
What is VdBench?
Vdbench is a command line utility specifically created to help engineers and customers generate disk I/O workloads to be used for validating storage performance and storage data integrity. Vdbench execution parameters may also specified via an input text file.
Vdbench is written in Java with the objective of supporting Oracle heterogeneous attachment. Vdbench has been tested on Solaris Sparc and x86, Windows NT, 2000, 2003, 2008, XP and Windows 7, HP/UX, AIX, Linux, Mac OS X, zLinux, and native VMware
Objective of Vdbench
The objective of Vdbench is to generate a wide variety of controlled storage I/O workloads, allowing control over workload parameters such as I/O rate, LUN or file sizes, transfer sizes, thread count, volume count, volume skew, read/write ratios, read and write cache hit percentages, and random or sequential workloads. This applies to both raw disks and file system files and is integrated with a detailed performance reporting mechanism eliminating the need for the Solaris command iostat or equivalent performance reporting tools. Vdbench performance reports are web accessible and are linked using HTML. Open your browser to access the summary.html file in the Vdbench output directory.
There is no requirement for Vdbench to run as root as long as the user has read/write access for the target disk(s) or file system(s) and for the output-reporting directory.
Non-performance related functionality includes data validation with Vdbench keeping track of what data is written where, allowing validation after either a controlled or uncontrolled shutdown.
How to download Vdbench
https://www.oracle.com/downloads/server-storage/vdbench-downloads.html
Vdbench comes packaged as a zip file which contains everything you need for Windows and Linux
Vdbench Terminology
Execution parameters control the overall execution of Vdbench and control things like parameter file name and target output directory name.
- Raw I/O workload parameters describe the storage configuration to be used and the workload to be generated. The parameters include General, Host Definition (HD), Replay Group (RG), Storage Definition (SD), Workload Definition (WD) and Run Definition (RD) and must always be entered in the order in which they are listed here. A Run is the execution of one workload requested by a Run Definition. Multiple Runs can be requested within one Run Definition.
- File system Workload parameters describe the file system configuration to be used and the workload to be generated. The parameters include General, Host Definition (HD), File System Definition (FSD), File system Workload Definition (FWD) and Run Definition (RD) and must always be entered in the order in which they are listed here. A Run is the execution of one workload requested by a Run Definition. Multiple Runs can be requested within one Run Definition.
- Replay: This Vdbench function will replay the I/O workload traced with and processed by the Sun StorageTekTM Workload Analysis Tool (Swat).
- Master and Slave: Vdbench runs as two or more Java Virtual Machines (JVMs). The JVM that you start is the master. The master takes care of the parsing of all the parameters, it determines which workloads should run, and then will also do all the reporting. The actual workload is executed by one or more Slaves. A Slave can run on the host where the Master was started, or it can run on any remote host as defined in the parameter file.
- Data Validation: Though the main objective of Vdbench has always been to execute storage I/O workloads, Vdbench also is very good at identifying data corruptions on your storage.
- Journaling: A combination of Data Validation and Journaling allows you to identify data corruption issues across executions of Vdbench.
- LBA, or lba: For Vdbench this never means Logical Block Address, it is Logical Byte Address. 16 years ago Vdbench creators decided that they did not want to have to worry about disk sector size changes
Vdbench Quick start
You can carry out a quick test to make sure everything is working ok
- /vdbench -t (for a raw I/O workload)
When running ‘./vdbench –t’ Vdbench will run a hard-coded sample run. A small temporary file is created and a 50/50 read/write test is executed for just five seconds.
This is a great way to test that Vdbench has been correctly installed and works for the current OS platform without the need to first create a parameter file.
- /vdbench -tf (for a filesystem workload)
Use a browser to view the sample output report in /vdbench/output/summary.html
To start Vdbench
- Linux: /home/vdbench/vdbench -f <parameter file>
- Windows: c:\vdbench\vdbench.bat -f <parameter file>
There are sample parameter files in the PDF documentation in section 1.34 and in the examples folder from the zip file.
