
What is AI
Artificial Intelligence (AI) is the branch of computer science focused on creating systems capable of performing tasks that normally require human intelligence. These tasks include things like understanding natural language, recognizing patterns, solving problems, and making decisions.
AI systems use algorithms and large datasets to “learn” from data patterns, which is often referred to as machine learning. This allows them to improve their performance over time. Applications of AI range widely, from healthcare diagnostics and financial modeling to self-driving cars and language translation. There are different types of AI:
- Narrow AI (or Weak AI): Designed to perform a specific task, like voice assistants (e.g., Siri), image recognition, or playing chess.
- Broad AI Broad AI is a midpoint between Narrow and General AI. Rather than being limited to a single task, Broad AI systems are more versatile and can handle a wider range of related tasks. Broad AI is focused on integrating AI within a specific business process where companies need business- and enterprise-specific knowledge and data to train this type of system. Newer Broad AI systems predict global weather, trace pandemics, and help businesses predict future trends.
- General AI (or Strong AI): Hypothetical AI that could understand, learn, and apply knowledge in any domain, similar to human intelligence. This level of AI doesn’t yet exist.
- Artificial Superintelligence (ASI): A potential future stage where AI surpasses human intelligence in all fields 😮
Augmented Intelligence
There is also the term augmented intelligence. AI and augmented intelligence share the same objective, but have different approaches. Augmented intelligence tries to help humans with tasks that are not practical to do. For example, in healthcare, augmented intelligence systems assist doctors by analyzing medical data, such as imaging scans, lab results, and patient histories, to identify potential diagnoses. For instance, IBM Watson Health provides doctors with insights based on large volumes of medical data, suggesting possible diagnoses and treatment options. The doctor then uses this information, combined with their own expertise, to make the final decision. However, artificial intelligence has the aim of simulating human thinking and processes.
What does AI do?
AI services can ingest huge amounts of data. They can apply mathematical calculations in order to analyze data, sorting and organizing it in ways that would have been considered impossible only a few years ago. AI services can use their data analysis to make predictions. They can, in effect, say, “Based on this information, a certain thing will probably happen.”
Some of the most commonly cited benefits include:
- Automation of repetitive tasks.
- More and faster insight from data.
- Enhanced decision-making.
- Fewer human errors.
- 24×7 availability.
- Reduced physical risks.
The history of AI
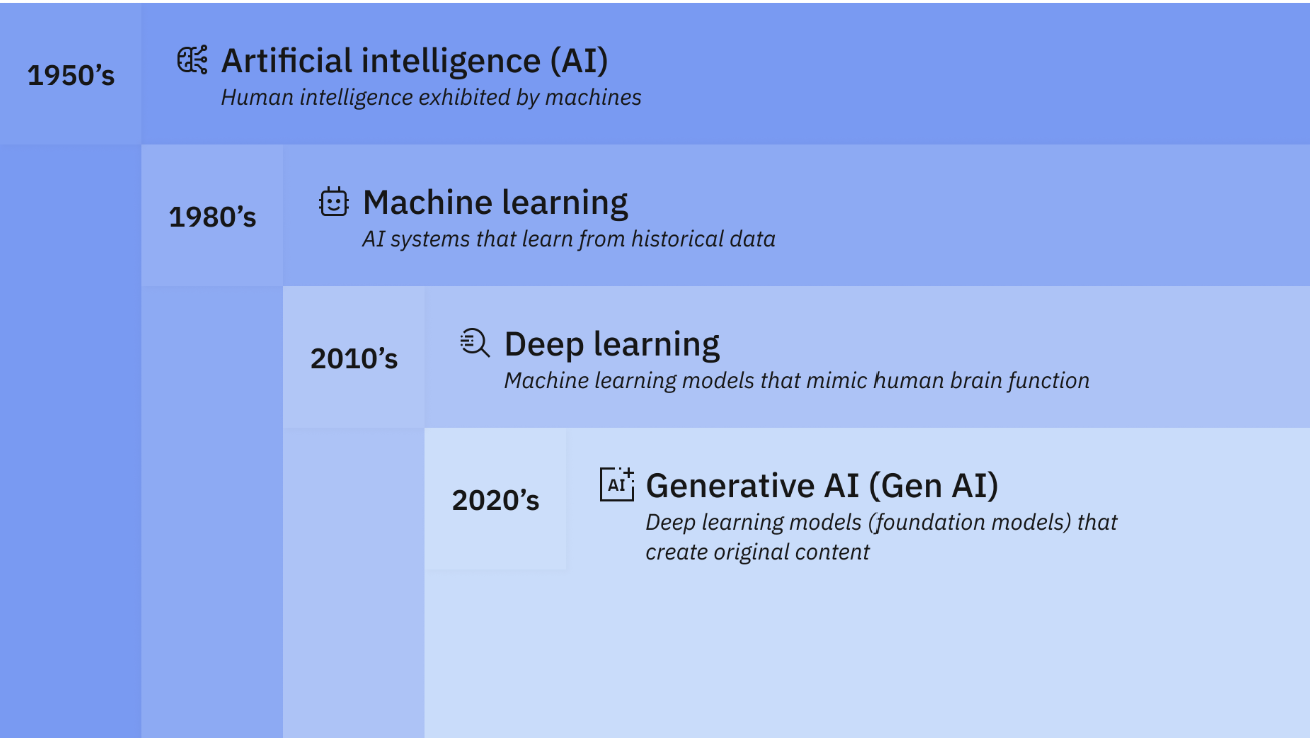
The Eras
