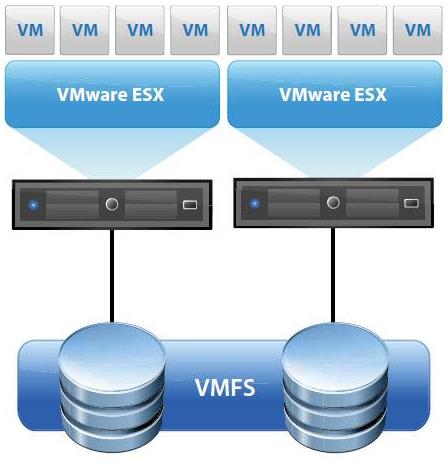
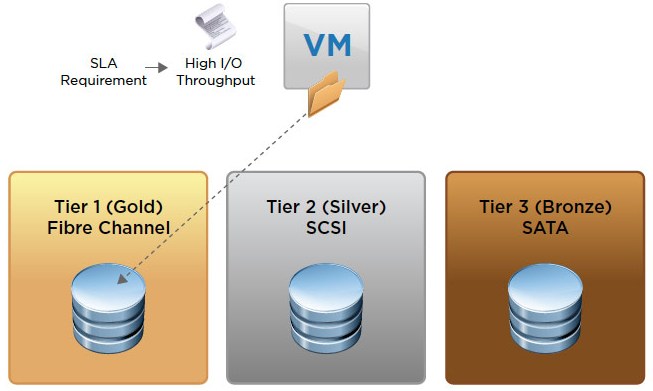
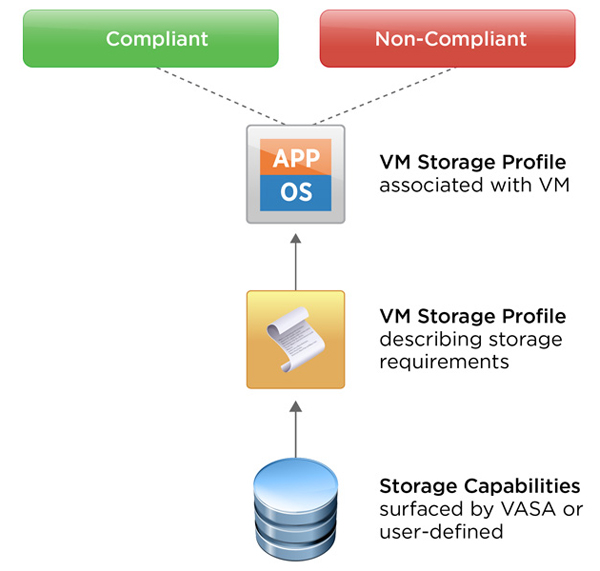
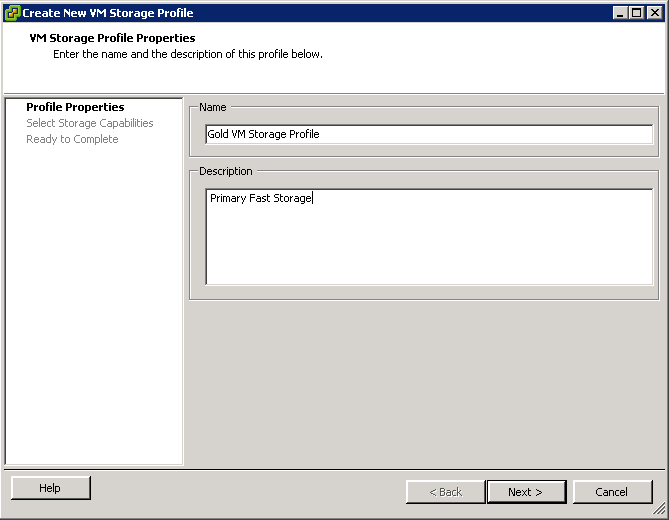
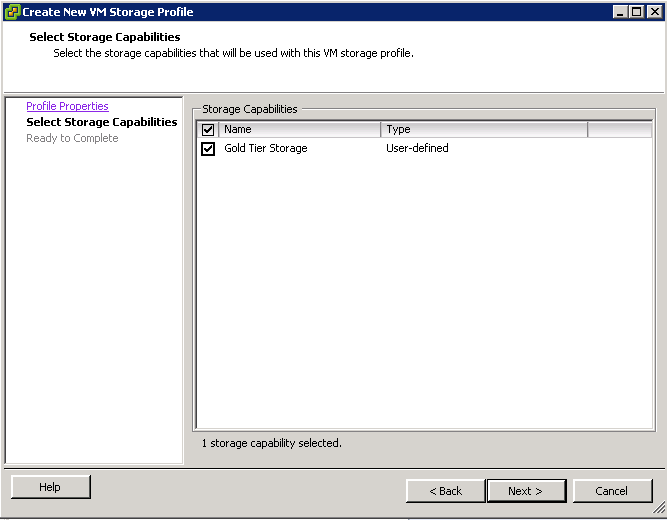
Overview of Storage Provisioning methods
Types of Storage
Local (Block Storage)
Local storage can be internal hard disks located inside your ESXi host, or it can be external storage systems located outside and connected to the host directly through protocols such as SAS or SATA. The host uses a single connection to a storage disk. On that disk,
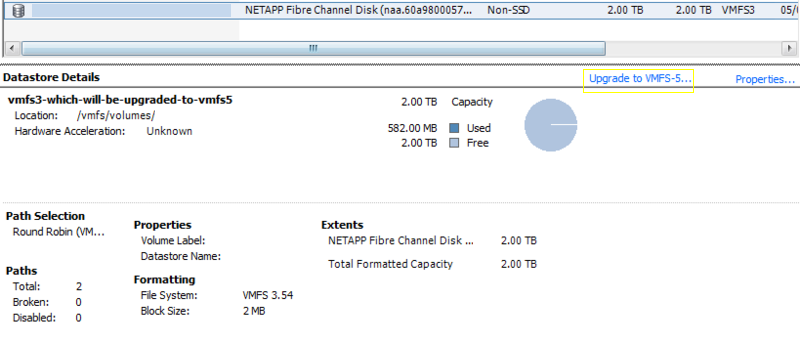
you can create a VMFS Datastore, which you use to store virtual machine disk files.Although this storage configuration is possible, it is not a recommended topology. Using single connections between storage arrays and hosts creates single points of failure (SPOF) that can cause interruptions when a connection becomes unreliable or fails.
