What is a Datastore Cluster?
A Datastore Cluster is a collection of Datastores with shared resources and a shared management interface. When you create a Datastore cluster, you can use Storage DRS to manage storage resources and balance
General Rules
- Datastores from different arrays can be added to the same cluster but LUNs from arrays of different types can adversely affect performance if they are not equally performing LUNs.
- Datastore clusters must contain similar or interchangeable Datastores
- Datastore clusters can only have ESXi 5 hosts attached
- Do not mix NFS and VMFS datastores in the same Datastore Cluster
- You can mix VMFS-3 and VMFS-5 Datastores in the same Datastore Cluster
- Datastore Clusters can only be created from the vSphere client, not the Web Client
- A VM can have its virtual disks on different Datastores
Storage DRS
Storage DRS provides initial placement and ongoing balancing recommendations assisting vSphere administrators to make placement decisions based on space and I/O capacity. During the provisioning of a virtual machine, a Datastore Cluster can be selected as the target destination for this virtual machine or virtual disk after which a recommendation for initial placement is made based on space and I/O capacity. Initial placement in a manual provisioning process has proven to be very complex in most environments and as such crucial provisioning factors like current space utilization or I/O load are often ignored. Storage DRS ensures initial placement recommendations are made in accordance with space constraints and with respect to the goals of space and I/O load balancing. These goals aim to minimize the risk of storage I/O bottlenecks and minimize performance impact on virtual machines.
Ongoing balancing recommendations are made when
- One or more Datastores in a Datastore cluster exceeds the user-configurable space utilization which is checked every 5 minutes
- One or more Datastores in a Datastore cluster exceeds the user-configurable I/O latency thresholds which is checked every 8 Hours
- I/O load is evaluated by default every 8 hours. When the configured maximum space utilization or the I/O latency threshold (15ms by default) is exceeded Storage DRS will calculate all possible moves to balance the load accordingly while considering the cost and the benefit of the migration.
Storage DRS utilizes vCenter Server’s Datastore utilization reporting mechanism to make recommendations whenever the configured utilized space threshold is exceeded.
Affinity Rules and Maintenance Mode
Storage DRS affinity rules enable controlling which virtual disks should or should not be placed on the same datastore within a datastore cluster. By default, a virtual machine’s virtual disks are kept together on the same datastore. Storage DRS offers three types of affinity rules:
- VMDK Anti-Affinity
Virtual disks of a virtual machine with multiple virtual disks are placed on different datastores
- VMDK Affinity
Virtual disks are kept together on the same datastore
- VM Anti-Affinity
Two specified virtual machines, including associated disks, are place on different datastores
In addition, Storage DRS offers Datastore Maintenance Mode, which automatically evacuates all virtual machines and virtual disk drives from the selected datastore to the remaining datastores in the datastore cluster.