How do we understand the meaning that’s hidden in large amounts of data. Information can be difficult to extract and analyse from a very large amount of data. Because it’s hard to see without help, scientists call this dark data. It’s information without a structure. During the mid-1800s in England, Charles Babbage and Ada Lovelace designed what they called a “difference engine” designed to handle complex calculations using logarithms and trigonometry. It wasn’t finished but if they had completed it, the difference engine might have helped the English Navy build tables of ocean tides and depth soundings to assist sailors. In the early 1900s, companies like IBM were using machines to tabulate and analyze the census numbers for entire national populations. They found patterns and structure within the data which had useful meaning beyond simple numbers. These machines uncovered ways that different groups within the population moved and settled, earned a living, or experienced health problems, information that helped governments better understand and serve them. By the early 1900s, companies like IBM were using machines to tabulate and analyze the census numbers for entire national populations. They didn’t just count people. They found patterns and structure within the data—useful meaning beyond mere numbers. These machines uncovered ways that different groups within the population moved and settled, earned a living, or experienced health problems—information that helped governments better understand and serve them. Researchers call these centuries the Era of Tabulation, a time when machines helped humans sort data into structures to reveal its secrets.
During World War II, a groundbreaking approach took shape to handling vast amounts of untapped information; what we now refer to as “dark data”, marking the beginning of the Programming Era. Scientists developed electronic computers capable of processing multiple types of instructions, or “programs.” Among the first was the Electronic Numerical Integrator and Computer (ENIAC), built at the University of Pennsylvania. ENIAC wasn’t limited to a single function; it could perform a range of calculations. It not only generated artillery firing tables for the U.S. Army but also undertook classified work to explore the feasibility of thermonuclear weapons. The Programming Era was a revolution in itself. Programmable computers guided astronauts from Earth to the moon and were reprogrammed during Apollo 13’s troubled mission to bring its astronauts safely back to Earth.Researchers call these centuries The Programming Era, a much more advanced era of AI
In the early summer of 1956, a pioneering group of researchers led by John McCarthy and Marvin Minsky gathered at Dartmouth College in New Hampshire, one of the oldest institutions in the United States. There, they sparked a scientific revolution by coining the term “artificial intelligence.” These researchers envisioned that “every aspect of learning or any other feature of intelligence” could be so precisely defined that a machine could be built to replicate it. With this vision of “artificial intelligence,” they secured substantial funding to pursue it, aiming to achieve their goals within 20 years. Over the next two decades, they made remarkable strides, creating machines that could prove geometry theorems, engage in basic English dialogue, and solve algebraic word problems. For a time, AI became one of the most thrilling and promising fields in computer science. However limited computing power and limited information storage restricted the progress of AI at the time. Researchers call this The Era of AI. It took about a decade for technology and AI theory to catch up. Today, AI has proven its ability in fields ranging from cancer research and big data analysis to defense systems and energy production.
