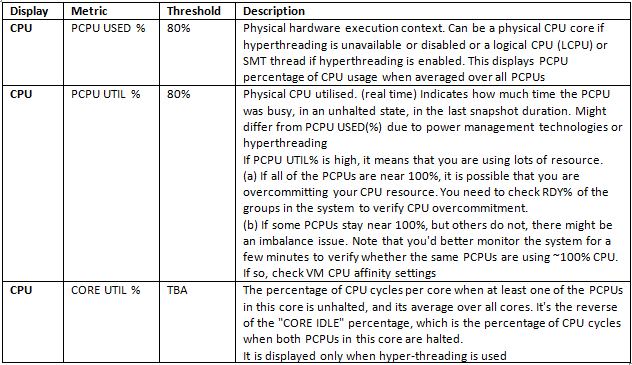
VMware® ESX(i)™ is a hypervisor designed to efficiently manage hardware resources including CPU, memory, storage, and network among multiple, concurrent virtual machines.
Memory Overcommittment
The concept of memory overcommitment is fairly simple: host memory is overcommitted when the total amount of guest physical memory of the running virtual machines is larger than the amount of actual host memory. ESX supports memory overcommitment from the very first version, due to two important benefits it provides:
- Higher memory utilization: With memory overcommitment, ESX ensures that host memory is consumed by active guest memory as much as possible. Typically, some virtual machines may be lightly loaded compared to others. Their memory may be used infrequently, so for much of the time their memory will sit idle. Memory overcommitment allows the hypervisor to use memory reclamation techniques to take the inactive or unused host physical memory away from the idle virtual machines and give it to other virtual machines that will actively use it.
- Higher consolidation ratio: With memory overcommitment, each virtual machine has a smaller footprint in host memory usage, making it possible to fit more virtual machines on the host while still achieving good performance for all virtual machines. For example, as shown in Figure 3, you can enable a host with 4G host physical memory to run three virtual machines with 2G guest physical memory each. Without memory overcommitment, only one virtual machine can be run because the hypervisor cannot reserve host memory for more than one virtual machine, considering that each virtual machine has overhead memory.
ESX uses several innovative techniques to reclaim virtual machine memory, which are:
- Transparent page sharing (TPS)
- Reclaims memory by removing redundant pages with identical content
- Ballooning
- Reclaims memory by artificially increasing the memory pressure inside the guest
- Hypervisor/Host swapping
- Reclaims memory by having ESX directly swap out the virtual machine’s memory
- Memory compression
- Reclaims memory by compressing the pages that need to be swapped out
Transparent Page Sharing
When multiple virtual machines are running, some of them may have identical sets of memory content. This presents opportunities for sharing memory across virtual machines (as well as sharing within a single virtual machine). For example, several virtual machines may be running the same guest operating system, have the same applications, or contain the same user data. With page sharing, the hypervisor can reclaim the redundant copies and keep only one copy, which is shared by multiple virtual machines in the host physical memory. As a result, the total virtual machine host memory consumption is reduced and a higher level of memory overcommitment is possible.
In ESX, the redundant page copies are identified by their contents. This means that pages with identical content can be shared regardless of when, where, and how those contents are generated. ESX scans the content of guest physical memory for sharing opportunities. Instead of comparing each byte of a candidate guest physical page to other pages, an action that is prohibitively expensive, ESX uses hashing to identify potentially identical pages.

A hash value is generated based on the candidate guest physical page’s content. The hash value is then used as a key to look up a global hash table, in which each entry records a hash value and the physical page number of a shared page. If the hash value of the candidate guest physical page matches an existing entry, a full comparison of the page contents is performed to exclude a false match. Once the candidate guest physical page’s content is confirmed to match the content of an existing shared host physical page, the guest physical to host physical mapping of the candidate guest physical page is changed to the shared host physical page, and the redundant host memory copy (the page pointed to by the dashed arrow in the Figure above) is reclaimed. This remapping is invisible to the virtual machine and inaccessible to the guest operating system. Because of this invisibility, sensitive information cannot be leaked from one virtual machine to another.
A standard copy-on-write (CoW) technique is used to handle writes to the shared host physical pages. Any attempt to write to the shared pages will generate a minor page fault. In the page fault handler, the hypervisor will transparently create a private copy of the page for the virtual machine and remap the affected guest physical page to this private copy. In this way, virtual machines can safely modify the shared pages without disrupting other virtual machines sharing that memory. Note that writing to a shared page does incur overhead compared to writing to non-shared pages due to the extra work performed in the page fault handler.
