HA in vSphere 5
The way HA works in vSphere 5 is quite different to the way it worked in vSphere 4. vSphere HA now uses a new tool called FDM (Fault Domain Manager) which has been developed to replace AAM (Automated Availability Manager) AAM had limitations in reliance on name resolution and scalability limits. Improvements such as
- FDM uses a Master/Slave architecture which does not rely on Primary/Secondary host designations
- FDM uses both the management network and storage devices for communications
- FDM introduces support for IPv6
- FDM addresses the issues of network partition and network isolation
How it works
- When vSphere HA is enabled, the vSphere HA agents enter an election to pick a vSphere HA Master.
- The vSphere HA master monitors slave hosts and will restart VMs in the event of a failover
- The vSphere HA master monitors the power state of all protected machines and if the VM fails, it will be restarted
- The vSphere HA master manages the list of hosts that are members of the cluster and manages the adding/removing of hosts into a cluster
- The vSphere HA master manages the list of protected VMs
- The vSphere HA master caches the cluster configuration. The master notifies and informs slave hosts of changes in the cluster
- The vSphere HA master sends heartbeat messages to the slave hosts so the slaves know the master is still alive
- The vSphere HA master reports state information to vCenter (Only the master does this)
HA Process
- The hosts within an HA cluster constantly heartbeat with the host designated as the master over the management network. The first step in determining whether a host is isolated is detecting a lack of these heartbeats.
- After a host stops communicating with the master, the master attempts to determine the cause of the issue.
- Using heartbeat datastores, the master can distinguish whether the host is still alive by determining if the affected host is maintaining heartbeats to the heartbeat datastores. This enables the master to differentiate between a management network failure, a dead host and a partitioned/isolated situation.
- The time elapsed before the host declares itself isolated varies depending on the role of the host (master or slave) at the time of the loss of heartbeats.
- If the host was a master, it will declare itself isolated within 5 seconds.
- If the host was a slave, it will declare itself isolated in 30 seconds.
- The difference in time is due to the fact that if the host was a slave, it then must go through an election process to identify whether any other hosts exist or if the master host simply died. This election process starts for the slave at 10 seconds after the loss of heartbeats is detected.
- If the host sees no response from another host during the election for 15 seconds, the HA agent on a host then elects itself as a master, checks whether it is isolated and, if so, drops into a startup state.
- In short, a host will begin to check to see whether it is isolated whenever it is a master in a cluster with more than one other host and has no slaves. It will continue to do so until it becomes a master with a slave or connects to a master as a slave.
- At this point, the host will attempt to ping its configured isolation addresses to determine the viability of the network. The default isolation address is the gateway specified for the management network.
- Advanced settings can be used to modify the isolation addresses used for your particular environment. The option das. isolationaddress[X] (where X is 1–10) is used to configure multiple isolation addresses.
- Additionally das. usedefaultisolationaddress is used to indicate whether the default isolation address (the default gateway) should be used to determine if the host is network isolated. If the default gateway is not able to receive ICMP ping packets, you must set this option to “false.”
- It is recommended to set one isolation address for each management network used, keeping in mind that the management network links should be redundant, as previously mentioned.
- The isolation address used should always be reachable by the host under normal situations, because after 5 seconds have elapsed with no response from the isolation addresses, the host then declares itself isolated.
- After this occurs, it will attempt to inform the master of its isolated state by use of the heartbeat datastores.
What does HA use?
- Management Network
- Datastore Heartbeats
Management Network
Ideally the Management network should be set up as a fully redundant network team at the adapter level or at the Management network level. It can either be setup as Etherchannel with Route based on IP Hash or in an Active/Standby configuration allowing for failover should one network card fail
In the event that the vSphere HA Master cannot communicate with a slave through the management network isolation address, it can then check its Heartbeat Datastores to see if the host is still up and running. This helps vSphere HA deal with Network Partitioning and Network Isolation
Switch Setup
Requirements:
- Two physical network adaptors
- VLAN trunking
- Two physical switches
The vSwitch should be configured as follows:
- Load balancing = route based on the originating virtual port ID (default)
- Failback = no
- vSwitch0: Two physical network adaptors (for example: vmnic0 and vmnic2)
- Two port groups (for example, vMotion and management)
In this example, the management network runs on vSwitch0 as active on vmnic0 and as standby on vmnic2. The vMotion network runs on vSwitch0 as active on vmnic2 and as standby on vmnic0
Each port group has a VLAN ID assigned and runs dedicated on its own physical network adaptor. Only in the case of a failure is it switched over to the standby network adaptor. Failback is set to “no” because in the case of physical switch failure and restart, ESXi might falsely recognize that the switch is back online when its ports first come online. In reality, the switch might not be forwarding on any packets until it is fully online. However, when failback is set to “no” and an issue arises, both your management network and vMotion network will be running on the same network adaptor and will continue running until you manually intervene.
Network Partitioning
This is what happens when one or more of the slaves cannot communicate with the vSphere HA Master even though they still have network connectivity. Checking the Datastore heartbeats is then used to see whether the slave hosts are alive
When a management network failure occurs for a vSphere HA cluster, a subset of the cluster’s hosts might be unable to communicate over the management network with the other hosts. Multiple partitions can occur in a cluster.