Types of data
Data is raw information. Data might be facts, statistics, opinions, or any kind of content that is recorded in some format.
Data can be organized into the following three types.
- Structured data is typically categorized as quantitative data and is highly organized. Structured data is information that can be organized in rows and columns. Similar to what we see in spreadsheets, like Google Sheets or Microsoft Excel. Examples of structured data includes names, dates, addresses, credit card numbers, employee number
- Unstructured data, also known as dark data, is typically categorized as qualitative data. It cannot be processed and analyzed by conventional data tools and methods. Unstructured data lacks any built-in organization, or structure. Examples of unstructured data include images, texts, customer comments, medical records, and even song lyrics.
- Semi-structured data is the “bridge” between structured and unstructured data. It doesn’t have a predefined data model. It combines features of both structured data and unstructured data. It’s more complex than structured data, yet easier to store than unstructured data. Semi-structured data uses metadata to identify specific data characteristics and scale data into records and preset fields. Metadata ultimately enables semi-structured data to be better cataloged, searched, and analyzed than unstructured data.
Experts estimate that roughly 80% of all data generated today is unstructured. This data is highly variable and constantly evolving, making it too complex for conventional computer programs to analyze effectively
AI can start to give us answers on unstructured data! AI uses new kinds of computing—some modeled on the human brain—to rapidly give dark data structure, and from it, make new discoveries. AI can even learn things on its own from the data it manages and teach itself how to make better predictions over time.
As long as AI systems are provided and trained with unbiased data, they can make recommendations that are free of bias. A partnership between humans and machines can lead to sensible decisions.
Can machine learning help us with unstructured data?
If AI is not relying on programming instructions to work with unstructured data, how does AI start to analyse data? Machine learning can analyze dark data far more quickly than a programmable computer can. Think about the problem of finding a route through busy city traffic using a navigation system. It’s a dark data problem because solving it requires working with not only a complicated street map, but also with changing variables like weather, traffic jams, and accidents.
The machine learning process vs AI
The machine learning process has advantages:
- It doesn’t need a database of all the possible routes from one location to another. It just needs to know where places are on the map.
- It can respond to traffic problems quickly because it doesn’t need to store alternative routes for every possible traffic situation. It notes where slowdowns are and finds a way around them through trial and error.
- It can work very quickly. While trying single turns one at a time, it can work through millions of tiny calculations.
Machine learning can predict. As an example, a machine can determine, “Based on traffic currently, this route is likely to be faster than that one.” It knows this because it compared routes as it built them. It can also start to learn and notice that your car was delayed by a temporary detour and adjust its recommendations to help other drivers.
Types of machine learning
There are two other ways to contrast classical and machine learning systems. One is deterministic and the other is probabilistic.
In a deterministic system, there must be a vast, pre-defined network of possible paths—a massive database that the machine uses to make selections. If a particular path reaches the destination, the system marks it as “YES”; if not, it marks it as “NO.” This is binary logic: on or off, yes or no, and it’s the foundation of traditional computer programming. The answer is always definitive—either true or false—without any degree of certainty.