Execution Parameter Overview
The main execution parameters are
| Command | Explanation |
| -f <workload parameter file> | One parameter file is required |
| -o <output directory> | Output directory for reporting. Default is output in current directory |
| -t | Run a 5 second sample workload on a small disk file |
| -tf | Run a 5 second sample filesystem workload |
| -e | Override elapsed parameters in Run Definitions |
| -I | Override interval parameters in Run Definitions |
| -w | Override warmup parameters in Run Definitions |
| -m | Override the amount of current JVM machines to run workload |
| -v | Activate data validation |
| -vr | Activate data validation immediately re-read after each write |
| -vw | but don’t read before write |
| -vt | Activate data validation. Keep track of each write timestamp Activate data validation (memory intensive) |
| -j | Activate data validation with journaling |
| -jr | Recover existing journal, validate data and run workload |
| -jro | Recover existing journal, validate data but do not run workload |
| -jri | Recover existing journal, ignore pending writes |
| -jm | Activate journaling but only write the journal maps |
| -jn | Activate journaling but use asynchronous writes to journal |
| -s | Simulate execution, Scans parameter names and displays run names |
| -k | Solaris only: Report kstat statistics on the console |
| -c | Clean (delete existing file system structure at start of run |
| -co | Force format=only |
| -cy | Force format=yes |
| -cn | Force format=no |
| -p | Override java socket port number |
| -l nnn | After the last run, start over with the first run. Without nnn this is an endless loop |
| -r | Allows for a restart of a parameter file containing multiple run definitions. E.g. -r rd5 if you have rd1 through rd10 in a parameter file |
| xxx=yyy | Used for variable substitution |
There are also Vdbench utility functions – See Section 1.9 in the PDF documentation
| Utility | Explanation |
| compare | Start Vdbench workload compare |
| csim | Compression simulator |
| dsim | Dedupe simulator |
| edit | Primitive full screen editor, syntax ‘./vdbench edit file.name’ |
| jstack | Create stack trace. Requires a JDK |
| parse(flat) | Selective parsing of flatfile.html |
| Print any block on any disk or disk file | |
| rsh | Start RSH daemon (For multi host testing) |
| sds | Start Vdbench SD Parameter Generation Tool (Solaris, Windows and Linux) |
| showlba | Used to display output of the XXXX parameter |
Parameter files
The parameter files get read in the following order
- General (Optional)
- HD (Host Definition) (Optional)
- RG (Replay Group)
- SD (Storage Definition)
- WD (Workload Definition)
- RD (Run Definition)
or for file system testing:
- General
- HD (Host Definition)
- FSD (File System Definition)
- FWD (File System Workload Definition)
- RD (Run Definition)
General Parameters
The below parameters must be the first in the file
| Command | Explanation |
| abort_failed_skew==nnn | Abort if requested workload skew is off by more than nnnn% |
| Compration=nn | Compression ratio |
| Concatenatesds=yes | By default, Vdbench will write an uncompressible random data pattern. ‘compratio=nn’ generates a data pattern that results in a nn:1 ratio. The data patterns implemented are based on the use of the ‘LZJB’ compression algorithm using a ZFS record size of 128k compression ratios 1:1 through 25:1 are the only ones implemented; any ratio larger than 25:1 will be set to 25. |
| create_anchors=yes | Create parent directories for FSD anchor |
| data_errors=nn | Terminate after ‘nn’ read/write/data validation errors (default 50) |
| data_errors=cmd | Run command or script ‘cmd’ after first read/write/data validation error, then terminate. |
| dedupratio= | Expected ratio. Default 1 (all blocks are unique). |
| dedupunit= | What size of data does Dedup compare? |
| dedupsets= | How many sets of duplicates. |
| deduphotsets= | Dedicated small sets of duplicates |
| dedupflipflop= | Activate the Dedup flip-flop logic. |
| endcmd=cmd | Execute command or script at the end of the last run |
| formatsds= | Force a one-time (pre)format of all SDs |
| formatxfersize= | Specify xfersize used when creating, expanding, or (pre)formatting an SD. |
| fwd_thread_adjust=no | Override the default of ‘yes’ to NOT allow FWD thread counts to be adjusted because of integer rounding/truncation. |
| histogram=(default,….) | Override defaults for response time histogram. |
| include=/file/name | There is one parameter that can be anywhere: include=/file/name When this parameter is found, the contents of the file name specified will be copied in place. Example: include=/complicated/workload/definitions.txt |
| ios_per_jvm=nnnnnn | Override the 100,000 default warning for ‘i/o or operations per second per slave. This means that YOU will be responsible if you are overloading your slaves. |
| journal=yes | Activate Data Validation and Journaling: |
| journal=recover | Recover existing journal, validate data and run workload |
| journal=only | Recover existing journal, validate data but do not run requested workload. |
| journal=noflush | Use asynchronous I/O on journal files |
| journal=maponly | Do NOT write before/after journal records |
| journal=skip_read_all | After journal recovery, do NO read and validate every data block. |
| journal=(max=nnn) | Prevent the journal file from getting larger than nnn bytes |
| journal=ignore_pending | Ignore pending writes during journal recovery. |
| loop= | Repeat all Run Definitions: loop=nn repeat nn times loop=nn[s|m|h] repeat until nn seconds/minutes/hours See also ‘-l nn’ execution parameter |
| messagescan=no | Do not scan /var/xxx/messages (Solaris or Linux) |
| messagescan=nodisplay | Scan but do not display on console, instead display on slave’s stdout. |
| messagescan=nnnn | Scan, but do not report more than nnn lines. Default 1000 |
| monitor=/file/name | See External control of Vdbench termination |
| pattern= | Override the default data pattern generation. |
| port=nn | Override the Java socket port number. |
| report=host_detail report=slave_detail | Specifies which SD detail reports to generate. Default is SD total only. |
| report=no_sd_detail report=no_fsd_detail | Will suppress the creation of SD/FSD specific reports. |
| report_run_totals=yes | Reports run totals. |
| startcmd=cmd | Execute command or script at the beginning of the first run |
| showlba=yes | Create a ‘trace’ file so serve as input to ./vdbench showlba |
| timeout=(nn,script) | |
| validate=yes | (-vt) Activate Data Validation. Options can be combined: validate=(x,y,z) |
| validate=read_after_write | (-vr) Re-reads a data block immediately after it was written. |
| validate=no_preread | (-vw) Do not read before rewrite, though this defeats the purpose of data validation! |
| validate=time | (-vt) keep track of each write timestamp (memory intensive) |
| validate=reportdedupsets | Reports ‘last time used’ for all duplicate blocks if a duplicate block is found to be corrupted. Also activates validate=time. Note: large SDs with few dedup sets can generate loads of output! |
Host Definition Parameter Overview
These parameters are ONLY needed when running Vdbench in a multi-host environment or if you want to override the number of JVMs used in a single-host environment
| Command | Explanation |
| hd=default | Sets defaults for all HDs that are entered later |
| hd=localhost | Sets values for the current host |
| hd=host_label | Specify a host label. |
| System=hostname | Host IP address or network name, e.g. xyz.customer.com |
| vdbench=vdbench_dir_name | Where to find Vdbench on a remote host if different from current. |
| jvms=nnn | How many slaves to use |
| shell=rsh | ssh | vdbench | How to start a Vdbench slave on a remote system. |
| user=xxxx | Userid on remote system Required. |
| clients=nn | Very useful if you want to simulate numerous clients for file servers without having all the hardware. Internally is basically creates a new ‘hd=’ parameter for each requested client. |
| mount=”mount xxx …” | This mount command is issued on the target host after the possibly needed mount directories have been created. |
Replay Group (RG parameter overview
| Command | Explanation |
| rg=name | Unique name for this Replay Group (RG). |
| devices=(xxx,yyy,….) | The device numbers from Swat’s flatfile.bin.gz to be replayed. |
Example: rg=group1,devices=(89465200,6568108,110)
Note: Swat Trace Facility (STF) will create Replay parameters for you. Select the ‘File’ ‘Create Replay parameter file’ menu option. All that’s then left to do is specify enough SDs to satisfy the amount of gigabytes needed.
