written per second. The higher the throughput, the more data which can be transferred. The graphs follow a consistent pattern from the heavier to the lighter workload tests. I can see the larger block sizes such as 64K and 128K have the greater throughput in each of the workload tests than 4K or 8K. As the block sizes get larger in a workload, the number of IOPS will decrease. Even though it’s fewer IOPS, you’re getting more data throughput because the block sizes are bigger. The vSAN datastore is a native 4K system. It’s important to remember that storage systems may be optimized for different block sizes. It is often the operating system and applications which set the block sizes which then run on the underlying storage. It is important to test different block sizes on storage systems to see the effect these have.
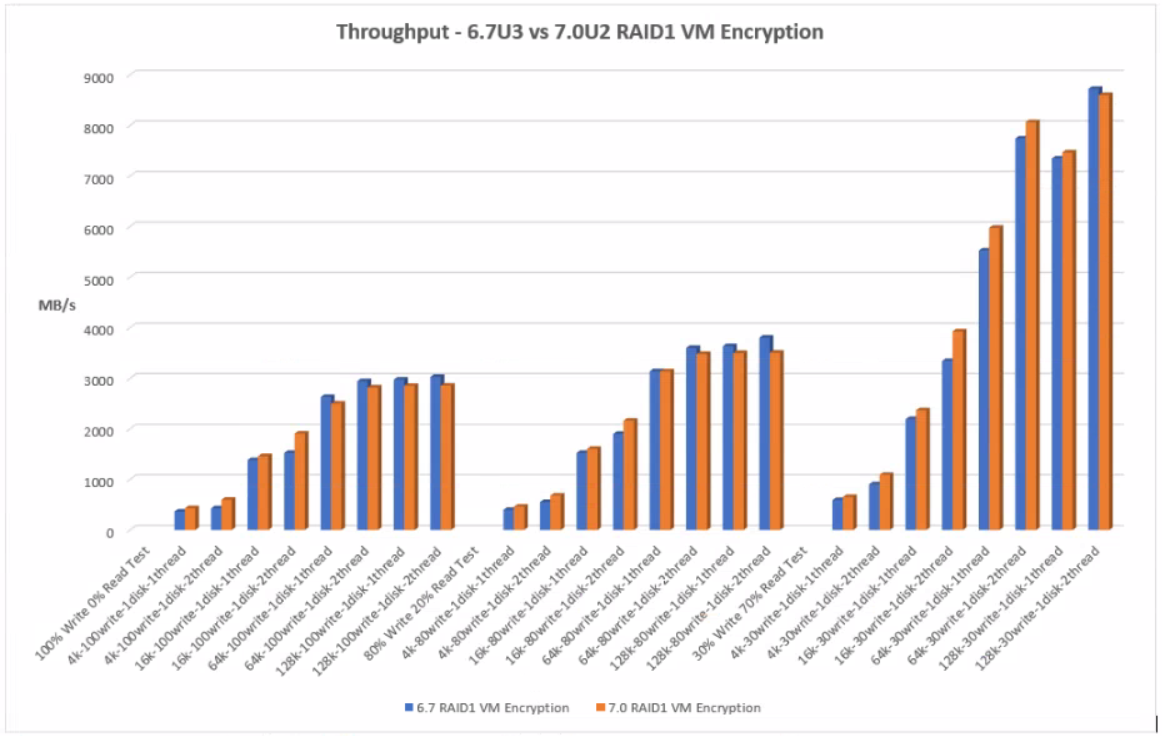
With RAID1 VM Encryption at at lower block sizes, 4k and 16k, 7.0U2 performs better with greater throughput. At the higher block sizes 64k and 128k, there is less of a difference with 6.7U3 performing slightly better but the increase is minimal.
With RAID6 VM Encryption, there is generally a higher throughput at the lower block sizes but not at the higher block sizes
RAID1 VM Encryption