Configuring Datastore Clusters on the vSphere Web Client
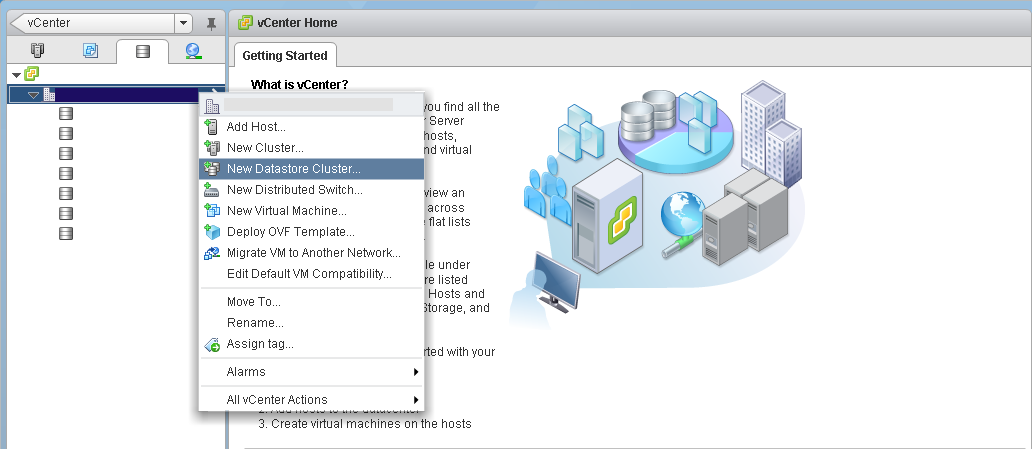
- Log into your vSphere client and click on the Datastores and Datastore Clusters view
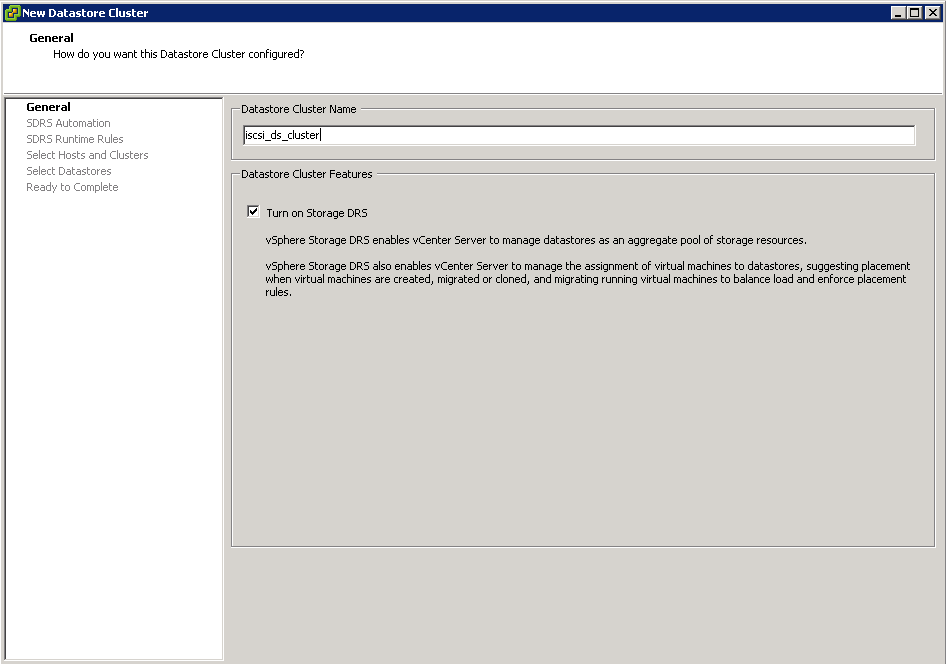
- Right-click on your Datacenter object and select New Datastore Cluster
- Enter in a name for the Datastore Cluster and choose whether or not to enable Storage DRS