Storage Definition (SD) Parameter Overview
This set of parameters identifies each physical or logical volume manager volume or file system file used in the requested workload. Of course, with a file system file, the file system takes the responsibility of all I/O: reads and writes can and will be cached (see also openflags=) and Vdbench will not have control over physical I/O. However, Vdbench can be used to test file system file performance
Example: sd=sd1,lun=/dev/rdsk/cxt0d0s0,threads=8
| Command | Explanation |
| sd=default | Sets defaults for all SDs that are entered later. |
| sd=name | Unique name for this Storage Definition (SD). |
| count=(nn,mm) | Creates a sequence of SD parameters. |
| align=nnn | Generate logical byte address in ‘nnn’ byte boundaries, not using default ‘xfersize’ boundaries. |
| dedupratio= | See data deduplication: |
| dedupsets= | |
| deduphotsets= | |
| dedupflipflop= | |
| hitarea=nn | See read hit percentage for an explanation. Default 1m. |
| host=name | Name of host where this SD can be found. Default ‘localhost’ |
| journal=xxx | Directory name for journal file for data validation |
| lun=lun_name | Name of raw disk or file system file. |
| offset=nnn | At which offset in a lun to start I/O. |
| openflags=(flag,..) | Pass specific flags when opening a lun or file |
| range=(nn,mm) | Use only a subset ‘range=nn’: Limit Seek Range of this SD. |
| replay=(group,..) | Replay Group(s) using this SD. |
| replay=(nnn,..) | Device number(s) to select for Swat Vdbench replay |
| resetbus=nnn | Issue ioctl (USCSI_RESET_ALL) every nnn seconds. Solaris only |
| resetlun=nnn | Issue ioctl (USCSI_RESET) every nnn seconds. Solaris only |
| size=nn | Size of the raw disk or file to use for workload. Optional unless you want Vdbench to create a disk file for you. |
| threads=nn | Maximum number of concurrent outstanding I/O for this SD. Default 8 |
Workload Definition (WD) Parameter Overview
The Workload Definition parameters describe what kind of workload must be executed using the storage definitions entered.
Example: wd=wd1,sd=(sd1,sd2),rdpct=100,xfersize=4k
| Command | Explanation |
| wd=default | Sets defaults for all WDs that are entered later. |
| wd=name | Unique name for this Workload Definition (WD) |
| sd=xx | Name(s) of Storage Definition(s) to use |
| host=host_label | Which host to run this workload on. Default localhost. |
| hotband= | See hotbanding |
| iorate=nn | Requested fixed I/O rate for this workload. |
| openflags=(flag,..) | Pass specific flags when opening a lun or file. |
| priority=nn | I/O priority to be used for this workload. |
| range=(nn,nn) | Limit seek range to a defined range within an SD. |
| rdpct=nn | Read percentage. Default 100. |
| rhpct=nn | Read hit percentage. Default 0. |
| seekpct=nn | Percentage of random seeks. Default seekpct=100 or seekpct=random. |
| skew=nn | Percentage of skew that this workload receives from the total I/O rate. |
| streams=(nn,mm) | Create independent sequential streams on the same device. |
| stride=(min,max) | To allow for skip-sequential I/O. |
| threads=nn | Only available during SD concatenation. |
| whpct=nn | Write hit percentage. Default 0. |
| xfersize=nn | Data transfer size. Default 4k. |
| xfersize=(n,m,n,m,..) | Specify a distribution list with percentages. |
| xfersize=(min,max,align) | Generate xfersize as a random value between min and max. |
File System Definition (FD) parameter overview
| Command | Explanation |
| fsd=name | Unique name for this File System Definition. |
| fsd=default | All parameters used will serve as default for all the following fsd’s. |
| anchor=/dir/ | The name of the directory where the directory structure will be created. |
| count=(nn,mm) | Creates a sequence of FSD parameters. |
| depth=nn | How many levels of directories to create under the anchor. |
| distribution=all | Default ‘bottom’, creates files only in the lowest directories. ‘all’ creates files in all directories. |
| files=nn | How many files to create in the lowest level of directories. |
| mask=(vdb_f%04d.file, vdb.%d_%d.dir) | The default printf() mask used to generate file and directory names. This allows you to create your own names, though they still need to start with ‘vdb’ and end with ‘.file’ or ‘.dir’. ALL files are numbered consecutively starting with zero. The first ‘%’ mask is for directory depth, the second for directory width. |
| openflags=(flag,..) | Pass extra flags to file system open request (See: man open) |
| shared=yes/no | Default ‘no’: See FSD sharing |
| sizes=(nn,nn,…..) | Specifies the size(s) of the files that will be created. |
| totalsize=nnn | Stop after a total of ‘nnn’ bytes of files have been created. |
| width=nn | How many directories to create in each new directory. |
| workingsetsize=nn wss=nn | Causes Vdbench to only use a subset of the total amount of files defined in the file structure. See workingsetsize. |
| journal=dir | Where to store your Data Validation journal files |
Filesystem Workload Definition (FWD) parameter overview:
| Command | Explanation |