In VMware ESX, the hypervisor scans the guest physical pages randomly with a base scan rate specified by Mem.ShareScanTime, which specifies the desired time to scan the virtual machine’s entire guest memory. The maximum number of scanned pages per second in the host and the maximum number of per-virtual machine scanned pages, (that is, Mem.ShareScanGHz and Mem.ShareRateMax respectively) can also be specified in ESX advanced settings. An example is shown in the Figure below

The default values of these three parameters are carefully chosen to provide sufficient sharing opportunities while keeping the CPU overhead negligible. In fact, ESX intelligently adjusts the page scan rate based on the amount of current shared pages. If the virtual machine’s page sharing opportunity seems to be low, the page scan rate will be reduced accordingly and vice versa. This optimization further mitigates the overhead of page sharing.
In hardware-assisted memory virtualization (for example, Intel EPT Hardware Assist and AMD RVI Hardware Assist systems, ESX will automatically back guest physical pages with large host physical pages (2MB contiguous memory region instead of 4KB for regular pages) for better performance due to less TLB misses. In such systems, ESX will not share those large pages because: 1) the probability of finding two large pages having identical contents is low, and 2) the overhead of doing a bit-by-bit comparison for a 2MB page is much larger than for a 4KB page. However, ESX still generates hashes for the 4KB pages within each large page. Since ESX will not swap out large pages, during host swapping, the large page will be broken into small pages so that these pre-generated hashes can be used to share the small pages before they are swapped out. In short, we may not observe any page sharing for hardware-assisted memory virtualization systems until host memory is overcommitted.
Ballooning
Ballooning is a completely different memory reclamation technique compared to transparent page sharing. Before describing the technique, it is helpful to review why the hypervisor needs to reclaim memory from virtual machines. Due to the virtual machine’s isolation, the guest operating system is not aware that it is running inside a virtual machine and is not aware of the states of other virtual machines on the same host. When the hypervisor runs multiple virtual machines and the total amount of the free host memory becomes low, none of the virtual machines will free guest physical memory because the guest operating system cannot detect the host’s memory shortage. Ballooning makes the guest operating system aware of the low memory status of the host.
In ESX, a balloon driver is loaded into the guest operating system as a pseudo-device driver.
VMware Tools must be installed in order to enable ballooning. This is recommended for all workloads. It has no external interfaces to the guest operating system and communicates with the hypervisor through a private channel. The balloon driver polls the hypervisor to obtain a target balloon size. If the hypervisor needs to reclaim virtual machine memory, it sets a proper target balloon size for the balloon driver, making it “inflate” by allocating guest physical pages within the virtual machine. The figure below illustrates the process of the balloon inflating
In the figure below, four guest physical pages are mapped in the host physical memory. Two of the pages are used by the guest application and the other two pages (marked by stars) are in the guest operating system free list. Note that since the hypervisor cannot identify the two pages in the guest free list, it cannot reclaim the host physical pages that are backing them. Assuming the hypervisor needs to reclaim two pages from the virtual machine, it will set the target balloon size to two pages. After obtaining the target balloon size, the balloon driver allocates two guest physical pages inside the virtual machine and pins them, as shown in Figure b. Here, “pinning” is achieved through the guest operating system interface, which ensures that the pinned pages cannot be paged out to disk under any circumstances. Once the memory is allocated, the balloon driver notifies the hypervisor about the page numbers of the pinned guest physical memory so that the hypervisor can reclaim the host physical pages that are backing them. In Figure b, dashed arrows point at these pages. The hypervisor can safely reclaim this host physical memory because neither the balloon driver nor the guest operating system relies on the contents of these pages. This means that no processes in the virtual machine will intentionally access those pages to read/write any values. Thus, the hypervisor does not need to allocate host physical memory to store the page contents. If any of these pages are re-accessed by the virtual machine for some reason, the hypervisor will treat it as a normal virtual machine memory allocation and allocate a new host physical page for the virtual machine. When the hypervisor decides to deflate the balloon—by setting a smaller target balloon size—the balloon driver deallocates the pinned guest physical memory, which releases it for the guest’s applications.

