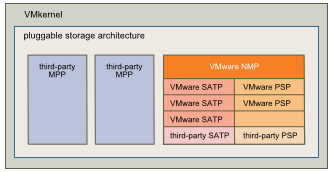
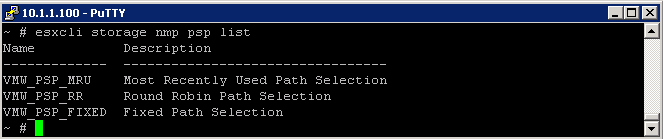
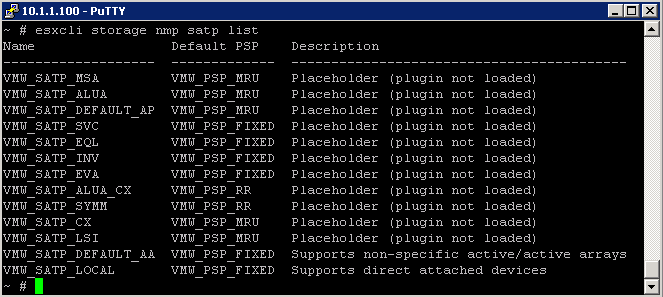
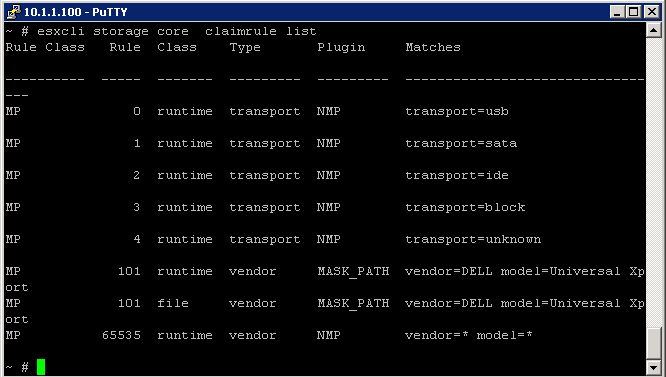
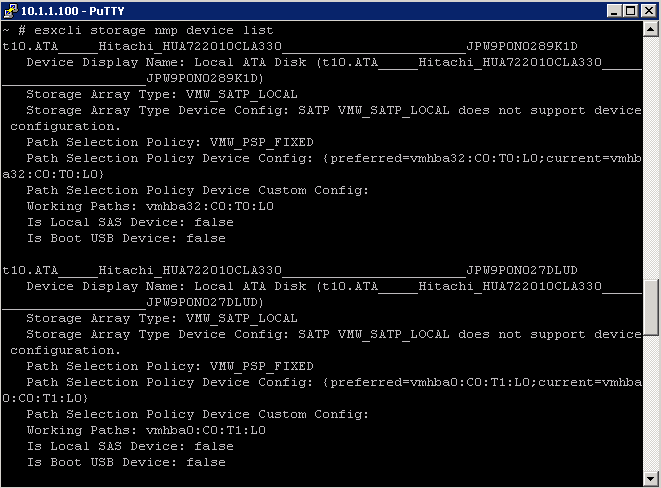
What is ISCSi?
iSCSI SANs use Ethernet connections between computer systems, or host servers, and high performance storage subsystems. The SAN components include iSCSI host bus adapters (HBAs) or Network Interface Cards (NICs) in the host servers, switches and routers that transport the storage traffic, cables, storage processors (SPs), and storage disk systems.
iSCSI SAN uses a client-server architecture. The client, called iSCSI initiator, operates on your host. It initiates iSCSI sessions by issuing SCSI commands and transmitting them, encapsulated into iSCSI protocol, to a server.
The server is known as an iSCSI target. The iSCSI target represents a physical storage system on the network. It can also be provided by a virtual iSCSI SAN, for example, an iSCSI target emulator running in a virtual machine. The iSCSI target responds to the initiator’s commands by transmitting required iSCSI data.
Ports
A single discoverable entity on the iSCSI SAN, such as an initiator or a target, represents an iSCSI node. Each node has one or more ports that connect it to the SAN.
iSCSI ports are end-points of an iSCSI session. Each node can be identified in a number of ways.