| fwd=name | Unique name for this Filesystem Workload Definition. |
| fwd=default | All parameters used will serve as default for all the following fwd’s. |
| fsd=(xx,….) | Name(s) of Filesystem Definitions to use |
| openflags= | Pass extra flags to (Solaris) file system open request (See: man open) |
| fileio=(random.shared) | Allows multiple threads to use the same file. |
| fileio=(seq,delete) | Sequential I/O: When opening for writes, first delete the file |
| fileio=random | How file I/O will be done: random or sequential |
| fileio=sequential | How file I/O will be done: random or sequential |
| fileselect=random/seq | How to select file names or directory names for processing. |
| host=host_label | Which host this workload to run on. |
| operation=xxxx | Specifies a single file system operation that must be done for this workload. |
| rdpct=nn | For operation=read and operation=write only. This allows a mix and read and writes against a single file. |
| skew=nn | The percentage of the total amount of work for this FWD |
| stopafter=nnn | For random I/O: stop and close file after ‘nnn’ reads or writes. Default ‘size=’ bytes for random I/O. |
| threads=nn | How many concurrent threads to run for this workload. (Make sure you have at least one file for each thread). |
| xfersize=(nn,…) | Specifies the data transfer size(s) to use for read and write operations. |
Run Definition (RD) Parameter Overview (For raw I/O testing)
The Run Definition parameters define which of the earlier defined workloads need to be executed, what I/O rates need to be generated, and how long the workload will run. One Run Definition can result in multiple actual workloads, depending on the parameters used.
Example: rd=run1,wd=(wd1,wd2),iorate=1000,elapsed=60,interval=5
There is a separate list of RD parameters for file system testing.
| Command | Explanation | |
| rd=default | Sets defaults for all RDs that are entered later. | |
| rd=name | Unique name for this Run Definition (RD). | |
| wd=xx | Workload Definitions to use for this run. | |
| sd=xxx | Which SDs to use for this run (Optional). | |
| curve=(nn,nn,..) | Data points to generate when creating a performance curve. See also stopcurve= | |
| distribution=(x[,variable] | I/O inter arrival time calculations: exponential, uniform, or deterministic. Default exponential. | |
| elapsed=nn | Elapsed time for this run in seconds. Default 30 seconds. | |
| endcmd=cmd | Execute command or script at the end of the last run | |
| (for)compratio=nn | Multiple runs for each compression ratio. | |
| (for)hitarea=nn | Multiple runs for each hit area size. | |
| (for)hpct=nn | Multiple runs for each read hit percentage. | |
| (for)rdpct=nn | Multiple runs for each read percentage. | |
| (for)seekpct=nn | Multiple runs for each seek percentage. | |
| (for)threads=nn | Multiple runs for each thread count. | |
| (for)whpct=nn | Multiple runs for each write hit percentage. | |
| (for)xfersize=nn | Multiple runs for each data transfer size. | |
| Most forxxx parameters may be abbreviated to their regular name, e.g. xfersize=(..,..) | ||
| interval=nn | Stop the run after nnn bytes have been read or written, e.g. maxdata=200g. I/O will stop at the lower of elapsed= and maxdata=. | |
| iorate=(nn,nn,nn,…) | Reporting interval in seconds. Default ‘min(elapsed/2,60)’ | |
| iorate=curve | One or more I/O rates. | |
| iorate=max | Create a performance curve. | |
| iorate=(nn,ss,…) | Run an uncontrolled workload. | |
| nn,ss: pairs of I/O rates and seconds of duration for this I/O rate. See also ‘distribution=variable’. | ||
| openflags=xxxx | Pass specific flags when opening a lun or file | |
| pause=nn | Sleep ‘nn’ seconds before starting next run. | |
| replay=(filename, split=split_dir, repeat=nn) | -‘filename’: Replay file name used for Swat Vdbench replay – ‘split_dir’: directory used to do the replay file split. – ‘nn’: how often to repeat the replay. | |
| startcmd=cmd | Execute command or script at the beginning of the first run | |
| stopcurve=n.n | Stop iorate=curve runs when response time > n.n ms. | |
| warmup=nn | Override warmup period. |
Run Definition (RD) parameters for file systems, overview
These parameters are file system specific parameters. More RD parameters can be found
| Command | Explanation |
| fwd=(xx,yy,..) | Name(s) of Filesystem Workload Definitions to use. |
| fwdrate=nn | How many file system operations per second |
| format=yes/no/only/ restart/clean/once/ directories | During this run, if needed, create the complete file structure. |
| operations=xx | Overrides the operation specified on all selected FWDs. |
| foroperations=xx | Multiple runs for each specified operation. |
| fordepth=xx | Multiple runs for each specified directory depth |
| forwidth=xx | Multiple runs for each specified directory width |
| forfiles=xx | Multiple runs for each specified amount of files |
| forsizes=xx | Multiple runs for each specified file size |
| fortotal=xx | Multiple runs for each specified total file size |
Report Files
HTML files are written to the directory specified using the ‘-o’ execution parameter.