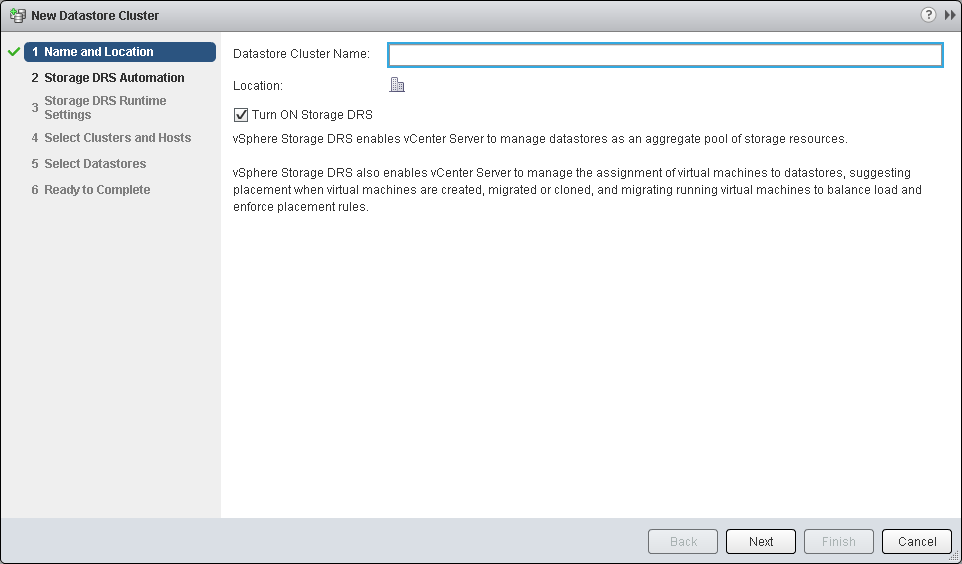
- Click Next
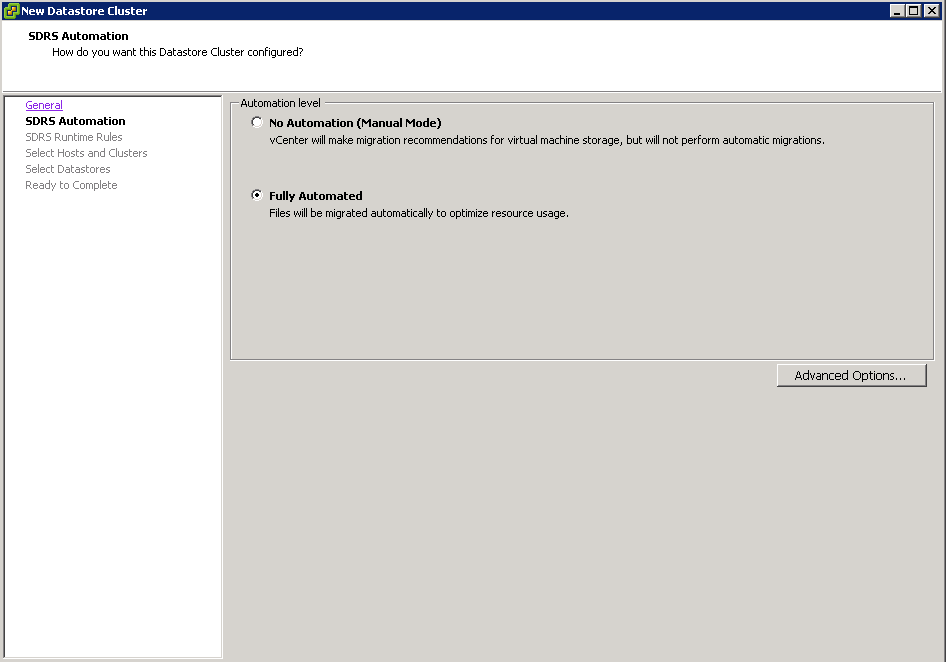
- You can now choose whether you want a “Fully Automated” cluster that migrates files on the fly in order to optimize the Datastore cluster’s performance and utilization, or, if you prefer, you can select No Automation to approve recommendations.