The graph below shows the comparison of throughput between 6.7U3 and 7.0U2 with RAID1 VM Encryption
Click the graph for an enlarged view
RAID6 VM Encryption
The graph below shows the comparison of throughput between 6.7U3 and 7.0U2 with RAID6 VM Encryption
Click the graph for an enlarged view
Average Latency
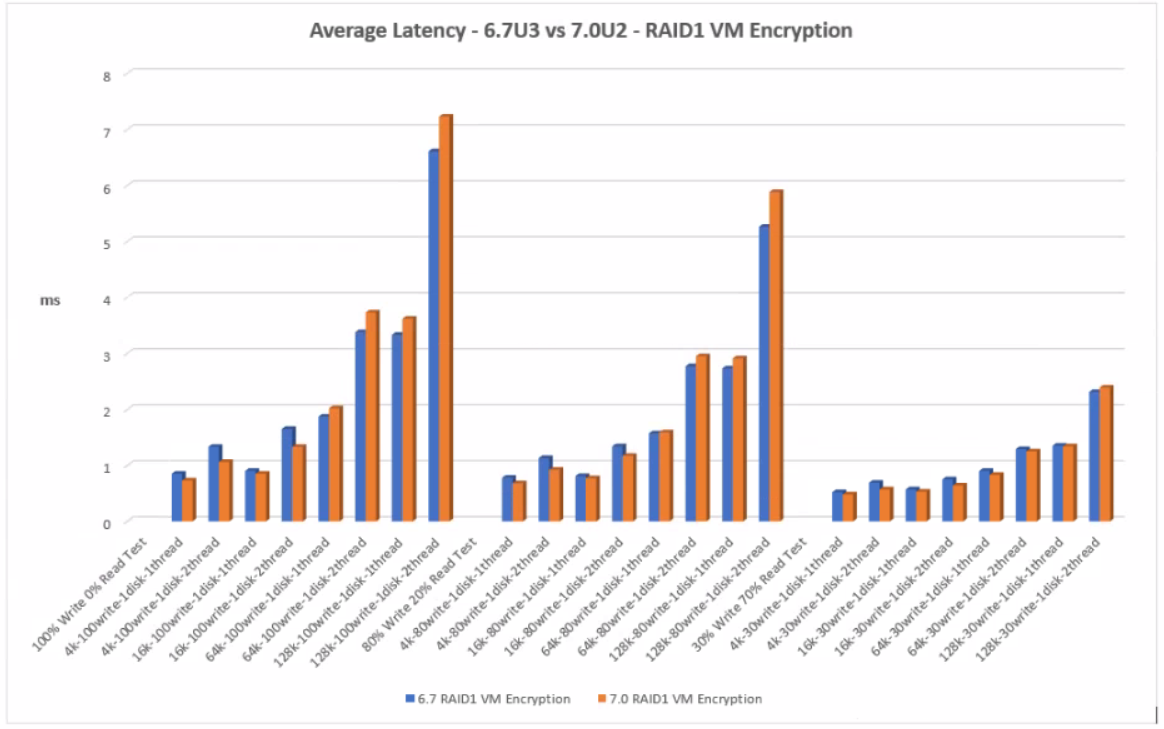
With RAID1 VM Encryption at at lower block sizes, 4k and 16k, 7.0U2 shows less latency but at the higher block sizes there is a slight increase in latency than 6.7U3
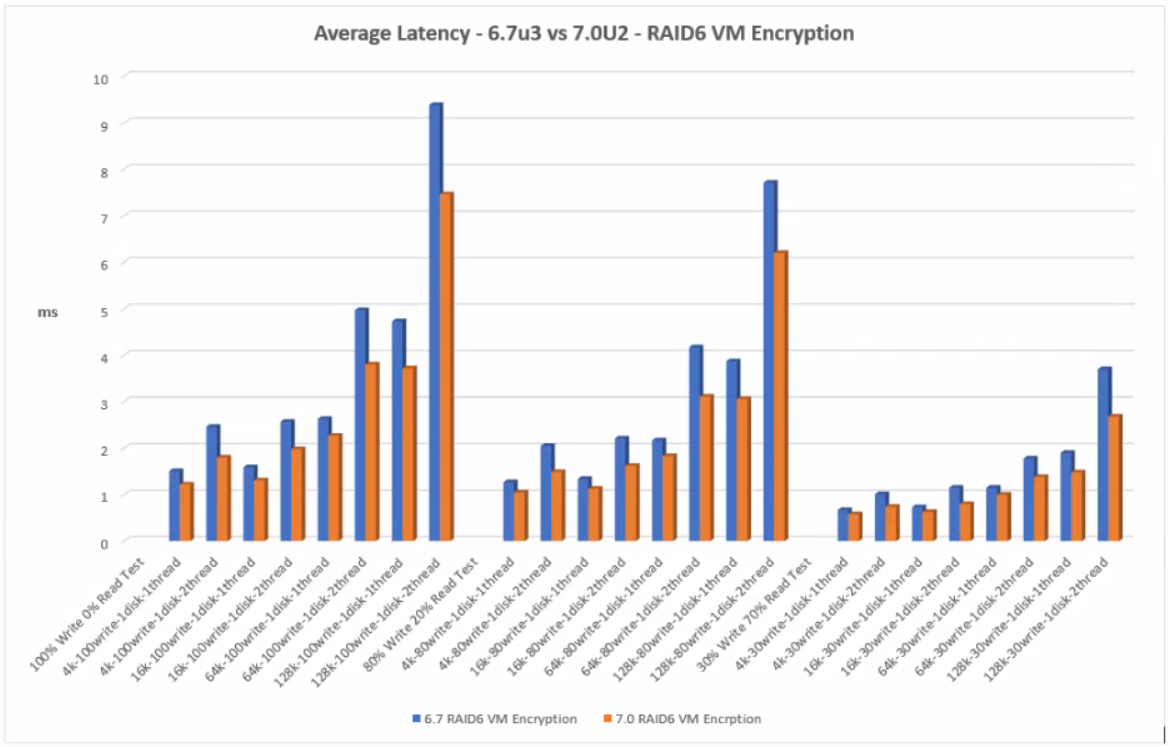
With RAID6 VM Encryption, the 7.0U2 tests are better showing less latency than the 6.7U3 tests
RAID1 VM Encryption
The graph below shows the comparison of average latency between 6.7U3 and 7.0U2 with RAID1 VM Encryption
Click the graph for an enlarged view
RAID6 VM Encryption
The graph below shows the comparison of average latency between 6.7U3 and 7.0U2 with RAID6 VM Encryption
Click the graph for an enlarged view
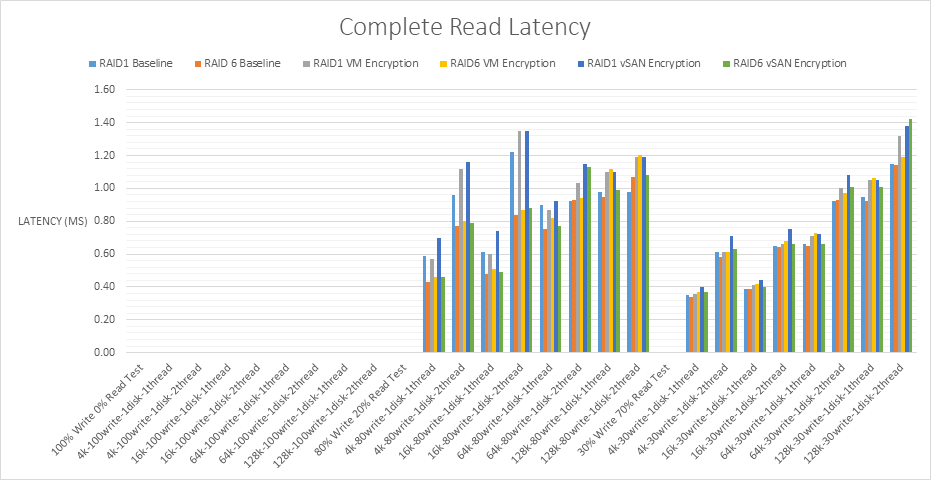
Read Latency
The pattern is consistent between the read/write workloads. As the workload decreases, read latency decreases although the figures are generally quite close. Read latency for all tests varies between 0.30 and 1.40ms which is under a generally recommended limit of 15-20ms before latency starts to cause performance problems.