These reports are all linked together from one starting point. Use your favourite browser and point at ‘summary.html’.
| Report Type | Explanation |
| summary.html | Contains workload results for each run and interval. Summary.html also contains a link to all other html files, and should be used as a starting point when using your browser for viewing. For file system testing see summary.html for file system testing From a command prompt in windows just enter ‘start summary.html’; on a unix system, just enter ‘firefox summary.html &’. |
| totals.html | Reports only run totals, allowing you to get a quick overview of run totals instead of having to scan through page after page of numbers. |
| totals_optional.html | Reports the cumulative amount of work done during a complete Vdbench execution. For SD/WD workloads only. |
| hostx.summary.html | Identical to summary.html, but containing results for only one specific host. This report will be identical to summary.html when not used in a multi-host environment. |
| hostx-n.summary.html | Summary for one specific slave. |
| logfile.html | Contains a copy of most messages displayed on the console window, including several messages needed for debugging. |
| hostx_n.stdout.html | Contains logfile-type information for one specific slave. |
| parmfile.html | Contains a copy of the parameter file(s) from the ‘-f parmfile ‘ execution parameter. |
| parmscan.html | Contains a running trail of what parameter data is currently being parsed. If a parsing or parameter error is given this file will show you the latest parameter that was being parsed. |
| sdname.html | Contains performance data for each defined Storage Definition. See summary.html for a description. You can suppress this report with ‘report=no_sd_detail’ |
| hostx.sdname.html | Identical to sdname.html, but containing results for only one specific host. This report will be identical to sdname.html when not used in a multi-host environment. This report is only created when the ‘report=host_detail’ parameter is used. |
| hostx_n.sdname.html | SD report for one specific slave. . This report is only created when the ‘report=slave_detail’ parameter is used. |
| kstat.html | Contains Kstat summery performance data for Solaris |
| hostx.kstat.html | Kstat summary report for one specific host. This report will be identical to kstat.html when not used in a multi-host environment. |
| host_x.instance.html | Contains Kstat device detailed performance data for each Kstat ‘instance’. |
| nfs3/4.html | Solaris only: Detailed NFS statistics per interval similar to the nfsstat command output. |
| flatfile.html | A file containing detail statistics to be used for extraction and input for other reporting tools. See also Parse Vdbench flatfile |
| errorlog.html | Any I/O errors or Data Validation errors will be written here. |
| swat_mon.txt | This file can be imported into the Swat Performance Monitor allowing you to display performance charts of a Vdbench run. |
| swat_mon_total.txt | Similar to swat_mon.txt, but allows Swat to display only run totals. |
| swat_mon.bin | Similar to swat_mon.txt above, but for File System workload data. |
| messages.html | For Solaris and Linux only. At the end of a run the last 500 lines from /var/adm/messages or /var/log/messages are copied here. These messages can be useful when certain I/O errors or timeout messages have been displayed. |
| fwdx.html | A detailed report for each File system Workload Definition (FWD). |
| wdx.html | A separate workload report is generated for each Workload Definition (WD) when more than one workload has been specified. |
| histogram.html | For file system workloads only. A response time histogram reporting response time details of all requested FWD operations. |
| sdx.histogram.html | A response time histogram for each SD. |
| wdx.histogram | A response time histogram for each WD. Only generated when there is more than one WD. |
| fsdx.histogram.html | A response time histogram for each FSD. |
| fwdx.histogram | A response time histogram for each FWD. Only generated when there is more than one FWD. |
| skew.html | A workload skew report. |
Sample Parameter Files
These example parameter files can also be found in the installation directory.