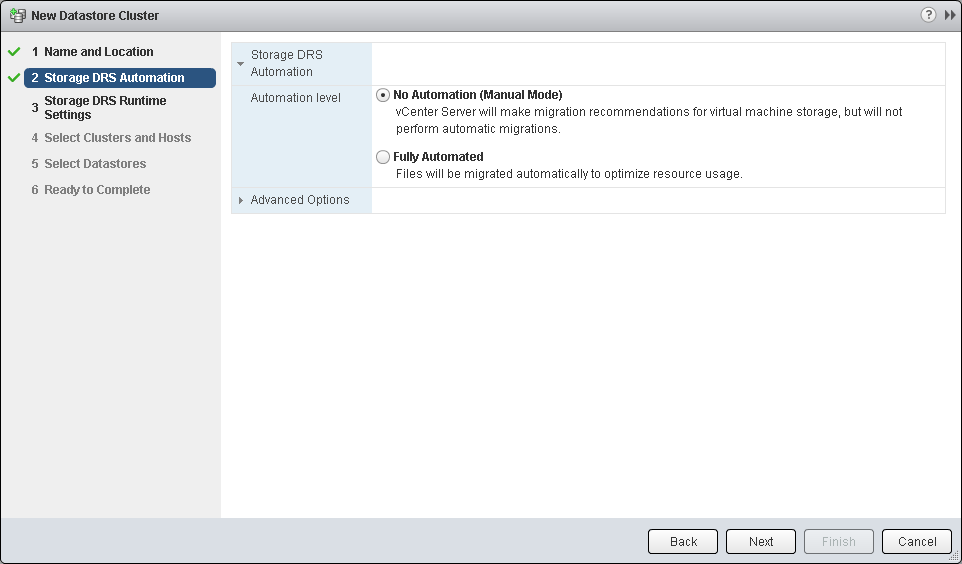
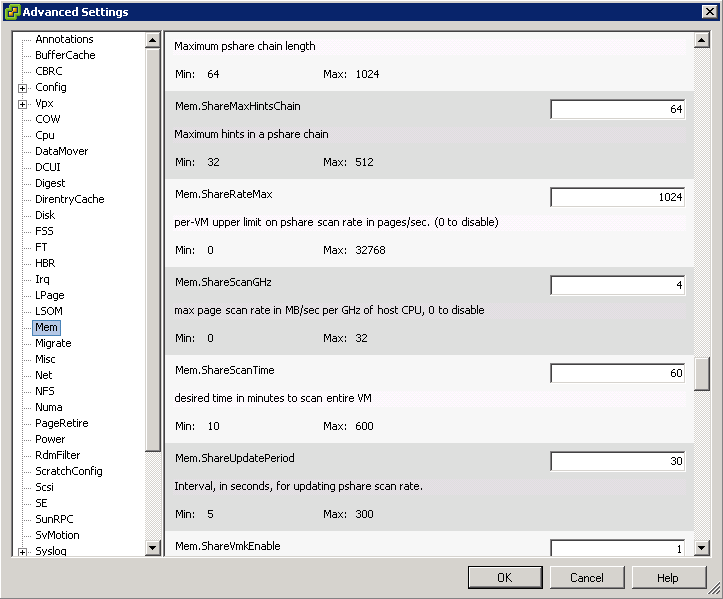
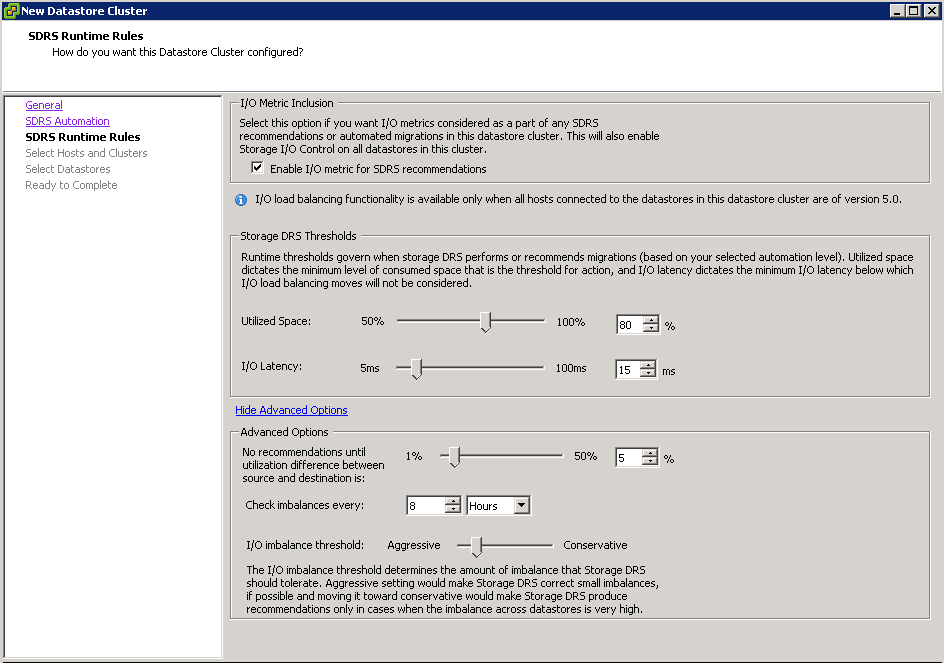
- Here you can decide what utilization levels or I/O Latency will trigger SDRS action. To benefit from I/O metric, all your hosts that will be using this datastore cluster must be version 5.0 or later. Here you can also access some advanced and