IP Address
Each iSCSI node can have an IP address associated with it so that routing and
switching equipment on your network can establish the connection between
the server and storage. This address is just like the IP address that you assign
to your computer to get access to your company’s network or the Internet.
iSCSI Name
A worldwide unique name for identifying the node. iSCSI uses the iSCSI
Qualified Name (IQN) and Extended Unique Identifier (EUI).
By default, ESXi generates unique iSCSI names for your iSCSI initiators, for
example, iqn.1998-01.com.vmware:iscsitestox-68158ef2. Usually, you do not
have to change the default value, but if you do, make sure that the new iSCSI
name you enter is worldwide unique.
ISCSI Alias
A more manageable name for an iSCSI device or port used instead of the iSCSI
name. iSCSI aliases are not unique and are intended to be just a friendly name
to associate with a port.
ISCSi Initiators
To access iSCSI targets, your host uses iSCSI initiators. The initiators transport SCSI requests and responses, encapsulated into the iSCSI protocol, between the host and the iSCSI target.
Your host supports different types of initiators.

Software Initiator
A software iSCSI adapter is a VMware code built into the VMkernel. It allows your host to connect to the iSCSI storage device through standard network adapters. The software iSCSI adapter handles iSCSI processing while communicating with the network adapter. With the software iSCSI adapter, you can use iSCSI technology without purchasing specialized hardware.
This requires VMkernel networking
Hardware Initiator
A hardware iSCSI adapter is a third-party adapter that offloads iSCSI and network processing from your host.
Hardware iSCSI adapters are divided into categories
- Dependent Hardware iSCSI Adapter. This requires VMkernel networking
This type of adapter can be a card that presents a standard network adapter and iSCSI offload functionality for the same port. The iSCSI offload functionality depends on the host’s network configuration to obtain the IP, MAC, and other parameters used for iSCSI sessions. An example of a dependent adapter is the iSCSI licensed Broadcom 5709 NIC.
- Independent Hardware iSCSI Adapter. No VMkernel networking needed
Implements its own networking and iSCSI configuration and management interfaces.
An example of an independent hardware iSCSI adapter is a card that either presents only iSCSI offload functionality or iSCSI offload functionality and standard NIC functionality. The iSCSI offload functionality has independent configuration management that assigns the IP, MAC, and other parameters used for the iSCSI sessions. An example of a independent adapter is the QLogic QLA4052 adapter. Hardware adapters may need to be licensed or they will not appear in the vClient or VCLI
CHAP
iSCSI storage systems authenticate an initiator by a name and key pair. ESXi supports the CHAP protocol, which VMware recommends for your SAN implementation. To use CHAP authentication, the ESXi host and the iSCSI storage system must have CHAP enabled and have common credentials.
Because the IP networks that the iSCSI technology uses to connect to remote targets do not protect the data they transport, you must ensure security of the connection. One of the protocols that iSCSI implements is the Challenge Handshake Authentication Protocol (CHAP), which verifies the legitimacy of initiators that access targets on the network.
CHAP uses a three-way handshake algorithm to verify the identity of your host and, if applicable, of the iSCSI target when the host and target establish a connection. The verification is based on a predefined private value, or CHAP secret, that the initiator and target share. ESXi supports CHAP authentication at the adapter level. In this case, all targets receive the same CHAP name and secret from the iSCSI initiator. For software and dependent hardware iSCSI adapters, ESXi also supports per-target CHAP authentication, which allows you to configure different credentials for each target to achieve greater level of security.
ESXi supports the following CHAP authentication methods:
- One-way CHAP
In one-way CHAP authentication, also called unidirectional, the target authenticates the initiator, but the initiator does not authenticate the target.
- Mutual CHAP
In mutual CHAP authentication, also called bidirectional, an additional level of security enables the initiator to authenticate the target. VMware supports this method for software and dependent hardware iSCSI adapters only.
For software and dependent hardware iSCSI adapters, you can set one-way CHAP and mutual CHAP for each initiator or at the target level. Independent hardware iSCSI supports CHAP only at the initiator level.
Security Levels
When you set the CHAP parameters, specify a security level for CHAP.
- Do not use CHAP (Software/Dependent/Independent)
- Do not use CHAP unless required by target (Software/Dependent)
- Do not use CHAP unless prohibited by target (Software/Dependent/Independent)
- Use CHAP (Software/Dependent)