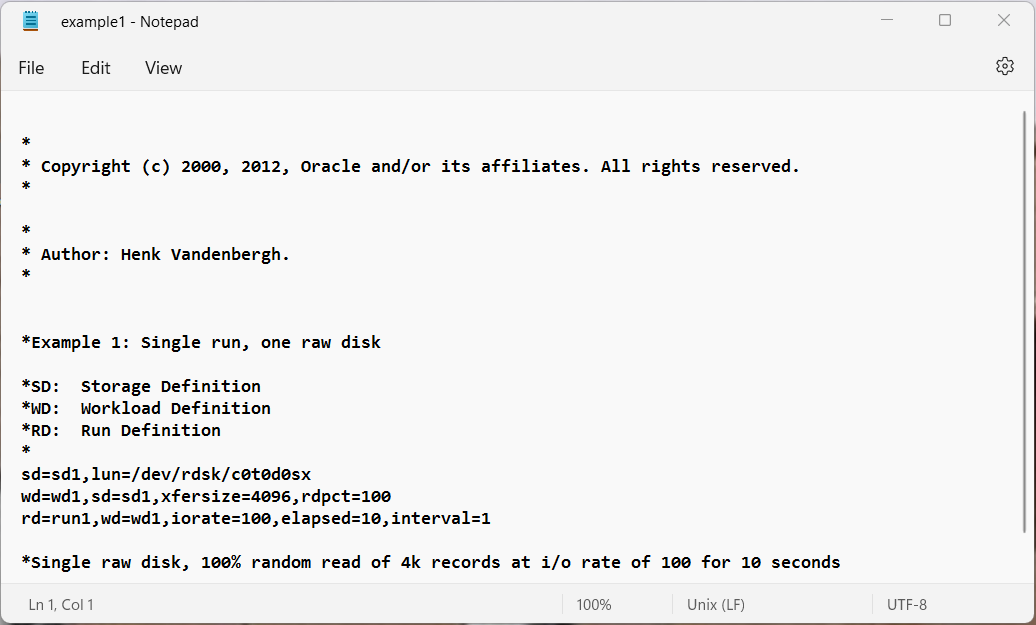
- Example 1: Single run, one raw disk
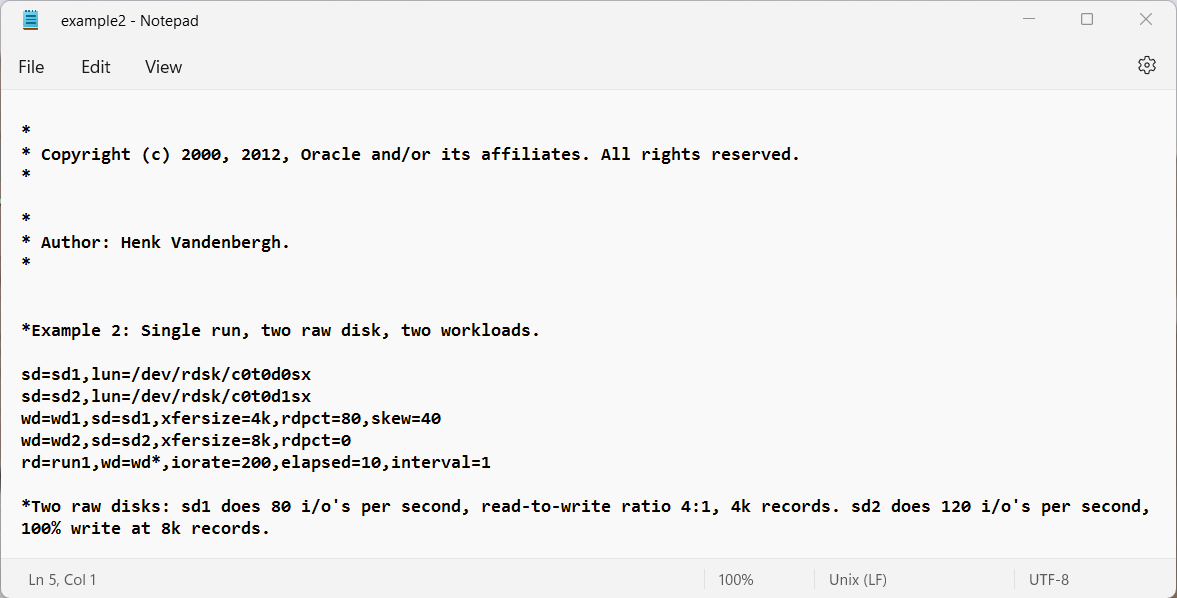
- Example 2: Single run, two raw disk, two workloads.
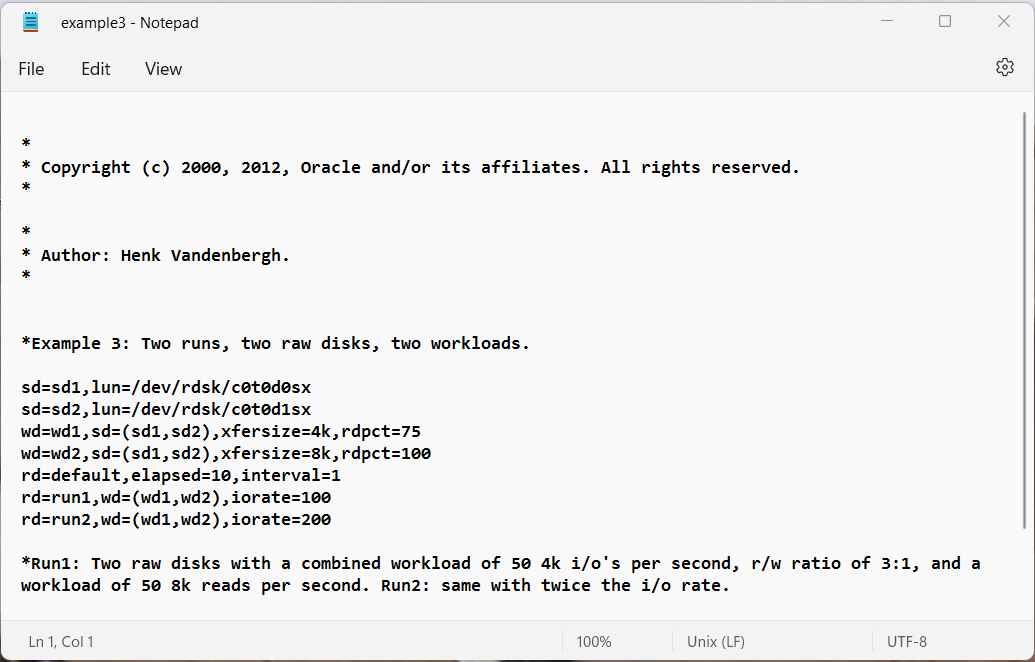
- Example 3: Two runs, two concatenated raw disks, two workloads.