very important settings like defining what is considered a marginal benefit for migration, how often does SDRS check for imbalance and how aggressive should the algorithm be
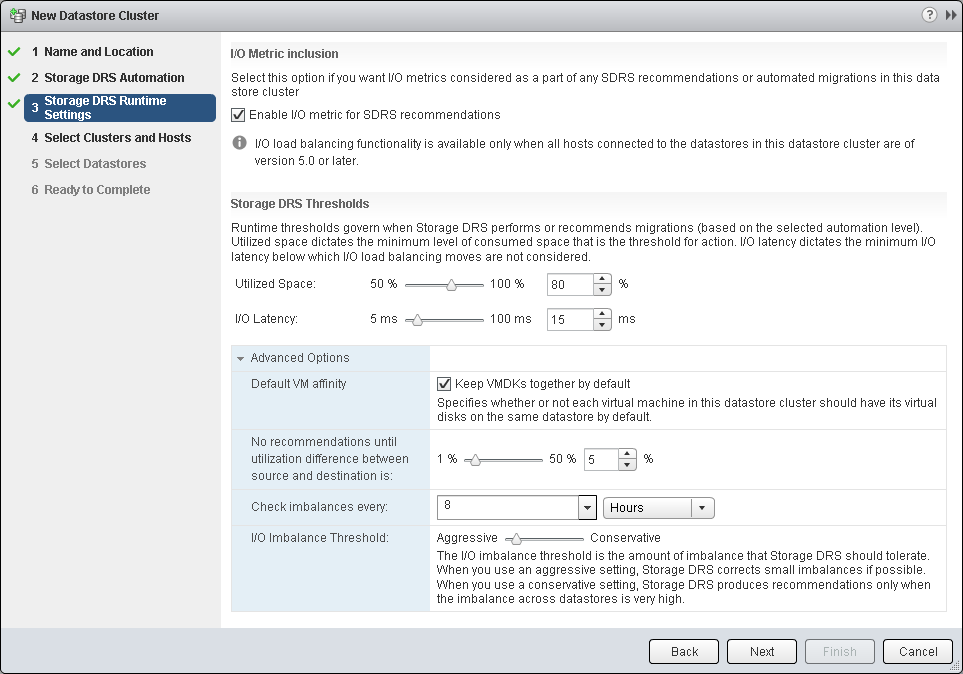
- I/O Latency only applicable if Enable I/O metric for SDRS recommendations is ticked
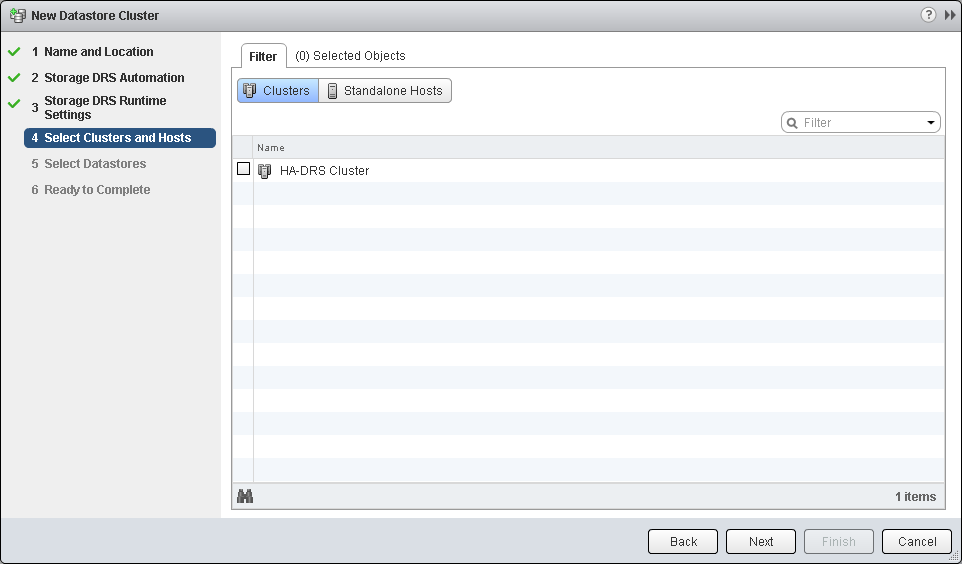