Typically, the hypervisor inflates the virtual machine balloon when it is under memory pressure. By inflating the balloon, a virtual machine consumes less physical memory on the host, but more physical memory inside the guest. As a result, the hypervisor offloads some of its memory overload to the guest operating system while slightly loading the virtual machine. That is, the hypervisor transfers the memory pressure from the host to the virtual machine. Ballooning induces guest memory pressure. In response, the balloon driver allocates and pins guest physical memory. The guest operating system determines if it needs to page out guest physical memory to satisfy the balloon driver’s allocation requests. If the virtual machine has plenty of free guest physical memory, inflating the balloon will induce no paging and will not impact guest performance. In this case, as illustrated in the figure, the balloon driver allocates the free guest physical memory from the guest free list. Hence, guest-level paging is not necessary. However, if the guest is already under memory pressure, the guest operating system decides which guest physical pages to be paged out to the virtual swap device in order to satisfy the balloon driver’s allocation requests. The genius of ballooning is that it allows the guest operating system to intelligently make the hard decision about which pages to be paged out without the hypervisor’s involvement.
Hypervisor/Host Swapping
In the cases where ballooning and transparent page sharing are not sufficient to reclaim memory, ESX employs hypervisor swapping to reclaim memory. At virtual machine startup, the hypervisor creates a separate swap file for the virtual machine. Then, if necessary, the hypervisor can directly swap out guest physical memory to the swap file, which frees host physical memory for other virtual machines.
Besides the limitation on the reclaimed memory size, both page sharing and ballooning take time to reclaim memory. The page-sharing speed depends on the page scan rate and the sharing opportunity. Ballooning speed relies on the guest operating system’s response time for memory allocation.
In contrast, hypervisor swapping is a guaranteed technique to reclaim a specific amount of memory within a specific amount of time. However, hypervisor swapping is used as a last resort to reclaim memory from the virtual machine due to the following limitations on performance:
- Page selection problems: Under certain circumstances, hypervisor swapping may severely penalize guest performance. This occurs when the hypervisor has no knowledge about which guest physical pages should be swapped out, and the swapping may cause unintended interactions with the native memory management policies in the guest operating system.
- Double paging problems: Another known issue is the double paging problem. Assuming the hypervisor swaps out a guest physical page, it is possible that the guest operating system pages out the same physical page, if the guest is also under memory pressure. This causes the page to be swapped in from the hypervisor swap device and immediately to be paged out to the virtual machine’s virtual swap device.
Page selection and double-paging problems exist because the information needed to avoid them is not available to the hypervisor.
- High swap-in latency: Swapping in pages is expensive for a VM. If the hypervisor swaps out a guest page and the guest subsequently accesses that page, the VM will get blocked until the page is swapped in from disk. High swap-in latency, which can be tens of milliseconds, can severely degrade guest performance.
ESX mitigates the impact of interacting with guest operating system memory management by randomly selecting the swapped guest physical pages.
Memory Compression
The idea of memory compression is very straightforward: if the swapped out pages can be compressed and stored in a compression cache located in the main memory, the next access to the page only causes a page decompression which can be an order of magnitude faster than the disk access. With memory compression, only a few uncompressible pages need to be swapped out if the compression cache is not full. This means the number of future synchronous swap-in operations will be reduced. Hence, it may improve application performance significantly when the host is in heavy memory pressure. In ESX 4.1, only the swap candidate pages will be compressed. This means ESX will not proactively compress guest pages when host swapping is not necessary. In other words, memory compression does not affect workload performance when host memory is undercommitted.
Reclaiming Memory through Compression
Figure a,b and c illustrates how memory compression reclaims host memory compared to host swapping. Assuming ESX needs to reclaim two 4KB physical pages from a VM through host swapping, page A and B are the selected pages (Figure a,b,c). With host swapping only, these two pages will be directly swapped to disk and two physical pages are reclaimed (Figure b). However, with memory compression, each swap candidate page will be compressed and stored using 2KB of space in a per-VM compression cache. Note that page compression would be much faster than the normal page swap out operation which involves a disk I/O. Page compression will fail if the compression ratio is less than 50% and the uncompressible pages will be swapped out. As a result, every successful page compression is accounted for reclaiming 2KB of physical memory. As illustrated in Figure c, pages A and B are compressed and stored as half-pages in the compression cache. Although both pages are removed from VM guest memory, the actual reclaimed memory size is one page.

If any of the subsequent memory access misses in the VM guest memory, the compression cache will be checked first using the host physical page number. If the page is found in the compression cache, it will be decompressed and push back to the guest memory. This page is then removed from the compression cache. Otherwise, the memory request is sent to the host swap device and the VM is blocked.