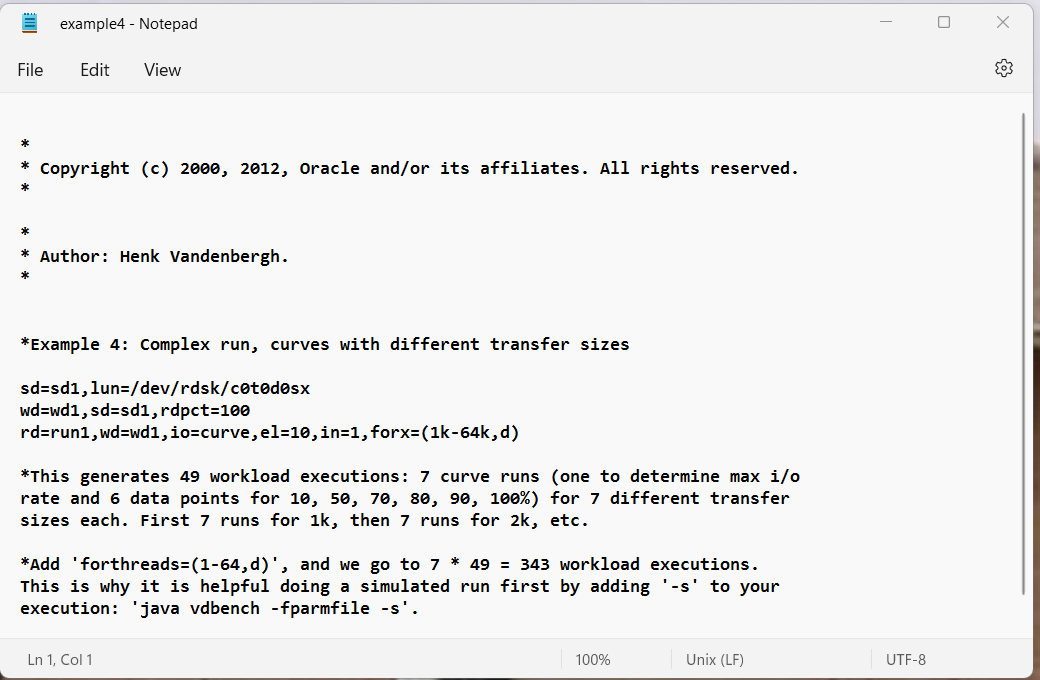
- Example 4: Complex run, including curves with different transfer sizes
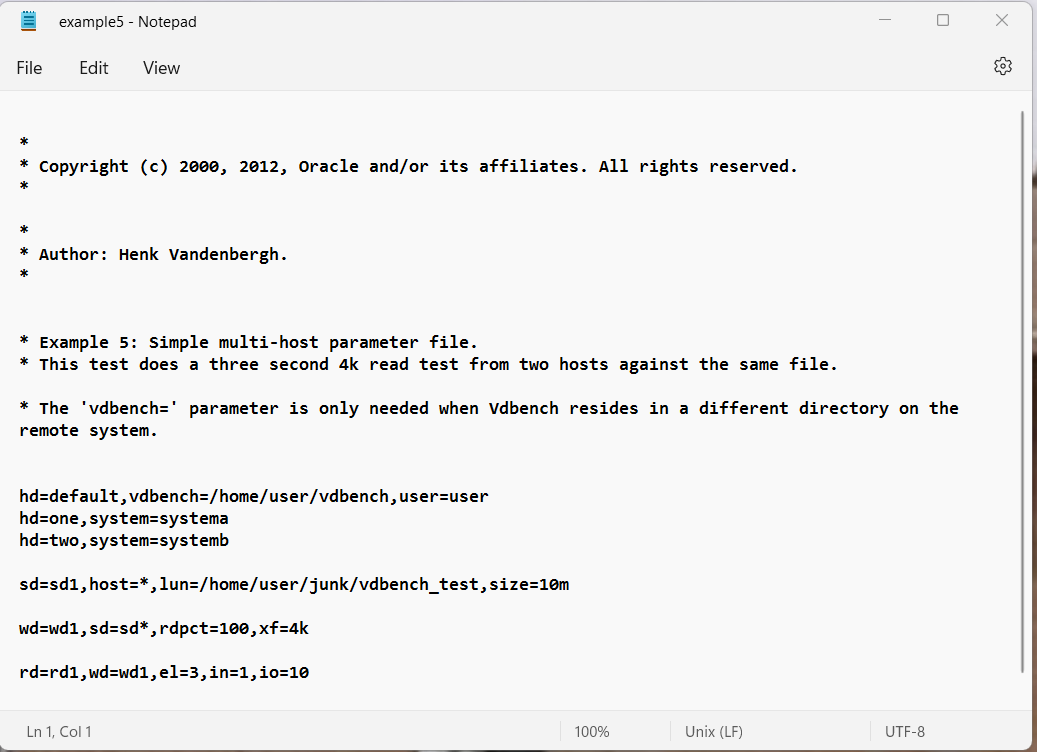
- Example 5: Multi-host.