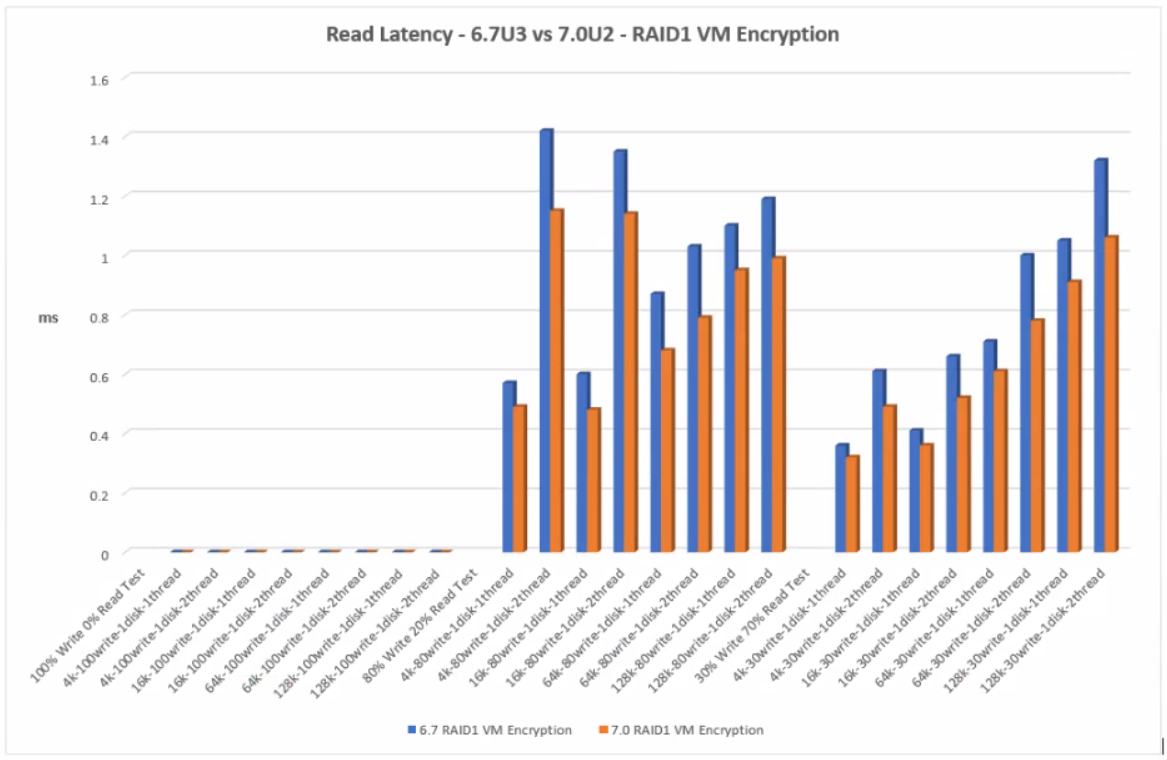
RAID1 VM Encryption shows lower read latency for the 7.0U2 tests than 6.7U3. There are outlier values for the Read Latency across the 4K and 16K block size when testing 2 threads which may be something to note if applications will be used at these block sizes.
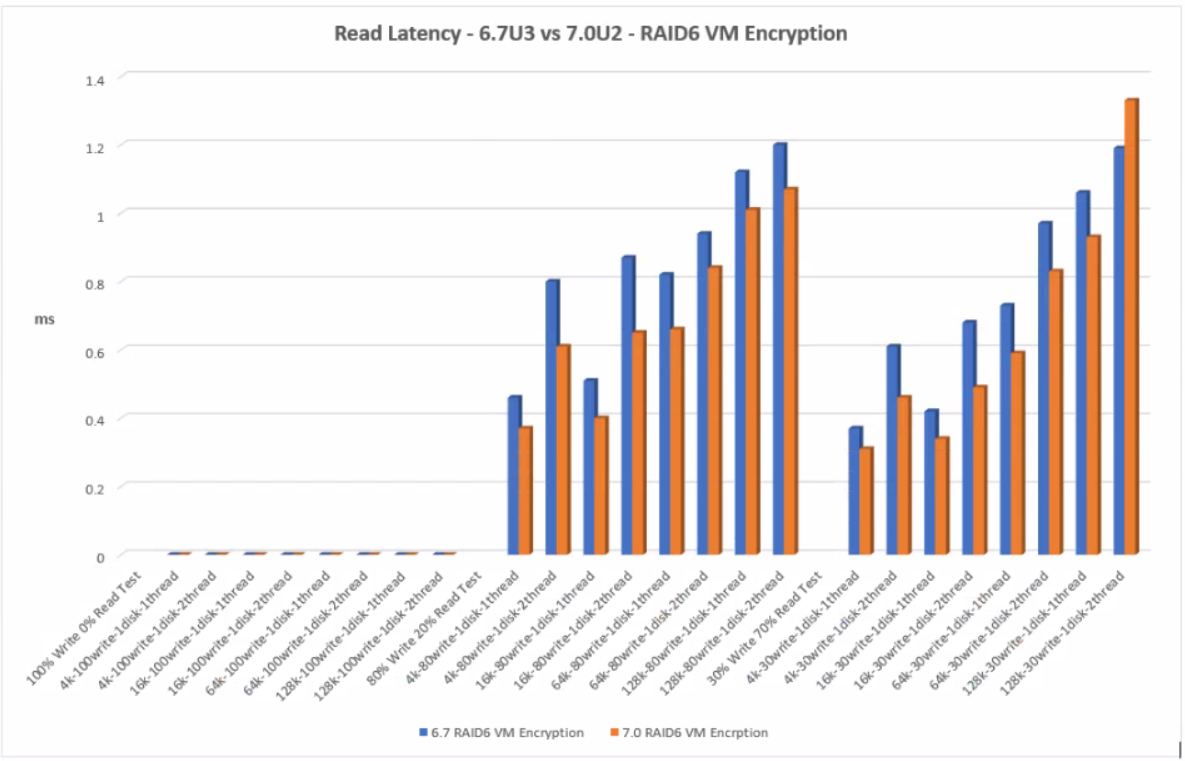
RAID6 shows a slightly better latency result than RAID1 however RAID6 has more disks than mirrored RAID1 disks to read from than RAID1 therefore the reads are very fast which is reflected in the results. Faster reads result in lower latency. Overall 7.0U2 performs better than 6.7U3 apart from one value at the 128k block size with 2 threads which may be an outlier.