Managing Per-VM Compression Cache
The per-VM compression cache is accounted for by the VM’s guest memory usage, which means ESX will not allocate additional host physical memory to store the compressed pages. The compression cache is transparent to the guest OS. Its size starts with zero when host memory is undercommitted and grows when virtual machine memory starts to be swapped out.
If the compression cache is full, one compressed page must be replaced in order to make room for a new compressed page. An age-based replacement policy is used to choose the target page. The target page will be decompressed and swapped out. ESX will not swap out compressed pages.
If the pages belonging to compression cache need to be swapped out under severe memory pressure, the compression cache size is reduced and the affected compressed pages are decompressed and swapped out.
The maximum compression cache size is important for maintaining good VM performance. If the upper bound is too small, a lot of replaced compressed pages must be decompressed and swapped out. Any following swap-ins of those pages will hurt VM performance. However, since compression cache is accounted for by the VM’s guest memory usage, a very large compression cache may waste VM memory and unnecessarily create VM memory pressure especially when most compressed pages would not be touched in the future. In ESX 4.1, the default maximum compression cache size is conservatively set to 10% of configured VM memory size. This value can be changed through the vSphere Client in Advanced Settings by changing the value for Mem.MemZipMaxPct.

When to reclaim Memory
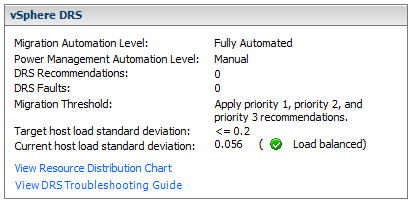
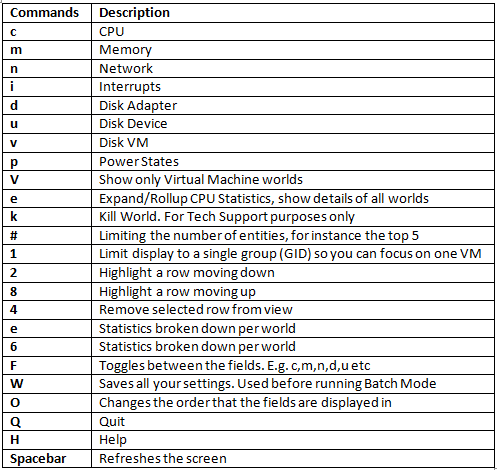
ESX maintains four host free memory states: high, soft, hard, and low, which are reflected by four thresholds: 6%, 4%, 2%, and 1% of host memory respectively. Figure 8 shows how the host free memory state is reported in esxtop.
By default, ESX enables page sharing since it opportunistically “frees” host memory with little overhead. When to use ballooning or swapping (which activates memory compression) to reclaim host memory is largely determined by the current host free memory state.

In the high state, the aggregate virtual machine guest memory usage is smaller than the host memory size. Whether or not host memory is overcommitted, the hypervisor will not reclaim memory through ballooning or swapping. (This is true only when the virtual machine memory limit is not set.)
If host free memory drops towards the soft threshold, the hypervisor starts to reclaim memory using ballooning. Ballooning happens before free memory actually reaches the soft threshold because it takes time for the balloon driver to allocate and pin guest physical memory. Usually, the balloon driver is able to reclaim memory in a timely fashion so that the host free memory stays above the soft threshold.
If ballooning is not sufficient to reclaim memory or the host free memory drops towards the hard threshold, the hypervisor starts to use swapping in addition to using ballooning. During swapping, memory compression is activated as well. With host swapping and memory compression, the hypervisor should be able to quickly reclaim memory and bring the host memory state back to the soft state.
In a rare case where host free memory drops below the low threshold, the hypervisor continues to reclaim memory through swapping and memory compression, and additionally blocks the execution of all virtual machines that consume more memory than their target memory allocations.
In certain scenarios, host memory reclamation happens regardless of the current host free memory state. For example, even if host free memory is in the high state, memory reclamation is still mandatory when a virtual machine’s memory usage exceeds its specified memory limit. If this happens, the hypervisor will employ ballooning and, if necessary, swapping and memory compression to reclaim memory from the virtual machine until the virtual machine’s host memory usage falls back to its specified limit
VMware vSphere 5 Memory Management and Monitoring diagram
The diagram from this KB is fantastic for showing the interoperability between Memory Management Techniques
KB2017642