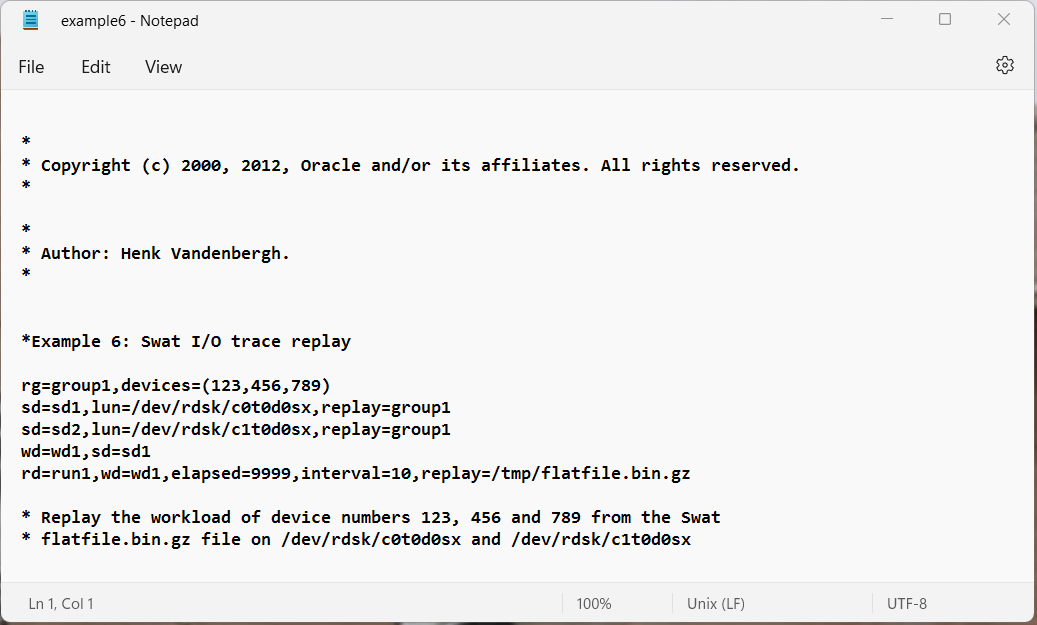
- Example 6: Swat trace replay.
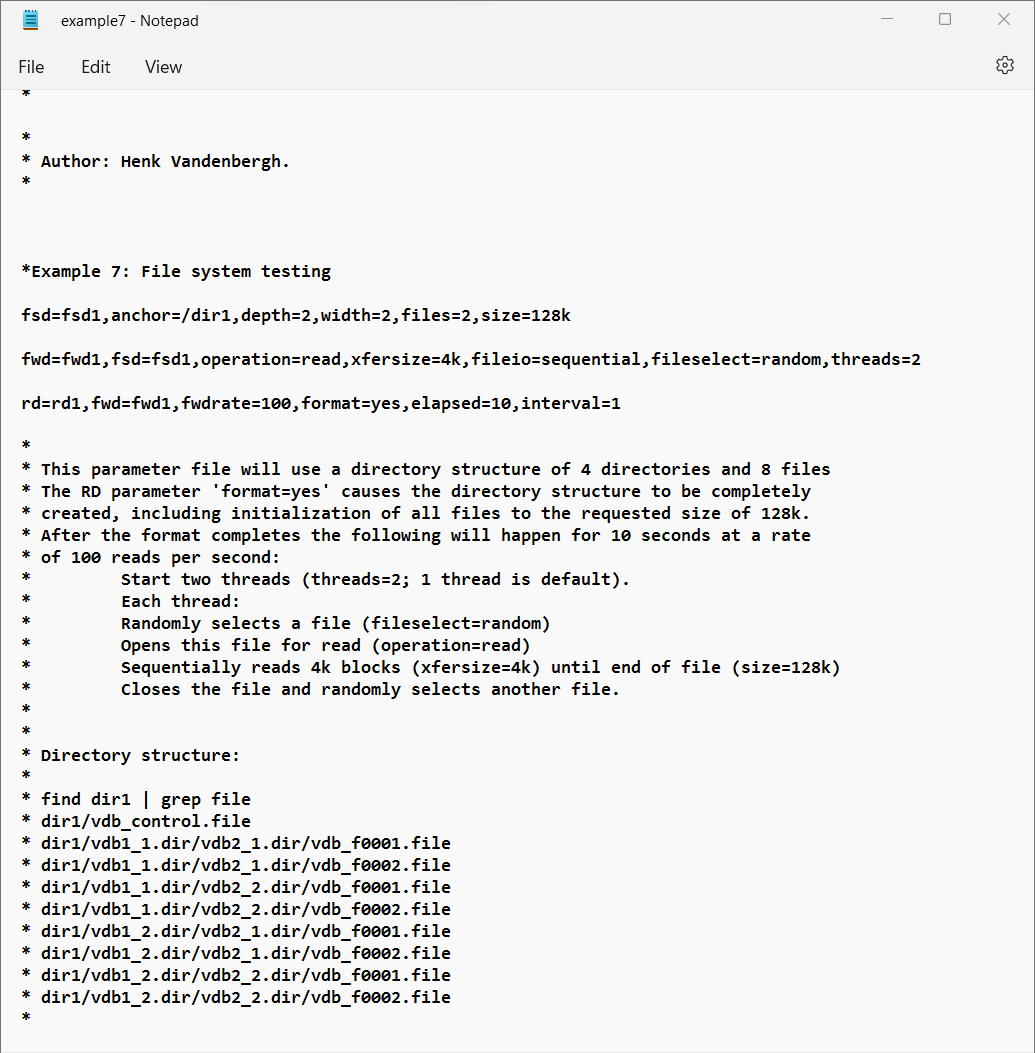
- Example 7: File system test. See also Sample parameter file:
There is a larger set of sample parameter files in the /examples/ directory inside your Vdbench install directory inside the filesys and raw folders
Example 1


Leave a Reply