ESXi supports a variety of internal or external local storage devices, including SCSI, IDE, SATA, USB, and SAS storage systems. Regardless of the type of storage you use, your host hides a physical storage layer from virtual machines
Networked Storage
Networked storage consists of external storage systems that your ESXi host uses to store virtual machine files remotely. Typically, the host accesses these systems over a high-speed storage network.
Networked storage devices are shared. Datastores on networked storage devices can be accessed by multiple hosts concurrently. ESXi supports the following networked storage technologies.
FC (Block Storage)
Stores virtual machine files remotely on an FC storage area network (SAN). FC SAN is a specialized high-speed network that connects your hosts to high-performance storage devices. The network uses Fibre Channel protocol to transport SCSI traffic from virtual machines to the FC SAN devices.
To connect to the FC SAN, your host should be equipped with Fibre Channel host bus adapters (HBAs). Unless you use Fibre Channel direct connect storage, you need Fibre Channel switches to route storage traffic.
FCOE (Block Storage)
If your host contains FCoE (Fibre Channel over Ethernet) adapters, you can connect to your shared Fibre Channel devices by using an Ethernet network.
Internet SCSI (iSCSI) (Block Storage)
Stores virtual machine files on remote iSCSI storage devices. iSCSI packages SCSI storage traffic into the TCP/IP protocol so that it can travel through standard TCP/IP networks instead of the specialized FC network. With an iSCSI connection, your host serves as the initiator that communicates with a target, located in remote iSCSI storage systems. ESXi offers the following types of iSCSI connections:
- Hardware iSCSI Your host connects to storage through a third-party adapter capable of offloading the iSCSI and network processing. Hardware adapters can be dependent and independent. This is shown on the left adapter on the picture below
- Software iSCSI Your host uses a software-based iSCSI initiator in the VMkernel to connect to storage. With this type of iSCSI connection, your host needs only a standard network adapter for network connectivity. This is shown on the right adapter on the picture below
Network-attached Storage (NAS) (File Level Storage)
Stores virtual machine files on remote file servers accessed over a standard TCP/IP network. The NFS client built into ESXi uses Network File System (NFS) protocol version 3 to communicate with the NAS/NFS servers. For network connectivity, the host requires a standard network adapter.
Comparison of Storage Features
Predictive and Adaptive Schemes for Datastores
When setting up storage for ESXi systems, before creating VMFS datastores, you must decide on the size and number of LUNs to provision. You can experiment using the predictive scheme and the Adaptive Scheme
Predictive
- Provision several LUNs with different storage characteristics.
- Create a VMFS datastore on each LUN, labeling each datastore according to its characteristics.
- Create virtual disks to contain the data for virtual machine applications in the VMFS datastores created on LUNs with the appropriate RAID level for the applications’ requirements.
- Use disk shares to distinguish high-priority from low-priority virtual machines.
NOTE: Disk shares are relevant only within a given host. The shares assigned to virtual machines on one host have no effect on virtual machines on other hosts.
- Run the applications to determine whether virtual machine performance is acceptable.
Adaptive
When setting up storage for ESXi hosts, before creating VMFS datastores, you must decide on the number and size of LUNS to provision. You can experiment using the adaptive scheme.
- Provision a large LUN (RAID 1+0 or RAID 5), with write caching enabled.
- Create a VMFS on that LUN.
- Create four or five virtual disks on the VMFS.
- Run the applications to determine whether disk performance is acceptable
- If performance is acceptable, you can place additional virtual disks on the VMFS. If performance is not acceptable, create a new, large LUN, possibly with a different RAID level, and repeat the process. Use migration so that you do not lose virtual machines data when you recreate the LUN.
Tools for provisioning storage
- vClient
- Web Client
- vmkfstools
- SAN Vendor Tools
VMware Link
http://www.vmware.com/files/pdf/techpaper/Storage_Protocol_Comparison.pdf