- Next you pick what standalone hosts and/or host clusters will have access to the new Datastore Cluster
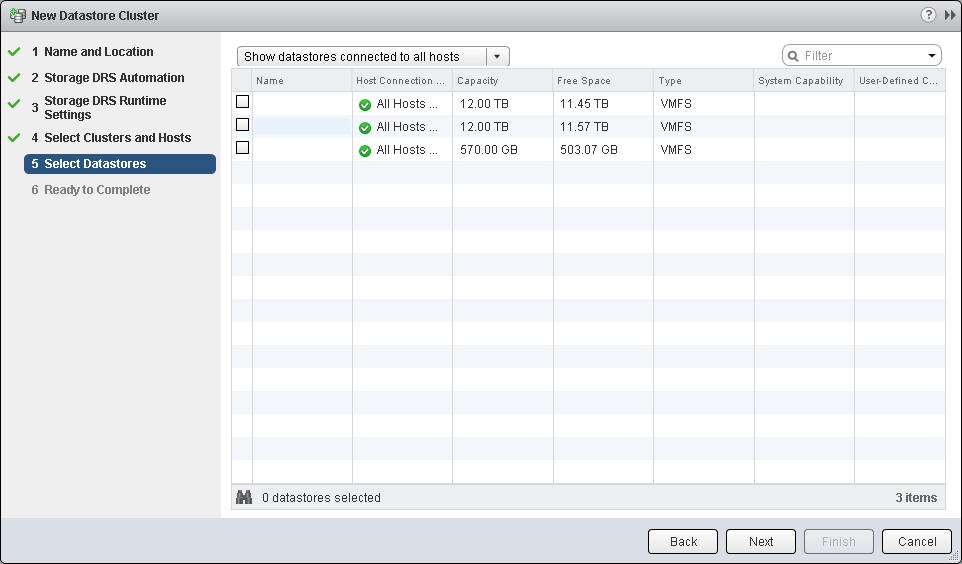
- Select from the list of datastores that can be included in the cluster. You can list datastores that are connected to all hosts, some hosts or all datastores that are connected to any of the hosts and/or clusters you have chosen in the previous step.
