What are Advanced Attributes?
You can set advanced attributes for hosts or individual virtual machines to help you customize resource management. In most cases, adjusting the basic resource allocation settings (reservation, limit, shares) or accepting default settings results in appropriate resource allocation. However, you can use advanced attributes to customize resource management for a host or a specific virtual machine.
Note: Changing advanced options is considered unsupported unless VMware technical support or a KB article instruct you to do so. In all other cases, changing these options is considered unsupported. In most cases, the default settings produce the optimum result.
Please Read Page 101 onwards of the Resource Management Guide
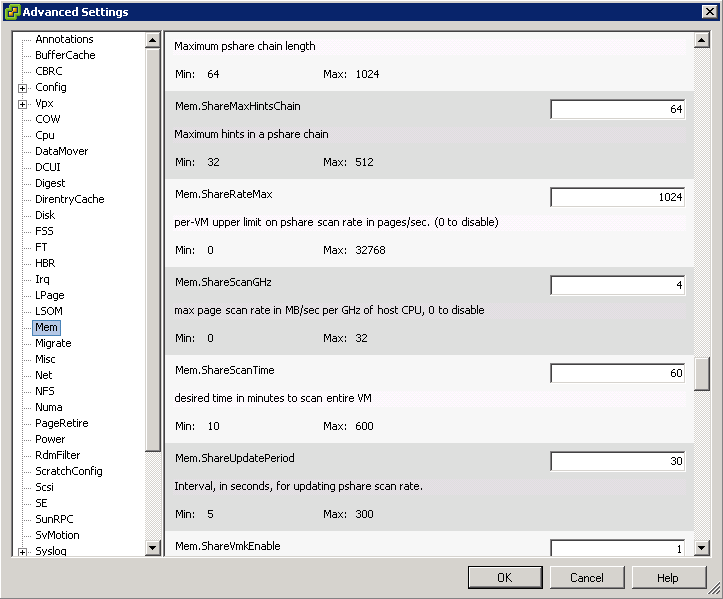
Host Advanced attributes
- Click on a host
- Click on Configuration
- Click on Advanced
- Select Attribute to Modify
- CPU Below
- Memory below
- Network below
- Disk below
- A list of Memory and CPU advanced attributes can be found in the vSphere Resource Management guide on pages 99-104
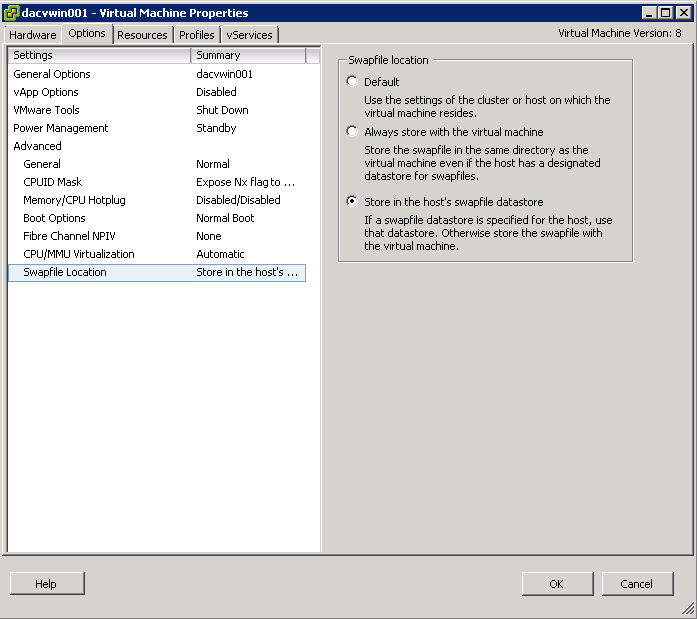
Virtual Machine Advanced attributes
- Right click on a VM and select Edit Settings
- Click the Options tab
- Select General under settings then select Configuration Parameters
- A typical example we added on a vSphere 4 system was an adjustment of Storage vMotion timeout which was fsr.MaxSwitchoverSeconds=300 as recommended in a KB article for VMs with a large Memory size. Ours were 160GB
Cluster Advanced Attributes
- Right click on your cluster
- Select Edit Settings
- Select VMware HA
- Select Advanced Options
- The example below shows an entry for a secondary HA Isolation address that we were testing. IP removed.