RAID1 VM Encryption
Click the graph for an enlarged view
RAID6 VM Encryption
Click the graph for an enlarged view
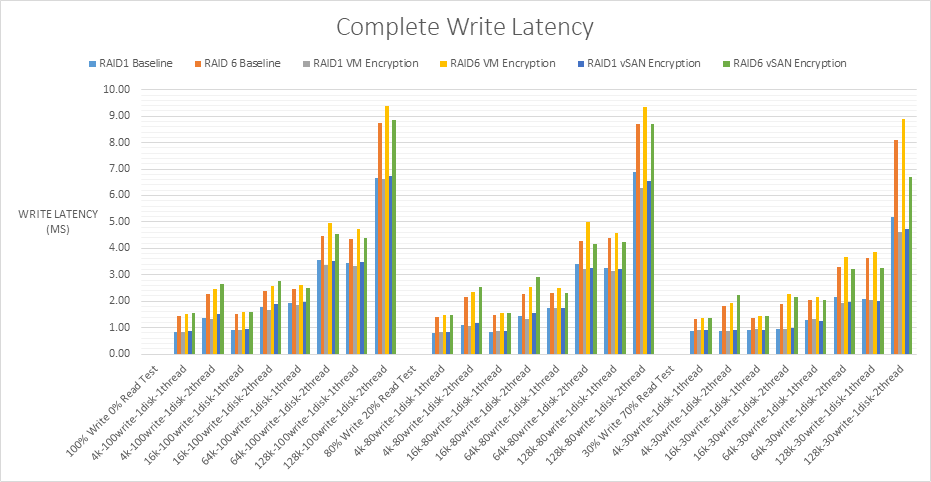
Write Latency
The lowest write latency is 0.72ms and the largest is 9.56ms. Up to 20ms is the recommended value from VMware however with all flash arrays, thse values are expected and well within these limits. With NVMe and flash disks, the faster hardware may expose bottlenecks elsewhere in hardware stack and architecture which can be compared with internal VMware host layer monitoring. Write latency can occur at several virtualization layers and filters which each cause their own latency. The layers can be seen below.
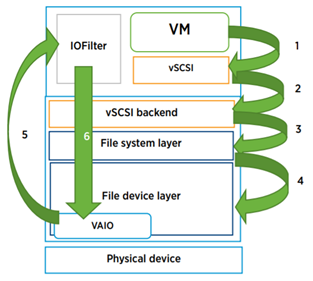
Latency can be caused by limits on the storage controller, queuing at the VMkernel layer, the disk IOPS limit being reached and the types of workloads being run possibly alongside other types of workloads which cause more processing.
With RAID1 Encryption, 7.0U2 performed better at the lower block size with less write latency than 6.7U3. However on the higher block sizes, 64k and 128k, 6.7U3 performs slightly better but we are talking 1-2ms.