- At this point check all your selections
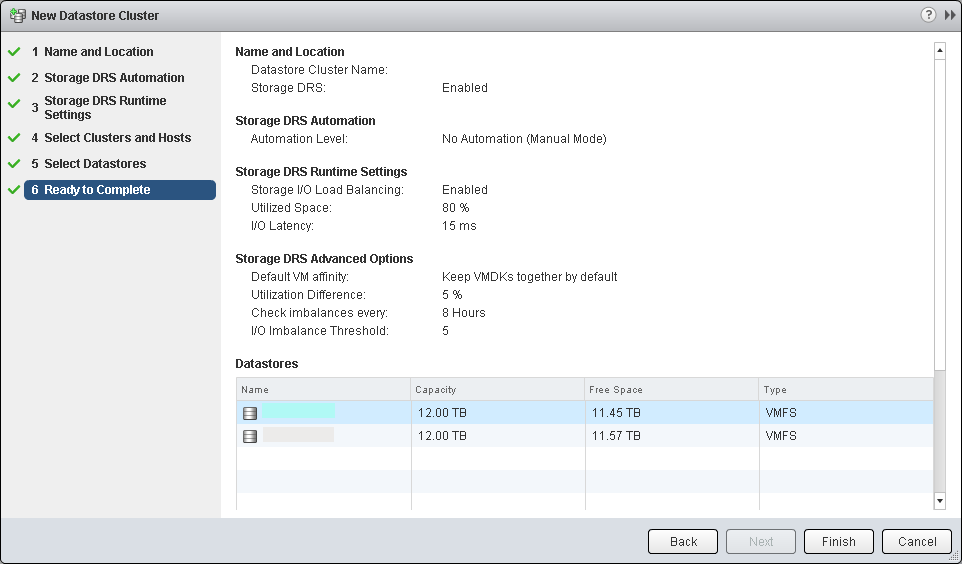
vSphere Client Procedure
- Right click the Datacenter and select New Datastore Cluster
- Put in a name
- Click Next and select the level of automation you want
- Click Next and choose your sDRS Runtime Rules