A partitioned cluster leads to degraded virtual machine protection and cluster management functionality. Correct the partitioned cluster as soon as possible.
Virtual machine protection. vCenter Server allows a virtual machine to be powered on, but it is protected only if it is running in the same partition as the master host that is responsible for it. The master host must be communicating with vCenter Server. A master host is responsible for a virtual machine if it has exclusively locked a system-defined file on the datastore that contains the virtual machine’s configuration file.
Cluster management. vCenter Server can communicate with only some of the hosts in the cluster, and it can connect to only one master host. As a result, changes in configuration that affect vSphere HA might not take effect until after the partition is resolved. This failure could result in one of the partitions operating under the old configuration.
Advanced Cluster Settings which can be used
- das.isolationaddressx Used to configure multiple isolation addresses.
- das.usedefaultisolationaddress Set to true/false and used in the cse where a default gateway is not pingable, in which case this set to false in conjunction with configuring another address for das.isolationaddress
- das.failuredetectiontime. Increase to 30 seconds (30000) to decrease the likelyhood of a false positive
NOTE: If you change the value of any of the following advanced attributes, you must disable and then re-enable vSphere HA before your changes take effect.
Network Isolation
This is where one or more slave hosts have lost all management network connectivity. Isolated hosts can’t communicate with the master or other slaves. The slave host uses the heartbeat datastore to notify the master that it is isolated via special binary file called host-X-poweron file.
Datastore Heartbeating
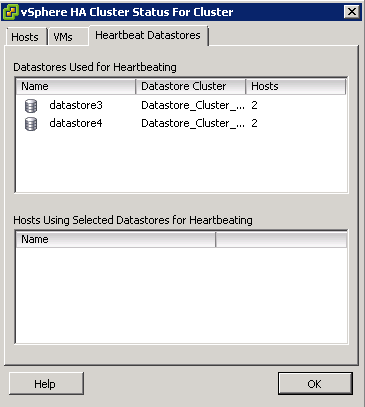
By default, vCenter will automatically select two datastores to use for storage heartbeats. An algorithm designed to maximize availability and redundancy of the storage heartbeats selects these datastores. This algorithm attempts to select datastores that are connected to the highest number of hosts. It also attempts to select datastores that are hosted on different storage arrays/NFS servers. A preference is given to VMware vSphere VMFS–formatted datastores, although NFS-hosted datastores can also be used.
- Highlight your cluster
- Click Edit Settings
- Select Datastore Heartbeating
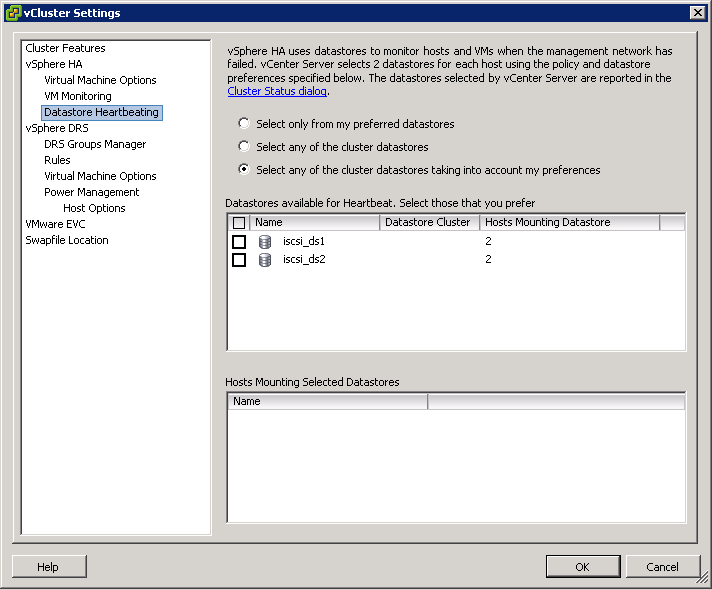
- Select only from my preferred datastores restricts HA to using only those selected from the list
- Select any of the cluster datastores disables the selection of datastores from the list. Any cluster datastore can be used by HA for heartbeating
- Select any of the cluster datastores taking into account my preferences is a mix of the previous 2 options. The Admin selects the preferred datastores that HA should use. vSphere selects which ones to use from these. If any become unavailable, HA will choose another from the list.
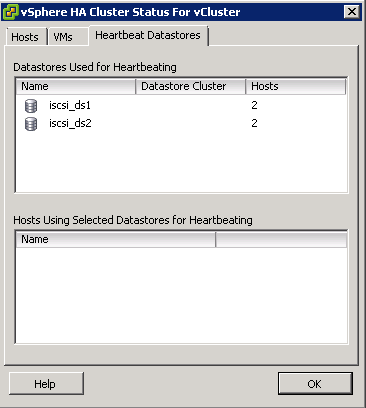
- The vSphere HA Cluster Status box will show you which datastores are being used
VMware Availability Guide
http://pubs.vmware.com
vSphere High Availability Deployment Best Practices
http://www.vmware.com/files/pdf/techpaper/vmw-vsphere-high-availability.pdf