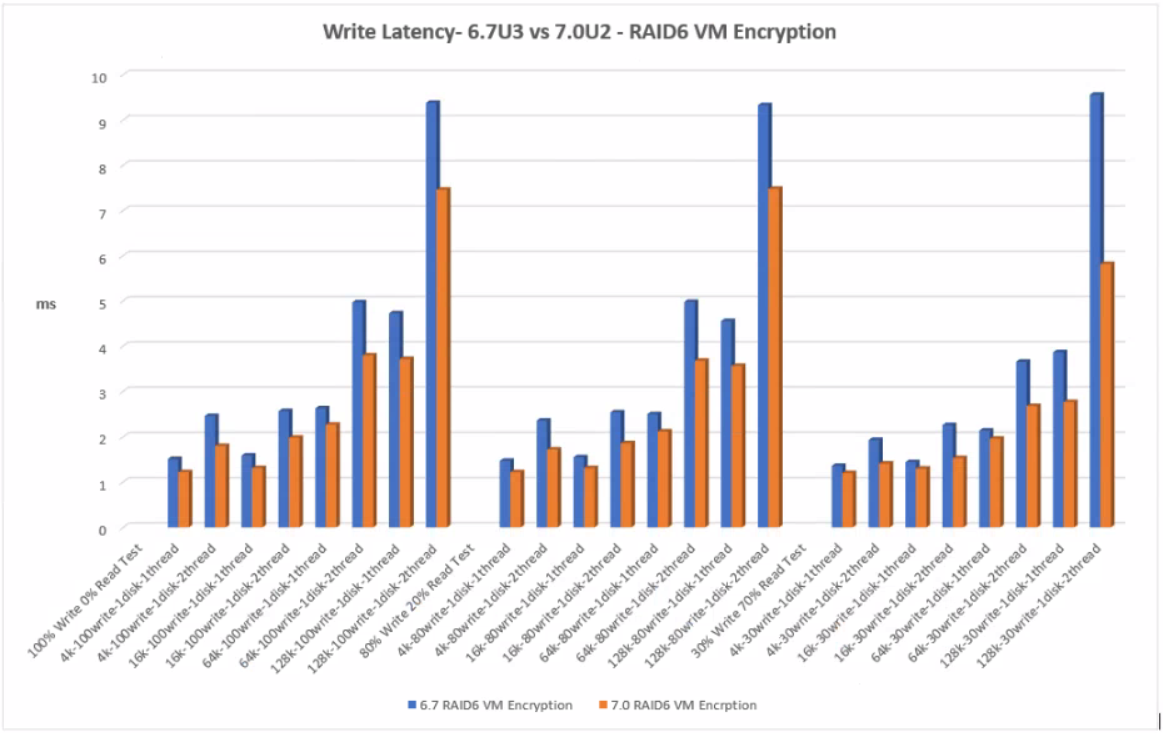
With RAID6 VM Encryption, 7.0U2 performed well with less latency across all tests than 6.7U3.
As expected, all the RAID6 results incurred more write latency than the RAID1 results. Each RAID6 write operation requires the disks to read the data, read the first parity, read the second parity, write the data, write the first parity and then finally write the second parity producing a heavy write penalty and therefore more latency
RAID1 VM Encryption
Click the graph for an enlarged view
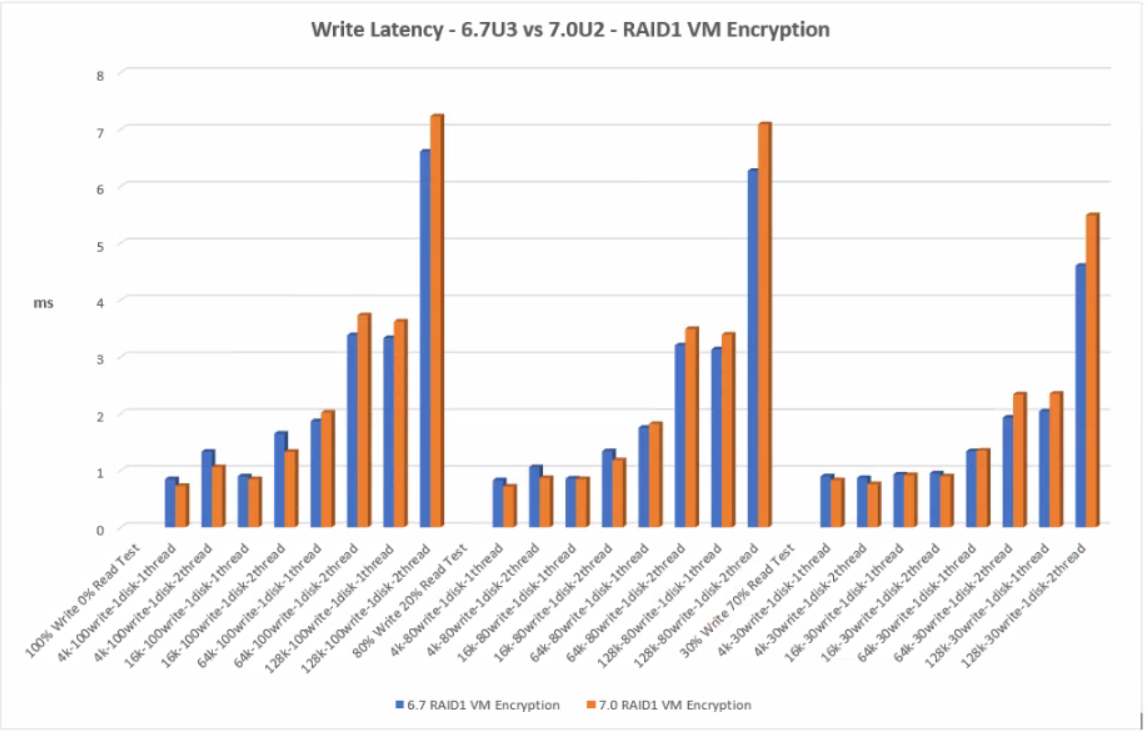
RAID6 VM Encryption
Click the graph for an enlarged view
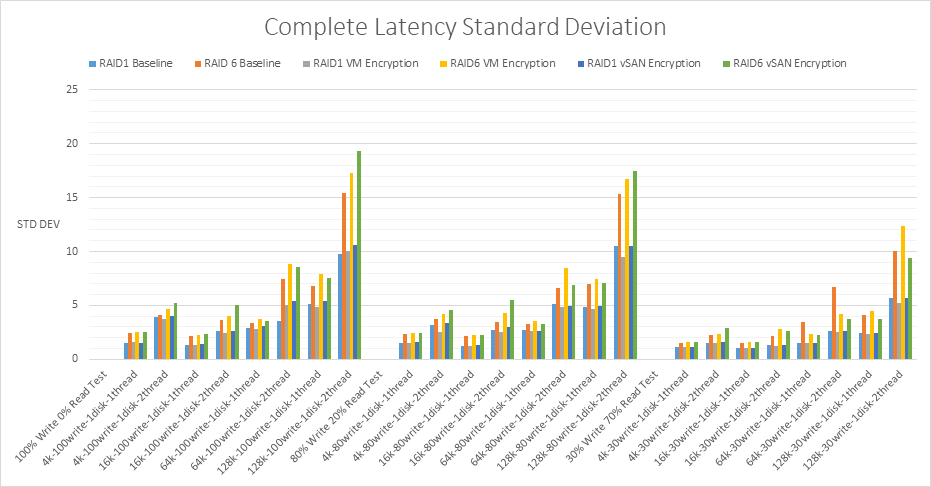
Latency Standard Deviation
The standard deviation value in the testing results uses a 95th percentile. This is explained below with examples.