- Click Next and select Hosts and Clusters
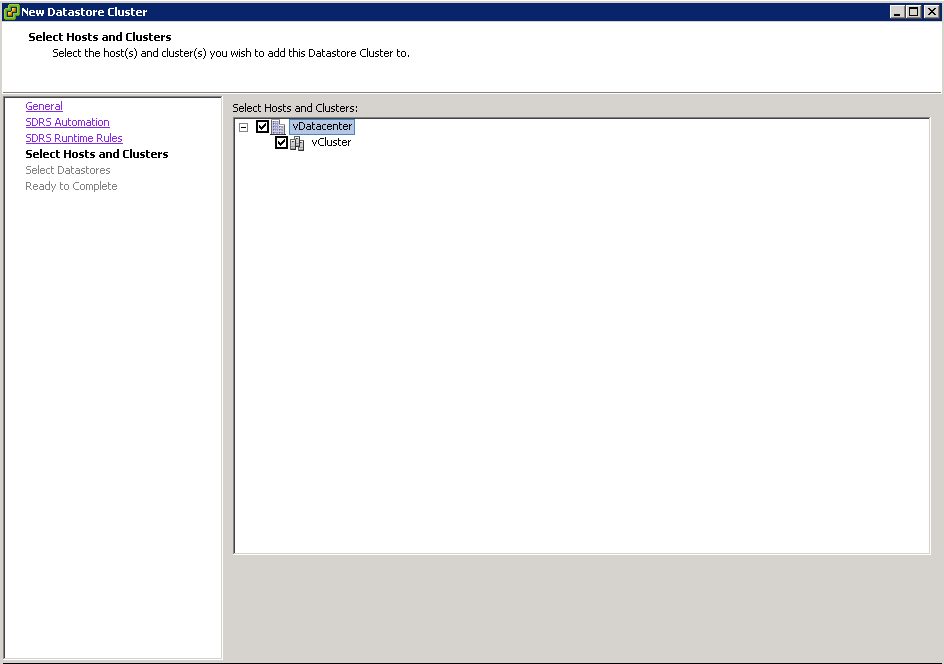
- Click Next and select your Datastores
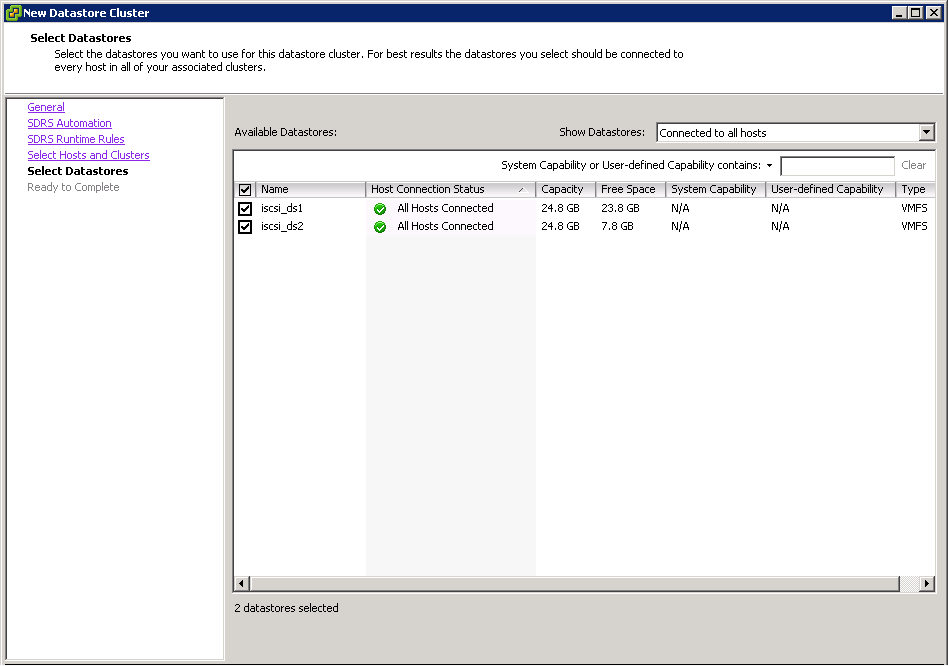
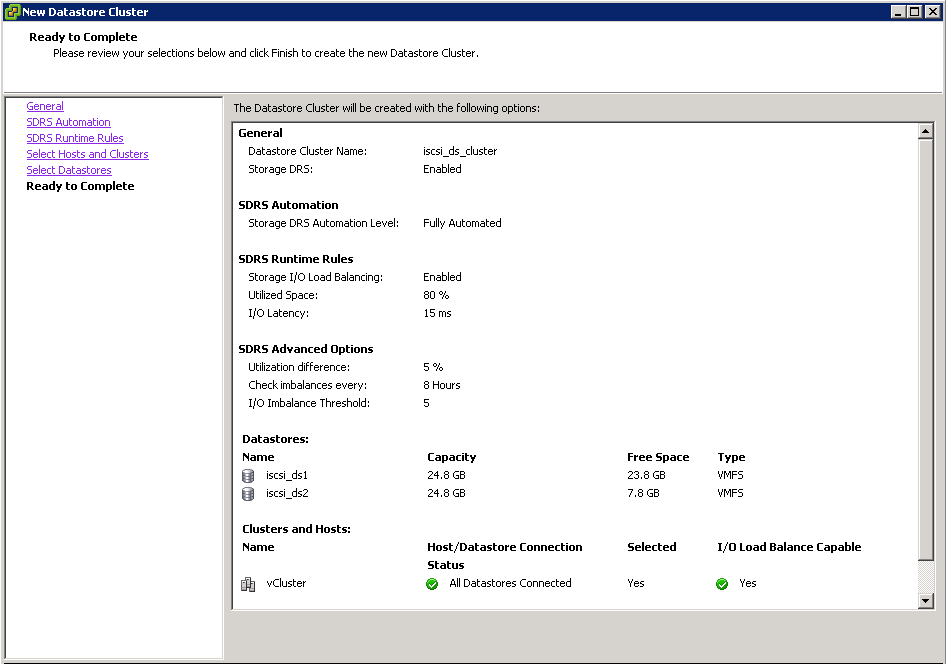
- Click Finish
- Check the Datastores view