Machine learning, by contrast, operates on probabilities. It doesn’t give a strict “YES” or “NO.” Instead, machine learning is more like an analog process (similar to waves with gradual rises and falls) than a binary one (like sharply defined arrows up or down). Machine learning evaluates each possible route to a destination, factoring in real-time conditions and variables, such as changing traffic patterns. So, a machine learning system won’t say, “This is the fastest route,” but rather, “I am 84% confident that this is the fastest route.” You may have seen this when using maps on your phone where it will give you the option of 2 or more alternative routes.
Three common methods of machine learning
Machine learning solves problems in three ways:
- Supervised learning
- Unsupervised learning
- Reinforcement learning
Supervised learning
Supervised learning is about providing AI with enough examples to make accurate predictions. All supervised learning algorithms need labeled data. Labeled data is data that is grouped into samples that are tagged with one or more labels. In other words, applying supervised learning requires you to tell your model what something is and what features it has.
Unsupervised learning
In unsupervised learning, someone will feeds a machine a large amount of information, asks a question, and then the machine is left to figure out how to answer the question by itself.
For example, the machine might be fed many photos and articles about horses. It will classify and cluster information about all of them. When shown a new photo of a horse, the machine can identify the photo as a horse, with reasonable accuracy. Unsupervised learning occurs when the algorithm is not given a specific “wrong” or “right” outcome. Instead, the algorithm is given unlabeled data.
Unsupervised learning is helpful when you don’t know how to classify data. For example, lets say you work for a distribution company institution and you have a large set of customer financial data. You don’t know what type of groups or categories to organize the data. Here, an unsupervised learning algorithm could find natural groupings of similar customers in a database, and then you could describe and label them. This type of learning has the ability to discover similarities and differences in information, which makes it an ideal solution for exploratory data analysis, cross-selling strategies, customer segmentation, and image recognition.
Reinforcement learning
Reinforcement learning is a machine learning model similar to supervised learning, but the algorithm isn’t trained using sample data. This model learns as it goes by using trial and error. A sequence of successful outcomes is reinforced to develop the best recommendation for a given problem. The foundation of reinforcement learning is rewarding the “right” behavior and punishing the “wrong” behavior.
So what’s the link between AI and Machine Learning?
(Artificial Intelligence) and machine learning (ML) are closely related but are not the same thing. Here’s a breakdown of their relationship and differences:
- Artificial Intelligence
- Definition: AI is a broad field focused on creating systems or machines that can perform tasks that normally require human intelligence. These tasks can include reasoning, learning, problem-solving, perception, and language understanding.
- Scope: AI encompasses various approaches and technologies, including rule-based systems, expert systems, natural language processing, robotics, and, importantly, machine learning.
- Goal: The ultimate goal of AI is to create machines that can think and act intelligently, either by mimicking human cognitive functions or by developing entirely new capabilities.
2. Machine Learning
Definition: Machine learning is a subset of AI that specifically involves algorithms and statistical models that allow computers to learn from and make predictions or decisions based on data. Instead of following explicitly programmed instructions, ML models find patterns in data to improve their performance over time.
- Scope: ML includes various techniques and algorithms like supervised learning, unsupervised learning, reinforcement learning, neural networks, and deep learning.
- Goal: The goal of ML is to develop models that can generalize from data, allowing computers to improve their task performance automatically as they are exposed to more data.
How AI and ML are linked
- AI as the Parent Field: AI is the broader field, with ML as one of its key methods for achieving intelligent behavior.
- ML as a Tool for AI: ML provides a powerful way to achieve AI by enabling systems to learn from experience and adapt without needing extensive reprogramming.
- Types of AI: While ML is currently one of the most effective ways to achieve AI capabilities, other forms of AI (like rule-based systems) do not involve learning from data in the same way.
Summary
- AI: The broader goal of creating intelligent systems.
- ML: A method within AI that enables systems to learn and improve from data.
In essence, machine learning is one of the main drivers of AI today, especially in areas like computer vision, speech recognition, and natural language processing.