- An average latency of 2ms and a 95th percentile of 6ms means that 95% of the IO were serviced under 6ms, and that would be a good result
- An average latency of 2ms and a 95th percentile latency of 200ms means 95% of the IO were serviced under 200ms (keeping in mind that some will be higher than 200ms). This means that latencies are unpredictable and some may take a long time to complete. An operation could take less than 2ms, but every once in a while, it could take well over 200
- Assuming a good average latency, it is typical to see the 95th percentile latency no more than 3 times the average latency.
With RAID1 Encryption, 7.0U2 performed better at the lower block size with less latency standard deviation than 6.7U3. However on the higher block sizes, 64k and 128k, 6.7U3 performs slightly better.
With RAID 6 VM Encryption, 7.0U2 performed with less standard deviation across all the tests.
RAID1 VM Encryption
Click the graph for an enlarged view
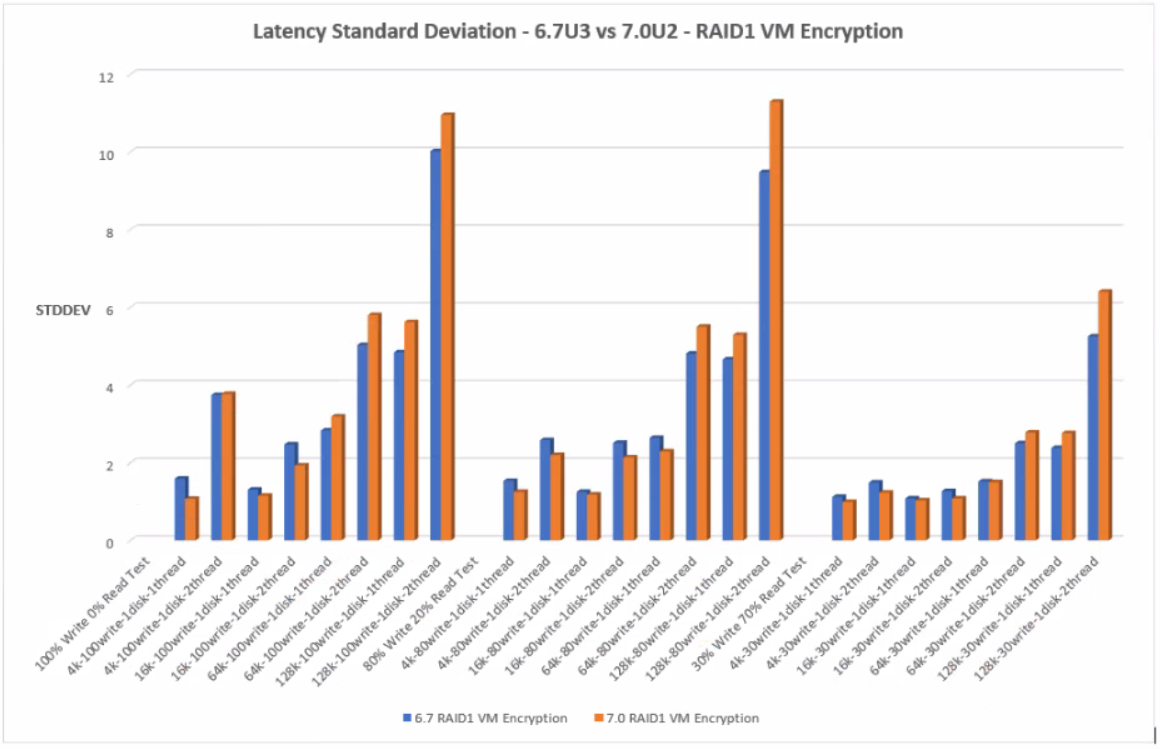
RAID6 VM Encryption
Click the graph for an enlarged view
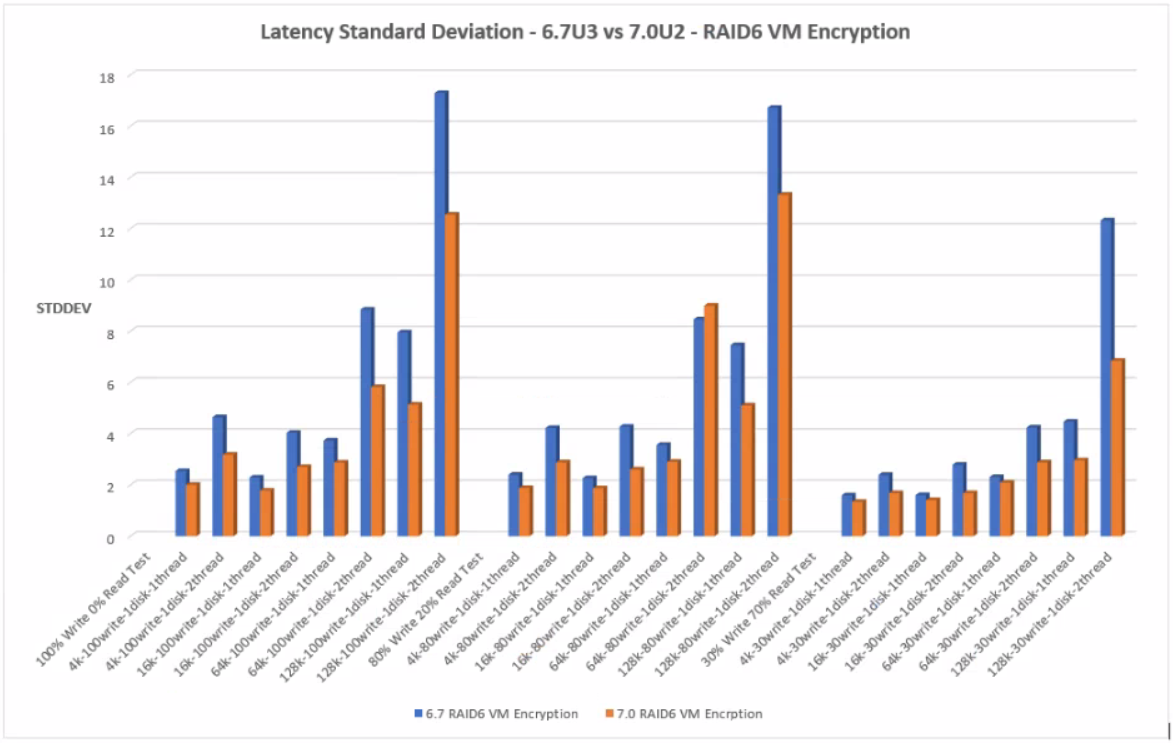
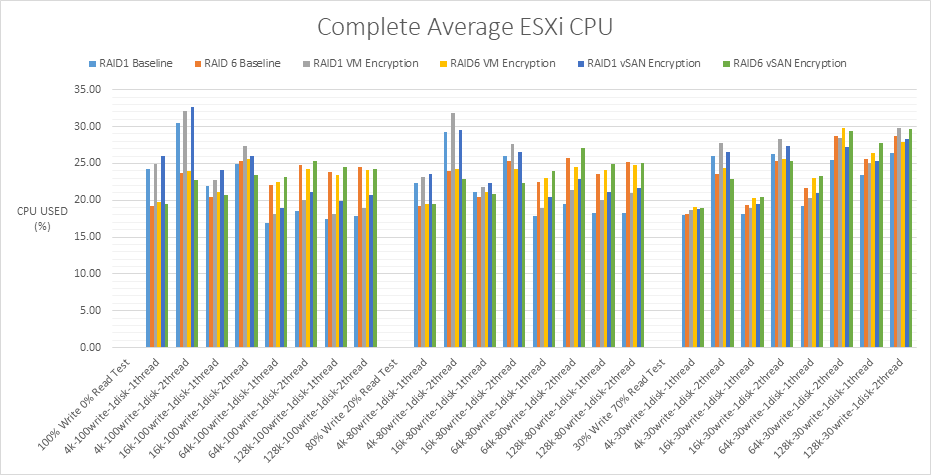
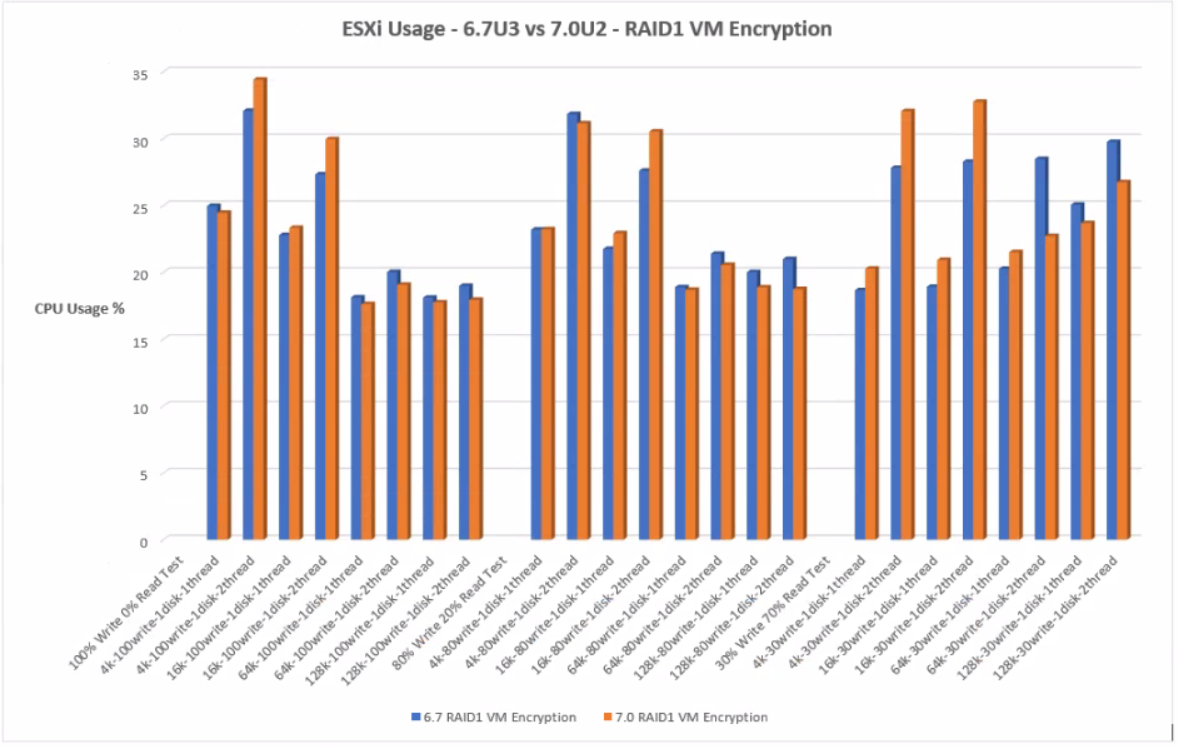
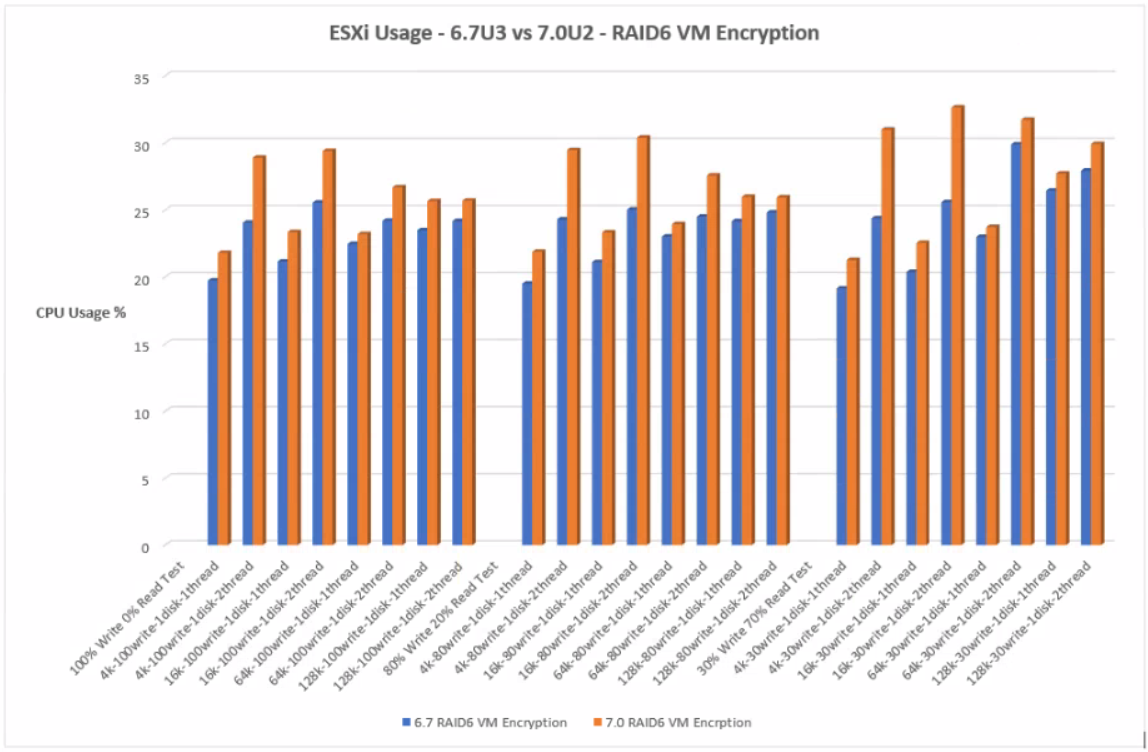
ESXi CPU Usage %
