What is LUN Masking?
LUN (Logical Unit Number) Masking is an authorization process that makes a LUN available to some hosts and unavailable to other hosts.LUN Masking is implemented primarily at the HBA (Host Bus Adapter) level. LUN Masking implemented at this level is vulnerable to any attack that compromises the HBA. Some storage controllers also support LUN Masking.
LUN Masking is important because Windows based servers attempt to write volume labels to all available LUN’s. This can render the LUN’s unusable by other operating systems and can result in data loss.
How to MASK on a VMware ESXi Host
- Step 1: Identifying the volume in question and obtaining the naa ID
- Step 2: Run the esxcli command to associate/find this naa ID with the vmhba identifiers
- Step 3: Masking the volume when you want to preserve data from the VMFS volumes for later use or if the volume is already deleted
- Step 4: Loading the Claim Rules
- Step 5: Verify that the claimrule has loaded:
- Step 6: Unclaim the volume in question
- Step 7: Check Messages
- Step 8: Unpresent the LUN
- Step 9: Rescan all hosts
- Step 10 Restore normal claim rules
- Step 11: Rescan Datastores
Step 1
- Check in both places as listed in the table above that you have the correct ID
- Note: Check every LUN as sometimes VMware calls the same Datastore different LUN Numbers and this will affect your commands later
- Example Below
- Make a note of the naa ID
Step 2
- Once you have the naa ID from the above step, run the following command
- Note we take the : off
- -L parameter will show a compact list of paths

- Example below
- We can see there are 2 paths to the LUN called C0:T0:L40 and C0:T1:L40
- C=Channel, T=Target, L=LUN
- Next we need to check and see what claim rules exist in order to not use an existing claim rule number
- esxcli storage core claimrule list
- Note I had to revert to the vSphere 4 CLI command as I am screenprinting from vSphere 5 not 4!
Step 3
- At this point you should be absolutely clear what LUN number you are using!

- Next, you can use any rule numbers for the new claim rule that isn’t in the list above and pretty much anything from 101 upwards
- In theory I have several paths so i should do this exercise for all of the paths
Step 4

- The Class for those rules will show as file which means that it is loaded in /etc/vmware/esx.conf but it isn’t yet loaded into runtime.
Step 5
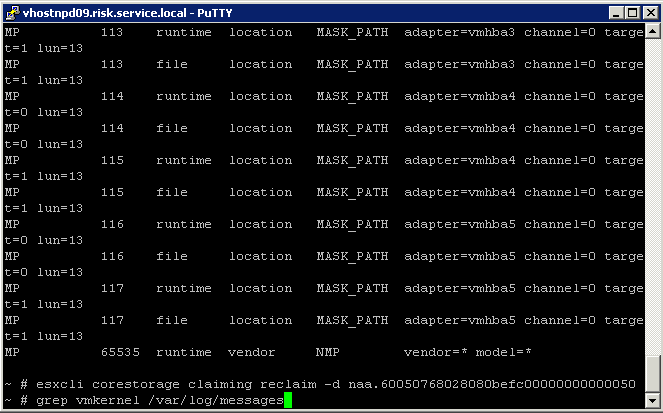
- Run the following command to see those rules displayed twice, once as the file Class and once as the runtime Class
Step 6

- Before these paths can be associated with the new plugin (MASK_PATH), they need to be disassociated from the plugin they are currently using. In this case those paths are claimed by the NMP plugin (rule 65535). This next command will unclaim all paths for that device and then reclaim them based on the claimrules in runtime.
Step 7
- Check Messages
- See example below
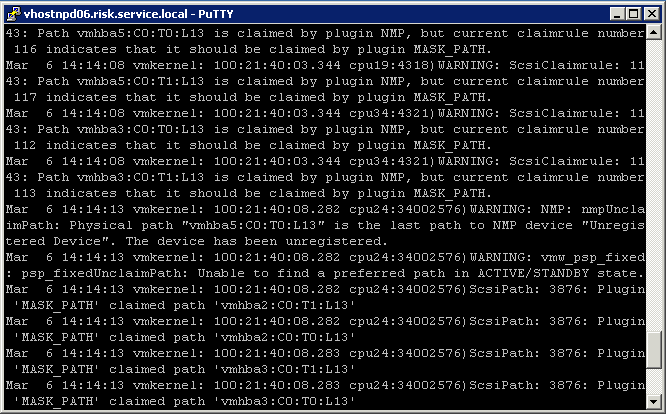
- Refresh the Datastore and you should see it vanish from the host view
- Run the following command to check it now shows no paths
- esxcfg-mpath -L | grep naa.60050768028080befc00000000000050 again will now show no paths
Step 8
- Now get your Storage Team to remove the LUN from the SAN
Step 9
- Rescan all hosts and make sure the Datastore has gone
Step 10
- To restore normal claimrules, perform these steps for every host that had visibility to the LUN, or from all hosts on which you created rules earlier:
- Run esxcli corestorage claimrule load
- Run esxcli corestorage claimrule list
- Note that you do not see/should not see the rules that you created earlier.
- Perform a rescan on all ESX hosts that had visibility to the LUN. If all of the hosts are in a cluster, right-click the cluster and click Rescan for Datastores. Previously masked LUNs should now be accessible to the ESX hosts
Step 11
- Next you may have to follow the following KB Article if you find you have these messages in the logs or you cannot add new LUNs
- Run the following commands on all HBA Adapters
Useful Video of LUN Masking
http://www.youtube.com/watch?feature=player_embedded&v=pyNZkZmTKQQ
Useful VMware Docs (ESXi4)
Useful VMware Doc (ESXi5)