With RAID1 VM Encryption, at the lower block sizes, 4k and 16k, 7.0U2 uses more CPU but at the higher block sizes, 7.0U2 uses slightly less CPU usage.
With RAID6 VM Encryption, there is an increase in CPU usage across all 7.0U2 compared to 6.7U3 tests. RAID 6 has a higher computational penalty than RAID1.
RAID1 VM Encryption
Click the graph for an enlarged view
RAID6 VM Encryption
Click the graph for an enlarged view
Conclusion
The performance tests were designed to get an overall view from a low workload test of 30% Write, 70% Read through a series of increasing workload tests of 80% Write, 20% Read and 100% Write, 0% Read simulation. These tests used different block sizes to simulate different application block sizes. Testing was carried out on an all flash RAID1 and RAID6 vSAN datastore to compare the performance for VM encryption between ESXi 6.7U3 and 7.0U2. The environment was set up to vendor best practice across vSphere ESXi, vSAN, vCenter and the Dell server configuration.
RAID1 VM Encryption
- With 6.7U3, IOPs at the higher block sizes, 64k and 128k can be slightly better than 7.0U2 but not at lower block sizes.
- With 6.7U3, throughput at the higher block sizes, 64k and 128k can be slightly better than 7.0U2 but not at lower block sizes
- Overall latency for 6.7U3 at the higher block sizes, 64k and 128k can be slightly better than 7.0U2 but not for the lower block size
- Read latency for 6.7U3 is higher than 7.0U2.
- Write latency at the higher block sizes, 64k and 128k can be slightly better than 7.0U2 but not for the lower block sizes.
- There is more standard deviation for 6.7U3 then 7.0U2.
- At the lower blocks sizes, 6.7U3 uses less CPU on the whole but at the higher block sizes, 7.0U2 uses less CPU
RAID6 VM Encryption
- There are higher IOPs for 7.0U2 than 6.7U3 across all tests.
- There is generally a higher throughput for 7.0U2 at the lower block sizes, than 6.7U3 but not at the higher block sizes. However, the difference is minimal.
- There is lower overall latency for 7.0U2 than 6.7U3 across all tests
- There is lower read latency for 7.0U2 than 6.7U3 across all tests
- There is lower write latency for 7.0U2 than 6.7U3 across all tests
- There is less standard deviation for 7.0U2 than 6.7U3 across all tests
- There is a higher CPU % usage for 7.0U2 than 6.7U3 across all tests
With newer processors, AES improvements, memory improvements, RDMA NICs and storage controller driver improvements, we may see further performance improvements in new server models.